해당 논문은 semantic segmentation 방법론이지만 제가 작성하는 논문의 방향과 유사하다고 판단을 하여 리뷰를 하게 되었습니다.
Abstract
semantic segmentation 성능이 꾸준히 발전되어왔으나 (때로는 한 영상에 1시간 이상의 시간이 걸리기도 하는)라벨 생성 비용해 의해 발전이 제한되어왔다. 이러한 이유로 준지도학습방법이 연구되었다. 핵심은 준지도 기반의 분류에 사용되는 데이터 증강 기법이 segmentation에서 덜 효과적이라는 것이다. 객체의 경계를 고려하기 위해 레이블이 없는 샘플의 네트워크 예측값을 혼합하여 데이터 증가를 생성하는 ClassMix라는 기법을 제안한다.
증강 기법을 두 벤치마크에서 평가하여 SOTA를 달성하였으며 다양한 ablation studies를 통해 설계된 결정과 학습 체계를 비교하는 연구를 제공한다.
Introduction
semantic segmentation은 픽셀 단위의 라벨을 할당하는 것이다. 이는 자율주행, 영상의학 등의 활용에서 필수적이다. fully convolutional network 기반의 방법론을 통해 상당한 발전이 있었으나 GT의 부족으로 인해 한계가 있었다. 하지만 unlabeled 데이터의 경우대부분 풍부하므로 이를 효과적으로 활용한다면 낮은 비용으로 성능을 향상시킬 수 있다.
consistency regularization 기반의 준지도학습 방식이 영상 분류에서 상당한 발전을 가져왔으나 일반적으로 영상 분류에서 사용되는 데이터 증강 기법은 영상분할에서 효과가 없는 것이 입증되었다.
본 논문에서는 분할 기반의 데이터 증강기법인 ClassMix를 제안하고 준지도학습에 사용할 수 있는 방법을 설명한다.이미지에서 예측된 클래스의 절반을 잘라 다른 이미지에 붙여 경계를 더 잘 고려하며 GT 없이 사용할 수 있다. 이는 네트워크가 segmentation map을 예측하도록 학습되며 혼합 영상에 대한 예측은 이전의 혼합에서 학습되었다.
최신 SOTA 방법론의 추세를 따라 entropy minimization도 추가하여 네트워크가 unlabeled 데이터에 대해 낮은 엔트로피로 예측을 하도록 한다. 이를 위해 pseudo label을 이용하여 ClassMix와 결합하였다.
contribution
- ClassMix라 부르는 semantic segmentation에 대한 참신한 증강 전략 도입
- consistency regularization과 pseudo label을 사용하는 통합 프레임워크에서 ClassMix를 도입
- Cityscapes데이터셋에서 SOTA를 달성하고 Pascal VOC데이터셋에서 경쟁력있는 결과를 달성
