

이번에 리뷰할 논문은 video 관련 여러 downstream task에 적용가능한 backbone network의 self-supervision 학습 방식을 다룬 논문 입니다. 현재 arXiv에 preprint로 공개되어 있지만, 논문 형식이나 기간을 보아하니 CVPR 2022에 제출되어 리뷰 중인 paper인듯 합니다.
이전에 self-supervised video representation을 다룬 논문들은 주로 clip-level의 contrastive learning을 활용하였습니다. 그러나, 주로 짧은 길이의 clip을 사용하였기 때문에 video 전체를 아우르는 global context를 표현하는데에 제약이 있었고, 본 논문은 이를 해결하고자 video-level contrastive learning framework 줄여서 VCLR을 제안하였습니다.
1. Methods
1.1 Preliminary
제안된 방법을 설명드리기 앞서 self-supervised video representation은 image domain에서 사용하던 기법을 응용해왔기에 그 컨셉에 대해 간단하게 설명하고자 합니다. 논문에서는 MoCoV2를 예시로 다룹니다.
주어진 image set에서 하나의 샘플 anchor를 선택하고, 이를 augmentation하여 positive를 생성합니다. 그리고 나머지 image set에서 N개의 negative 샘플을 선택합니다. 이후 이들을 각각 encoder(backbone network)와 MLP로 구성된 모델에 입력으로 주는데, 이때 사용되는 모델은 query encoder(+query MLP)와 key encoder(+key MLP) 두 가지로 구성됩니다. 좀더 자세하게 설명드리자면, anchor는 query encoder로 positive와 negative는 key encoder의 입력으로 주어져 각각 q, p, n의 feature로 embedding 됩니다. 이 세 가지의 feature로 식 (1)과 같이 InfoNCE loss가 설계되어지며, embedding space 내에서 유사한 feature 간의 거리는 가깝게 다른 feature 간의 거리는 멀어지게 하도록 optimizing 합니다.
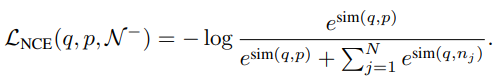
이와 같은 과정을 video domain에 적용하기 위한 다른 방법론 SeCo는 inter-frame과 intra-frame 간의 instance discrimination을 설계하여 positive와 negative를 선정하였으며, SOTA의 성능을 보여주었습니다. 본 논문은 이 SeCo라는 방법론을 baseline으로 설계되었기 때문에, SeCo의 핵심인 intra-frame, inter-frame instance discrimination에 대해 설명드리고 넘어가겠습니다.
SeCo에서 inter-frame instance discrimination의 목적은 frame-level에서 contrastive learning 하는 것입니다. 이를 위해 우선, 한 비디오에서 세 개의 frame v_1, v_2, v_3 를 랜덤으로 선택합니다. 이때 v_1을 anchor v_1^a로 두고, 여기에 다른 augmentation을 적용한 v_1^+와 나머지 v_2, v_3를 positive로 둡니다. 그리고 데이터 셋 내의 다른 비디오에서 N개의 negative 샘플을 선택합니다. 이렇게 설정된 frame들을 각각 query encoder와 key encoder에 태워 embedding (q, p, N)하며, 식 (2)처럼 설계되어 optimizing 됩니다. 여기서 식 (2)는 세 개의 positive 가 각각 하나씩 anchor 및 N개의 negative와 쌍을 이루어 연산되고 평균을 낸 형태입니다.
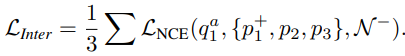
SeCo에서 intra-frame instance discrimination은 보다 좁은 범위에서 positive를 선택합니다. 이전 선택했던 positive들 중 anchor에 augmentation을 적용한 v_1^+ 만을 positive로 두고, 나머지 v_2, v_3를 negative로 두어 식 (3)의 형태로 optimizing 됩니다.
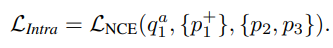
SeCo는 위 두 가지 방식으로 현재 self-supervised video representation에서 SOTA로 자리잡고 있지만, 오직 frame-level에서의 contrastive learning 만을 다루고 있습니다. 이로 인해 temporal cue에 따른 semantic information을 알아내기 힘들게 됩니다. 본 논문은 앞서 이러한 SeCo를 baseline으로 video-level의 global context를 추가하여, semantic information을 발굴해내고자 합니다.
