
이번 논문은 Monodepth1&2를 제안한 Godard의 새로운 Depth 논문입니다. 데이터 셋의 부족을 해결하고자 Self-supervised learning 방식으로 논문들을 작성하더니 이제는 비디오 프레임을 입력으로 활용하여 깊이 추정을 하는 방법론을 제안합니다. 점점 더 실용적이고 현실적인 방향으로 논문을 제안하는 Godard를 응원하며 리뷰 시작하도록 하겠습니다.
Abstract
앞서 초록과 서론을 요약하면 다음과 같습니다.
- 그동안에 Self-supervised monocular depth estimation networks들은 대부분 아주 인접한 프레임을 사용하여 학습 후 한 프레임에 대해서 평가한다.
- 하지만 현실적으로 대부분의 깊이 추정 네트워크를 필요로 하는 application들은 비디오 프레임을 주로 입력으로 받는다.
- 그래서 저자는 sequence information을 사용할 수 있을 때 능동적으로 사용하여 촘촘한 깊이 맵을 생성할 수 있는 ManyDepth라는 방법론을 제안한다.
- ManyDepth는 크게 end-to-end 방식의 cost volume을 활용하며 추가로 카메라가 정적인 상태이거나 움직이는 물체 등 학습 가정을 깨트리는 상황들에 대해 cost volume을 무시하는 consistency loss를 제안한다.
Problem Setup
해당 섹션에서는 본격적인 방법론 설명에 들어가기 앞서 해당 방법론의 전반적인 학습 및 평가 과정에 대해 설명합니다.
일단적인 Single Image Depth Estimation을 수식1, 이라고 한다면 해당 방법론과 같이 Multi Frame을 활용하는 깊이 추정 방법론은 수식2처럼 표현할 수 있습니다.
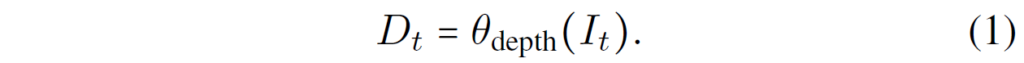
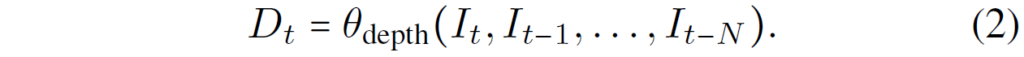
\theta_{depth} 는 Depth Network를 의미하고 I_{t} 는 t프레임의 이미지를 의미합니다. 여기서 저자가 한가지 강조하는 점은 기존의 Multi-frame 방법론들과 달리 ManyDepth는 online application에서 미래 frame, 즉 I_{t+1}를 사용하지 못하기 때문에 입력으로 현재 프레임과 과거 프레임만 사용한다고 합니다.
그 외에 추가적인 차별점으로는 ManyDepth의 경우 Multi-frame을 사용할 수 있을 경우에만 Multi-frame으로 사용할 수 있는 것이지 반드시 input이 Multi-frame이 들어올 필요는 없다고 합니다. 즉 Single frame 만으로도 평가가 된다는 것이죠.
그리고 그 외에 multi-frame을 평가에도 사용하다보니 pose-network가 train 뿐만 아니라 test에도 사용된다는 점이며 또한 moving object 등을 제거해주는 mask로 추가적인 semantic mask를 사용하지 않는다고 봐서는 기존 monodepth2와 동일하게 auto-masking을 사용하는 듯 합니다.
Self-supervised monocular Depth Estimation
다음은 인접한 프레임을 이용한 Self-supervised learning 방식에 대한 설명입니다. 사실 이부분은 앞전에 저와 한대찬 연구원이 작성한 Depth 논문들에서 반복적으로 설명했기 때문에 수식과 용어 정의만 하고 넘어가도록 하겠습니다. (잘 모르시는 분들은 monodepth2 논문을 참고하세요.)
Self-supervised learning은 pose network에서 예측한 두 프레임간에 상대적인 카메라 포즈 T_{t \rightarrow t+n}과 t프레임 깊이 맵 D_{t}를 통해 t+n frame 영상을 t frame으로 warping하여 진행되며 이는 아래 수식과 같습니다. (참고로 n은 [-1, +1] 값)
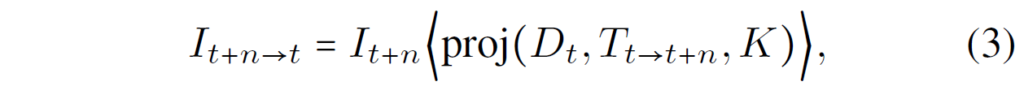
그리고 앞, 뒤 frame을 현재 프레임으로 warping할 때 둘 중 한 곳에 occlusion이 발생하여 현재 프레임과 비교가 직접적으로 불가능한 경우를 대비해 두 frame에서 계산한 loss 중 가장 최소값을 사용하는 min loss 방식을 적용합니다.