Method
의미론적 영상 분할에서 준지도학습 방식을 설명한다.
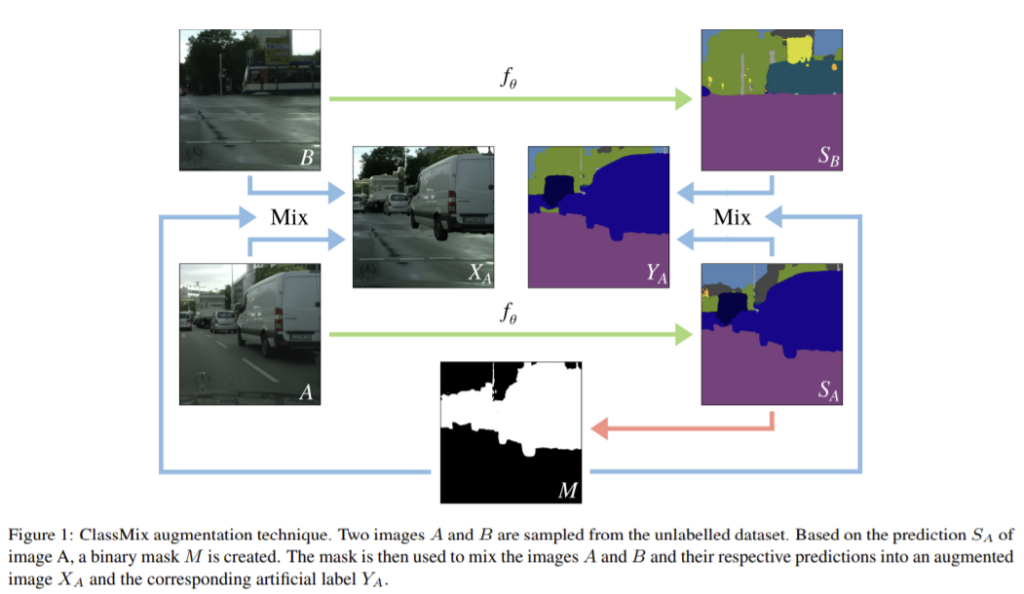
1. ClassMix: Main Idea
준지도학습의 semantic segmentation에서 ClassMix라는 데이터 증강 기법을 제안하며 이를 통해 레이블이 없는 데이터를 이용하여 새로운 이미지와 해당 “artifical label”(인공라벨)을 합성한다. ClassMix는 레이블이 없는두 이미지를 입력으로 하여 그에 상응하는 인공 라벨과 함께 두 이미지가 합쳐진 새로운 증강 이미지를 출력한다. 그림1이 작동 방식으로 레이블이 없는 두 영상 A,B가 합쳐져 영상 X_{A}가 생성된다. 이때 두 이미지 모두 영상분할 네트워크인f_{θ}를 통해 예측 결과S_{A}와 S_{B}를 공급한다. M은 S_{A}의 argmax된 예측값의 절반을 임의로 골라 1로 나머지는 0으로 표시한 이진 마스크로 M이 1인 곳은 A, 0인곳은B의 영상과 인공라벨을 넣어 X_{A}와 Y_{A}를 생성한다. 이때 혼합 방식에 의해 artifact가 나타날 수 있지만 학습이 진행될 수록 artifact가 점점 적어진다. 또한 consistency regulation이 불완전한 라벨에서도 좋은 성능을 내는 경향이 있다.

추가적으로 다음 두가지를 이용하였다.
Mean-Teacher framework
예측 안정성을 위해 Mean-Teacher Framework를 이용하였다. A,B에 대한 예측을 진행할 때 f_{θ}대신 f_{θ'} (θ’는 이전의 θ를 통해 지수이동평균된 값)를 이용하였다. 인러한 temporal ensemling을 통해 ClassMix에서 저렴하고 간단하며 안정적인 인공라벨을 제공할 수 있다. f_{θ}는 X_{A}를 예측하는데 사용되며 학습된다.
Pseudo-labeled Output
“argmaxed” 되므로 인공 라벨의 “sharpening”은 pseudo label을 이용하므로 인해 생길 수 있는 라벨 오염을 해결할 수 있다.
Loss and Training
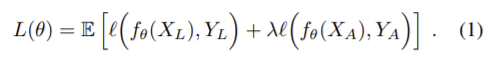
X_{L}은 정답라벨이 있는 이미지, Y_{L}는 그에 해당하는 GT로 loss는 labeled 데이터와 unlabeled 데이터에 대한 semantic segmentation의 cross-entropy loss이다. 학습 초반에는 예측 정확도가 낮으므로 λ를 0에서 시작해 학습을 하면서 네트워크의 정확도가 높아짐에 따라 점점 증가시키는 것이 좋다.