1.2 Video-level contrastive learning
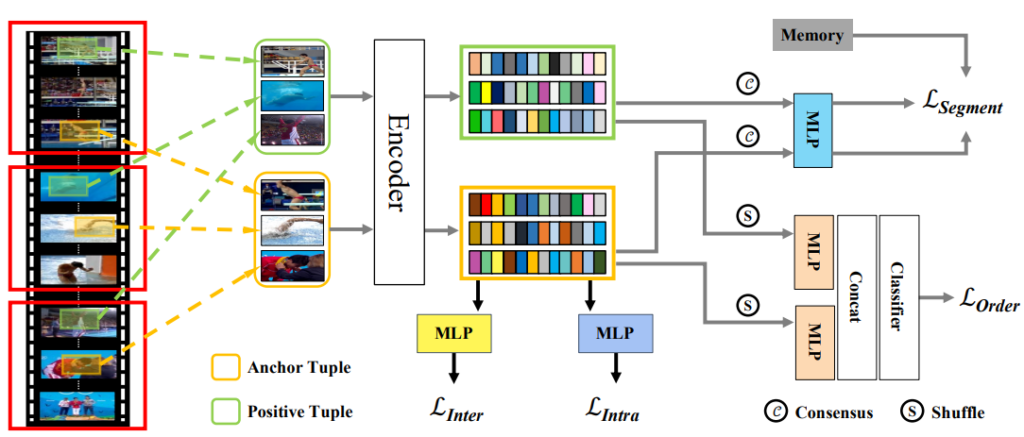
Video-level의 contrastive learning을 위해 우선 한 비디오를 K 개의 segment로 분할합니다. 여기에 각 segment 마다 random으로 frame을 선택하여 anchor tuple을 선택하고, 한번 더 독립적으로 random 샘플링하여 positive tuple을 선택합니다. 이 두 개의 tuple은 각각 하나의 비디오를 다른 viewpoint에서 바라본 것과 같기에 두 tuple 간 consensus 기반의 contrastive learning이 진행됩니다. 이는 식 (4)와 같으며 위 첨자 a는 anchor tuple에 속한 frame, 위 첨자 +는 positive tuple에 속한 frame 그리고 C는 consensus 함수로, 평균을 사용하였다고합니다. 식 (4)가 의미하는 바는, 각 anchor tuple과 positive tuple을 프레임 단위로 encoder를 태운 뒤 (query encoder: f_q, key encoder: f_k), 같은 tuple 별로 평균을 취하여 tuple 별 consensus를 계산하고, MLP를 태워 embedding된 q_t^a, p_t^+를 구한다는 것 입니다. 그 외에 다른 비디오에서 총 N 개의 tuple을 생성하여 같은 방식으로 negative tuple을 embedding하고, 식 (5)와 같이 설계되어 optimizing 됩니다.
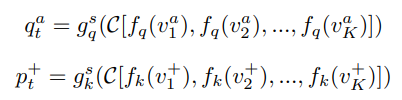
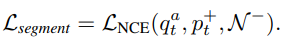
이와 같이 설계된 video-level의 contrastive learning은 비디오 전체를 보기에 학습의 강인성을 확보할 수 있게되며, 비디오 길이 혹은 sample rate에 관계 없이 학습할 수 있게 됩니다. 또한, 저자는 encoder로 2D backbone에만 제한되어 있는 것이 아닌 3D backbone에도 활용할 수 있다고 합니다.
1.3 Temporal order regularization

Video-level의 contrastive learning을 통해 global context를 추가할 수 있었으나, 아직 frame 간의 연속된 정보를 활용하지는 못하고 있습니다. 여기에 sequential structure를 강화하고자 VCLR framework에는 temporal order regularization 또한 적용되었습니다. 이는 앞서 샘플링된 anchor tuple과 positive tuple 내에서 frame의 순서를 맞추는 4-way classification 방식이며, 50 퍼센트의 확률로 각 tuple이 랜덤하게 shuffle되어 총 네 가지 class를 지닙니다. (모두 정상, 둘 중 하나 shuffle, 둘 다 shuffle) 식 (6)에서처럼 앞선 section과 유사하게 tuple 내 각 frame들을 embedding 하되(앞서 사용한 모델과 다른 파라미터) 모두 concat하며, hidden layer를 태워 classification 합니다.
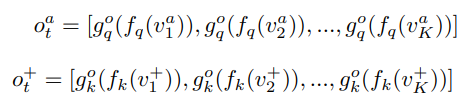
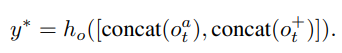
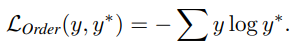
이 방식과 유사하게 프레임 순서를 예측한 다른 방법론이 존재하였으나, 다른 방법론들은 local하게 본 것에 반해 VCLR은 Fig 3처럼 global하게 보았다는 점이 차이가 있다고 합니다. 좀더 자세하게, 만약 local하게 특정 구간 만을 본다면 순서를 예측하기 위한 cue가 부족하지만, global하게 본다면 이러한 모호성을 줄일 수 있게 됩니다.
1.4 Overall framework
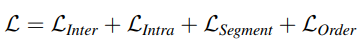
앞서 설명드린 네 가지의 objective를 optimizing 하면서 학습되며, 이와 같은 방식으로 학습된 backbone network를 downstream task에서 활용할 때는 모든 MLP를 제거하여 사용하게 됩니다.