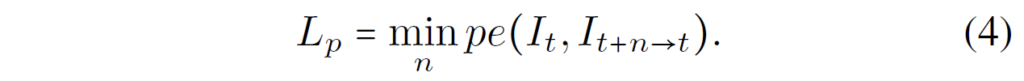
이 photometric loss (pe)는 SSIM과 L1 loss가 포함되어 있습니다.
Building a cost volume
자 그러면 본격적으로 multi-frame을 입력으로 하기 위한 cost volume에 대해서 알아봅시다.
Cost volume의 역할은 I_{t}에서의 깊이 결과와 해당 영상과 인접한 영상들의 깊이 값들이 얼마나 차이가 나는지에 대하여 geometric compatibility를 잘 측정하는 것입니다. 이를 위해서는 pose network를 통해 추출한 각 프레임 간에 대한 상대적인 camera pose T가 필요하게 됩니다.
이제 Cost volume이 어떻게 적용되는지에 대한 수학적 개념?에 대해서 다뤄볼텐데 사실 저도 multi-frame을 입력으로 사용하는 방법론은 처음인지라 기하학적인 개념으로 확 와닿지는 않네요. 그래도 일단 논문에서 말하는 것을 정리해보도록 하겠습니다.
먼저 순서가 있는 평면들의 집합을 \mathcal{P}라고 정의하겠습니다. 이 각각의 평면들(planes)는 I_{t}의 optical axis와 각각 수직을 이루고 있으며 깊이 값의 최소 최대 d_min, d_max 사이로 선형적으로 간격을 이루고 있습니다.
각각의 프레임은 인코더를 타고 나와 deep feature map F_{t}로 추출되며 이를 기존의 self-supervised learning 방식과 동일하게 카메라 내부 파라미터, 외부 파라미터, 추정된 깊이 값을 통해 I_{t}으로 warping하게 됩니다. 즉 기존의 Self-supervised 방식들은 이미지를 warping했다면 여기서는 feature map을 warping하는 것이죠.
최종적으로 cost volume이라는 것은 warping된 feature와 실제 target frame image I_{t}의 feature 간에 ABS Error를 계산하여 설계하게 됩니다. 다시 정리하자면 t-1~ t-N 프레임의 image를 encoder에 태워서 feature를 생성하구 이를 t frame으로 warping하여 t프레임의 feature와 Abs error를 계산하여 에러 맵을 시간축으로 쌓으면 이것이 cost volume이 된다 이말입니다.
아직 이해가 어려우신 분들은 그림1번을 보시면 쉽게 이해가 되실 겁니다.
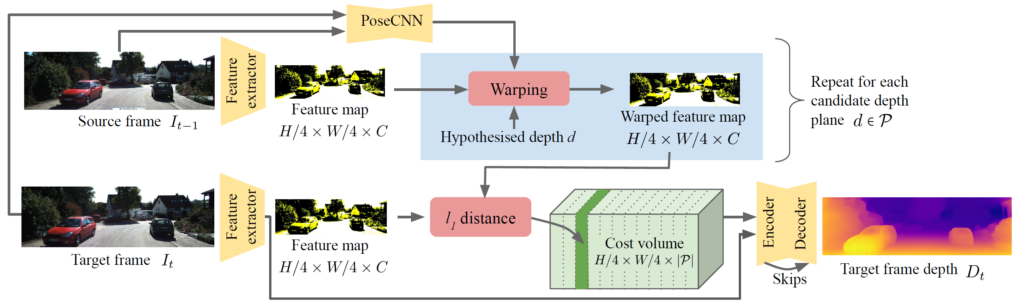
위에서 설명한 내용 그대로 Feature extractor를 통해 각 프레임별로 feature map을 추출한 후 source frames feature들을 target으로 warping하여 error를 계산합니다. 이렇게 계산된 error들은 하나씩 하나씩 시간축으로 concatenate하여 cost volume을 생성 후 다시 Encoder-Decoder 구조의 네트워크에 태워서 최종적인 Target Frame의 Depth를 생성하게 되는 것이죠.
이러한 cost volume은 네트워크가 다양한 뷰의 영상들을 입력으로 활용하여 더더욱 네트워크가 깊이를 잘 추정할 수 있도록 해줍니다.
하지만 이것들은 d_{min}, d_{max}에 대하여 하이퍼파라미터 값으로 설정을 해줘야 하며, 또한 이러한 cost volume을 계산하는 과정은 카메라가 포착한 모든 것들이 정적이라는 가정이 있기 때문에 학습에 제약이 존재합니다.