Experiments
Cityscapes
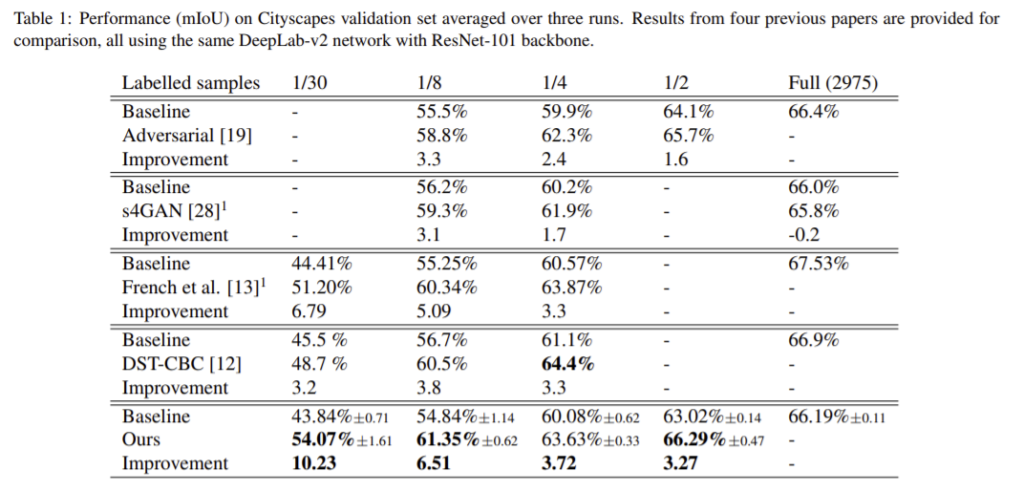

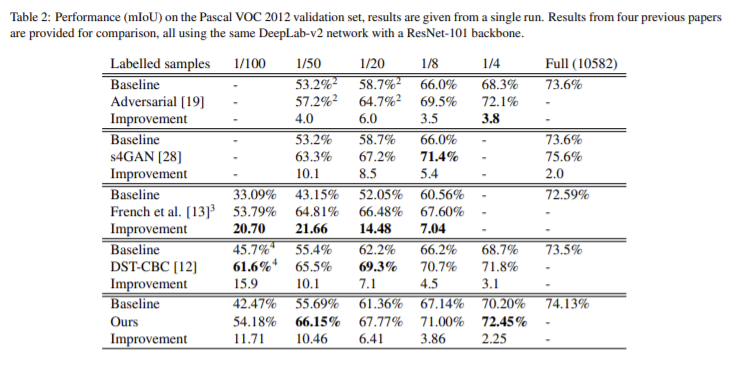
Table1은 동일한 DeepLab-v2 프레임워크를 이용하는 4가지의 방법론에 적용한 결과로 Adversarial[19]와 s4GAN[28]은 적대적 방법론을 French et al.[13]은 consistency regularization을 DST-CBC[12]는 self-training 방식을 이용한다. 실험은 labeled 데이터의 4가지 비율에 따른 결과로 네가지 비율 중 세가지 비율에 해당하는 실험에서 최대의 성능을 얻었고 모든 결과가 베이스라인 성능인 SSL 보다 성능 향상이 있었다. CutMix와 constistency regularization을 사용하는 [13]보다 성능 향상이 있는 것은 CutMix와 다르게 ClassMix의 경우 랜덤으로 객체를 생성하여 이미지를 혼합하므로 다양한 객체와 마스크를 가지는 이미지를 생성할 수 있으므로 마스크의 다양성 때문이라 분석하였다. 또한 경계를 더 잘 고려할 수 있도록 혼합 이미지를 만드므로 더 사실적이며 데이터 분포에 더 비슷하다. 마지막으로 데이터셋 내의 이미지가 유사하기 때문이다. 모든 이미지는 도로와 하늘이 있고 자동차나 사람은 대체로 일정한 위치에 존재한다.(Figure 5) 따라서 혼합된 이미지에서 객체는 대체로 합리적인 맥락에 붙여넣어졌을 가능성이 높다.
