요약
해당 논문은 2019년 공개되었으며[Link]. batch mode로 작동하는 active learning 기반으로 큰 배치 사이즈에 대응하기 위한 연구이다.
용어 설명
active learning: 이전 X-Review[SRAAL]의 배경 기술 소개 참조.
batch mode active learning: 기존의 active learning 방법론은 주로 하나의 데이터에 대한 가치를 판단하여 쿼리로 요청할 지 여부를 결정하였다. 그러나 해당 과정은 매 iteration마다 사람의 개입이 필요하므로 비효율적이다. batch mode active learning은 batch 단위로 쿼리를 요청하여 기존 방법보다 효율적이다. batch mode로 작동하는 대표적인 active learning 방법론으로는 [1] 이 있다. [1]은 active learning을 core-set 방법의 관점으로 정의하여 진행하였는데 batch mode로 작동할 뿐 만 아니라 기존의 많은 연구처럼 classification task를 기반으로 예측확률을 이용해 데이터의 가치를 평가했던 방식과 달리 다양한 task로 확장가능성을 갖고있어 Discriminative Active Learning(DAL)과 유사하다. 그러나 해당 연구는 DAL에 비해 구현이 직관적이지 않으며 unlabeled data에 대한 확장이 어렵다고 한다.
아이디어
저자의 아이디어는 다음 두가지와 같다.
1) we would like our dataset to represent the true distribution of the data. and the unlabeled pool is large enough to represent the true distribution.
2) 어떤 unlabel data가 모델에 의해 높은 확률로 unlabeled state라고 예측된다면 (labeled data와 다르므로, 모델이 ) 쿼리로 요청해야 한다.
2)의 경우는 적힌 그대로 어떤 데이터를 unlabeled state로 예측했다는것은 모델이 해당 데이터에 대한 정보가 부족함을 의미하며 따라서 쿼리로 요청된다. 1)의 경우는 데이터 셋 구축시의 기본 상식 (구축된 데이터셋이 실제 데이터를 대표한다)을 이용한 것이다. 저자는 labeled data, unlabeled data에 대한 2진 분류문제로 이를 구성하였으며, 이를 통해 2에서 언급한것 처럼 unlabeled state라고 예측한 확률이 높은 데이터를 통해 학습이 필요한 데이터를 선정할 수 있다. 또한 unlabeled state, labeled state라는 state 비교를 통해 궁극적으로 labeled pool이 unlabeled pool(즉, 실제 데이터의 분포)와 유사해지도록 학습한다.
method

DAL의 알고리즘은 위와 같다. 해당 방법론은 Unlabeled state에 있는 데이터를 선별하여 Labeled state로 옮기기 때문에 매 업데이트 과정마다 어노테이션이 필요없다. state 정보만 업데이트 하면 되기 때문이다. 해당 방법론에서는 데이터의 가치를 판단하기 위해 이진분류기의 예측 확률값을 이용한다. 데이터의 분포간의 거리를 이용해 가장 대표가 되는 데이터를 선별하는 [1]과 다르게 모델의 확룰을 사용하여 기존 방법론에 있던 sparse 영역에 대한 over represent 문제를 해결하였다. 여기서 over represent 문제란 다음과 같다. 데이터 사이의 거리를 이용하는 [1]은 데이터 밀집도가 낮은 영역에 대해서도 영역을 커버하는 대표 데이터를 선별한다. 이때 밀집도에 관계없이 선별이 진행되어 over represent문제가 발생한다. DAL은 이와 다르게 모델의 예측 확률값을 이용하여 unlabeled state라고 강하게 예측되는 x를 쿼리 데이터로 선정한다.
실험
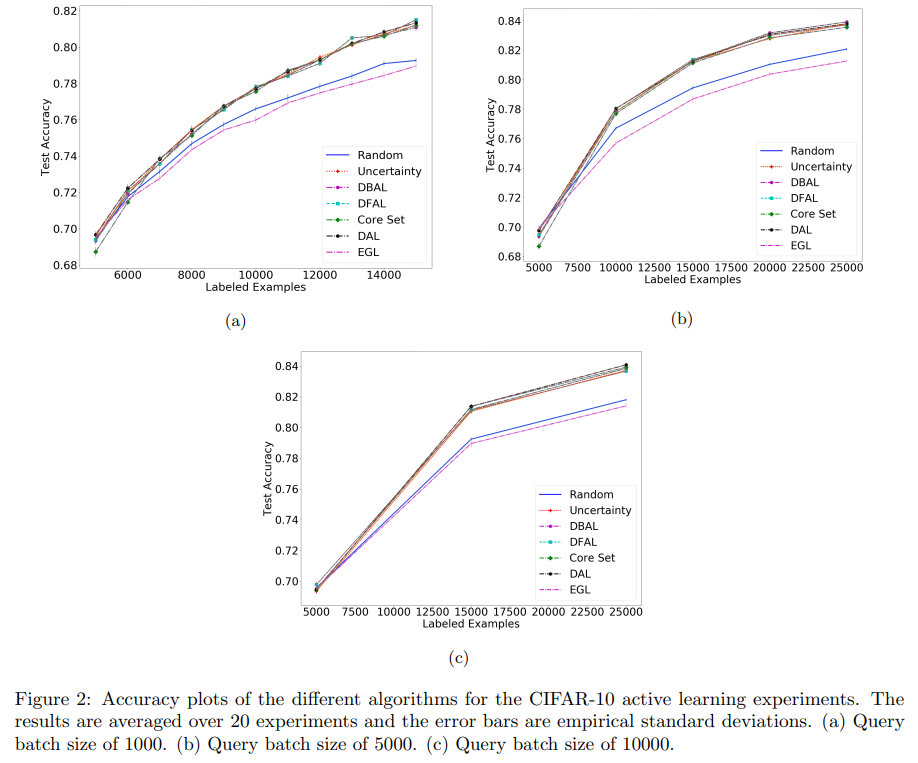
실험은 MNIST와 CIFAR-10에 대해 진행되었으며 그림2는 CIFAR-10에 대한 실험 결과이다. (a), (b), (c)로 진행할수록 쿼리의 batch size가 증가하며 모든 방법론이 random 방법론보다는 안정적인 성능을 보인다.