ManyDepth에서는 이러한 문제를 해결하고자 먼저 Adaptive cost volume이라는 것을 제안합니다.
Adaptive cost volumes
기존의 cost volume을 사용하는 방법론들은 데이터 셋에서 이미 사전에 확인하여 d_{min}, d_{max} 값을 설정하거나, 또는 camera pose 값을 이미 알고 있는 상태였기 때문에 크게 문제가 되지 않습니다.
하지만 비디오 프레임만 떡하니 있고 그 외에 아무 정보도 없는 진정한 self-supervised depth estimation의 경우에서는 cost volume을 사용하게 될 경우 scaling-factor를 알지 못하여 실제 real-world와의 깊이 값과는 전혀 다른 깊이 맵을 추론하게 됩니다.
이 문제를 해결하고자, 저자는 adaptive cost volume을 제안합니다. 해당 방식은 네트워크가 학습하는 동안 스스로 scaling을 찾음으로써 d_{min}, d_{max}를 학습하는 것입니다.
먼저 D_{t} 의 네트워크로부터 현재 예측한 값을 이용하여 학습 배치 너머로 각각의 D_{t} 의 최소, 최대 값의 평균을 계산합니다. 그리고 이 평균값들은 exponential moving average estimation을 통해 업데이트가 됩니다.
이 d_{min}, d_{max}들은 모델의 weight와 함께 세이브가 되며 평가 때 고정이 되어 사용된다고 합니다.
Addressing cost volume overfitting
저자는 cost volume을 활용한 monocular depth estimation model에서 움직이는 물체 등에 대해서 large hole이 발생하는 현상을 관측했습니다. 기존의 단일 프레임을 활용하는 방법론들도 그러지 않았나? 싶지만, cost volume을 활용한 방법론은 그 빈도나 정도가 그림2-(c)와 같이 심한 것을 확인할 수 있습니다.

그렇다면 왜 monocular-trained cost volume은 안되는 것 일까요? 저자는 이론적으로만 봤을 때 자신들이 제안하는 방법론은 매우 잘 동작해야 한다고 확신합니다.
왜냐하면 모델 학습에 사용하는 photometric loss는 SOTA single-image monocular depth estimation 방법론들에서도 사용 중인 검증된 학습 방식이며, 더군다나 cost volume model의 경우 multi-frame을 사용하기 때문에 더더욱 활용할 정보가 풍부하니 더 잘될 수 밖에 없다는 것이죠.
하지만 이러한 photometric loss는 아쉽게도 큰 문제점이 하나 있는데 이는 바로 texture가 풍부한 정적인 물체 또는 장면에 대해서만 매우 효율적으로 동작한다는 점이죠.
예를 들어보겠습니다. 그림2-(a)의 경우 1프레임씩 인접한 프레임인데 가만보면 앞뒤 프레임에도 불구하고 차들의 픽셀 좌표 상 위치가 매우 동일한 것을 볼 수 있습니다. 이는 카메라가 부착된 차와 앞에 차들이 동일한 속도로 가고 있기 때문에 그런 것이겠죠.
하지만 위에서도 설명했다시피 self-supervised learning에서 가장 큰 학습 가정은 카메라는 움직이고 촬영되는 대상은 멈춰야만 합니다. 이 가정이 어긋나거나 또는 textureless한 영역에 대해서는 photometric loss가 정확하게 에러를 측정하지 못하죠.
즉 인접한 프레임을 warping하여 feature map끼리 비교한 error 값으로 구성된 cost volume한테 저렇게 학습 가정을 깨트리는 case들이 포함된다는 것은 cost volume의 신뢰성을 크게 저하시키고 결국 depth를 추정하기 위한 입력 자체에 심한 노이즈가 발생하게 됩니다.
여기서 Depth network들이 알아서 가정을 깨트리는 영역들에 대한 cost volume을 무시하면 좋을 것만, 불행히도 네트워크는 cost volume에 대해 너무 의존성이 높게 가진 체로 깊이 맵을 생성하기 때문에 에러가 심하게 발생합니다.
그래서 저자는 학습하는 과정 동안에 이러한 신뢰성 없는 영역을 무시하며 학습하는 방법을 제안합니다. 이를 설명하기 앞서 논문 자체가 바로 방법론으로 안넘어가고 사전지식과 문제 원인을 이야기하는데에도 크게 비중을 다루다보니 리뷰 자체가 지루해지는 것 같아서 이에 대한 내용은 2편으로 나누어 설명하도록 하겠습니다ㅎㅎ..
2편은 언제 나오나요…? 기대중