Pascal VOC 2012
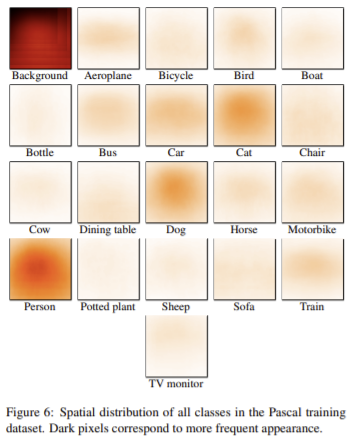
Cityscape와 마찬가지로 4가지 방법론과 비교를 하였고 그 결과 경쟁력 있는 성능을 달성하였고 전체적으로 baseline보다 성능 향상이 있었다. 이때 [13]의 방법론은 MSCOCO에서 사전학습되지 않았으므로 큰 성능 하락이 있다. cityscape에 비해 ClassMix가 강력한 결과를 나타내지 않은 이유를 다음과 같이 분석하였다. 우선 한 영상에 배경과 한두개의 전경을 가지므로 적은 수의 클래스를 포함하기 때문에 마스크의 다양성이 작다. 또한 일정한 위치가 정해져있찌 않으므로 특정 클래스의 객체가 존재하는 위치가 정해져있지 않아 불합리한 맥락에 붙여지는 경우가 발생하기 때문에 성능에 나쁜 영향을 준다. (Figure 6) 그럼에도 SOTA 방법론과 비교했을 때 경쟁력 있는 성능을 가진다.
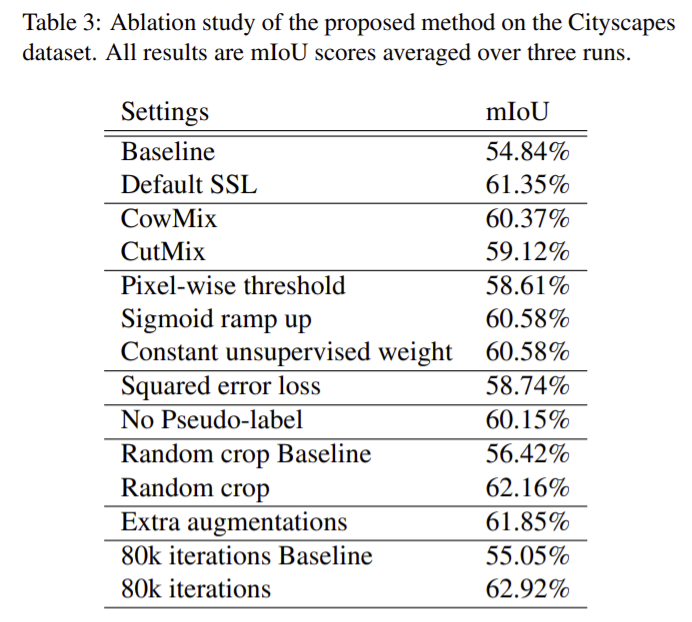
Ablation study
다음은 Ablation study의 결과이다.
제가 작성하고 있는 논문의 방향과 유사한 부분이 많은 논문인 것 같습니다. 설명이 친절하고, 풍부한 실험과 그에 대한 적절한 분석이 들어있었다고 생각합니다. 본 논문을 통해 합성 데이터를 생성할 때 맥락을 고려하는 것이 의미가 있음을 확인할 수 있었습니다.
흠… 컨셉이 저희가 생각한 논문과 유사하네요 ㅋㅋ
몇가지 궁금한 점이 있습니다.
1. “일반적으로 영상 분류에서 사용되는 데이터 증강 기법은 영상분할에서 효과가 없는 것이 입증되었다.” 라고 말씀하셔서, 해당 논문에서는 어떻게 설득했는지 알 수 있을까요? 저희한테도 유리한 내용이 될 것 같습니다.
2. Mean-Teacher framework라면, ema로 Teacher model에게 파라미터를 공유해주는 방식인데, 제가 놓친 거 일 수도 있지만 리뷰 내용과 figure를 보았을 때, 이에 해당하는 내용이 없는 것으로 보았습니다. ema를 사용 안하는 건가요??
1. 다른 논문을 인용하여 분류에서 사용되는 데이터 증강 기법은 영상분할에서 효과가 없다는 것을 입증하였습니다. 따라서 저희도 해당 논문을 활용하면 좋을 것 같습니다.
2. EMA 를 이용하였다고 적혀있습니다. f_θ 가 아닌 f_θ’을 이용하였다고 하는 데 그림에서는 붙여넣는 방식만 간단하게 설명하려고 f_θ라고 표현한 것 같습니다. pseudo code에는 f_θ’라 적혀있고 이전에 혼합하여 생성한 이미지에 대해 학습한 네트워크라고 설명되어있었습니다.