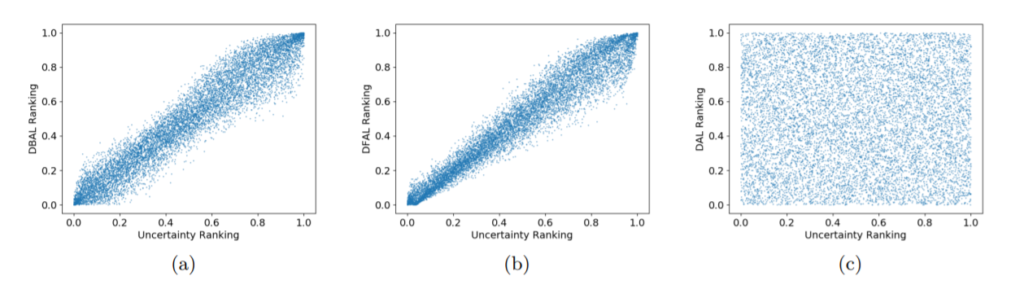
그림3은 기존 방법론인 DBAL[2], DFAL[3]과 DAL을 비교한 실험결과이다. 각 그래프의 x축은 uncertainty ranking이다. 기존 방법론인 DBAL과 DFAL은 uncertainty 기반의 방식과 상관관계가 매우 큰 것에 비해 DAL은 상관관계가 전혀없는 새로운 방식임을 알 수 있다.
참조
[1] Sener, Ozan, and Silvio Savarese. “Active learning for convolutional neural networks: A core-set approach.” arXiv preprint arXiv:1708.00489 (2017).
[2] Gal, Y., Islam, R., and Ghahramani, Z. Deep bayesian active learning with image data. arXiv preprint arXiv:1703.02910, 2017.
[3] Ducoffe, M. and Precioso, F. Adversarial active learning for deep networks: a margin based approach. arXiv preprint arXiv:1802.09841, 2018.
마침
해당 논문은 active learning에 대한 다각도의 이론적 분석을 진행하였다. open review에서 확인할수있듯 실험 부분에서 아쉬움이 있으나, 다각도에서 접근하는 점이 신선하고 논문 설명이 친절했다.
좋은 리뷰 감사합니다.
정리하자면 본 방법론은 Diversity 기반인데, over-representation되지 않도록 가능한 실제 분포를 반영하는 데이터셋 선별에 집중한 것 같습니다. 그리고 데이터셋 선별을 위해 “Labeled” 인지 “Unlabeled” 인지 이진 분류 문제로 전환한 것이 맞나요?
다만 제가 헷갈리는 것은 본문에서 “Unlabeled state에 있는 데이터를 선별하여 Labeled state로 옮기기 때문에 매 업데이트 과정마다 어노테이션이 필요없다.” 라고 하셨는데 그렇다면 U를 L로 Domain Adaptation을 수행하여 L인지 아닌지를 예측하는 문제인 것인가요?
(만일 그렇다면.. 아이디어가 아주 좋네요…. )
안녕하세요 유진님 좋은 리뷰 감사합니다!!
글을 읽다보니 labeled pool이 unlabeled pool과 유사해지도록 학습한다는 측면에서 gan의 방식과 상당히 유사하다는 생각이듭니다. 논문에서 제시된 방법은 최종적으로는 ‘초기 unlabel pool의 분포’에 맞게 labeled pool을 확장시키는 방법론이고, unlabel pool에서 선정되는 샘플은 lableled set과 차이가 나면서 정보량이 많은 데이터를 선별하는 것 같습니다. 저 또한 Unlabeled state에 있는 데이터를 선별하여 Labeled state로 옮기기는 과정에서 헷갈리는 부분이 있었는데 이진 분류기를 통해 L의 state로 분류된 데이터도 이후에 라벨링이 될 것 같은데 이는 labeled pool의 대표점 중에서 가장 가까운 점으로 배정이되면서 라벨링 되는 건가요??