2. Experiments
2.1 Linear evaluation on Kinetics400
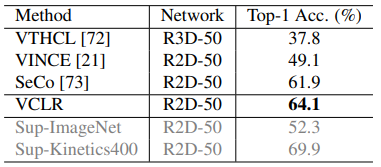
위 방식으로 학습된 feature를 활용한 embedding space에서 classification 하여, 제안된 방식이 self-supervised video representation에 효과적인지 판단할 수 있습니다. 방식으로는 학습된 모델에 Kinetics400 데이터 셋의 한 비디오에서 30 frame 당 한 frame 씩 샘플링하여 embedding하고 이를 평균내어 video-level feature로 생성합니다. 이후, Kinetics400의 train set에서 얻은 video-level feature로 SVM을 학습하고, validation set으로 평가 하였을 때 Table 1과 같이 baseline 이었던 SeCo 를 제치고 SOTA를 달성하게 되었습니다.
2.2 Downstream action classification & action temporal localization
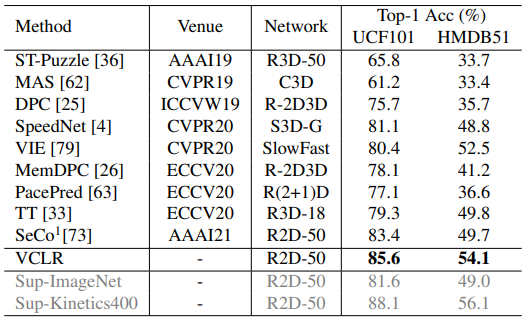
and HMDB51.
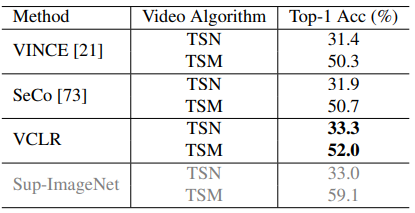
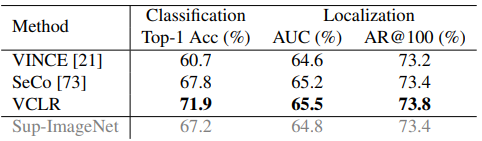
Downstream task로는 우선 action classification으로 선택되었으며, VCLR 방식으로 학습 후 action classification으로 transfer learning하였을 때 여러 종류의 데이터 셋에서 성능을 보였습니다. VCLR 학습을 위한 데이터 셋은 Kinetics400이 사용되었으며, 이와 유사한 scene-centric 데이터 셋 UCF101, HMDB51과 motion-centric 데이터 셋 Something2Something, untrimmed 데이터 셋 ActivityNet에서 action classification 성능을 보였습니다. 또한, ActivityNet에서는 action localization의 성능도 측정했을 때 Table 2, 3, 4에 걸쳐 다양한 task에서 baseline인 SeCo를 넘어 좋은 성능을 보였으며, self-supervision 방식임에도 불구하고 supervision의 성능에 좀더 가까워진 것을 보였습니다.
2.3 Downstream video retrieval
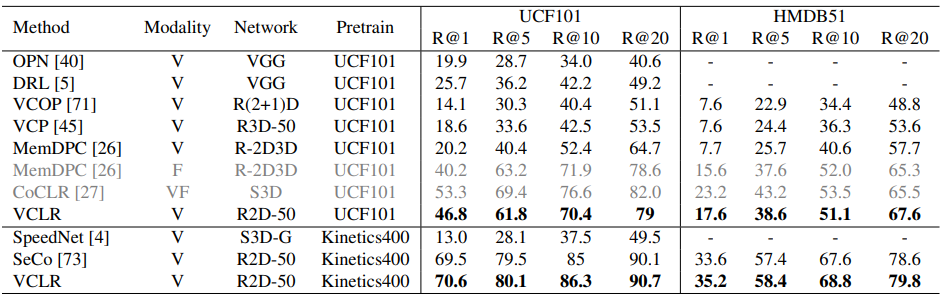
Downstream task인 video retrieval에서도 마찬가지로 baseline인 SeCo 대비 좋은 성능을 보였습니다. 특히, video feature만을 사용하고 UCF101에서 pretraine된 경우, 다른 방법론과의 성능보다 두배 높은 성능을 보였습니다.
2.4 Ablation study on loss objectives
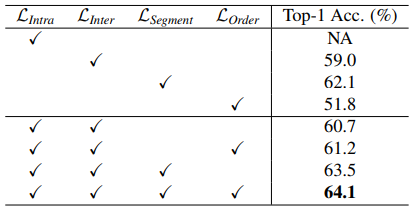
Table 6은 앞서 설계된 네 가지의 objective가 성능에 미치는 영향을 나타낸 것입니다. 그 중 video-level contrastive learning을 위해 설계되었던 objective가 가장 성능을 올리는데 도움을 준 것으로 미루어 보아, global context가 supervision signal에 가장 가깝다는 것을 알 수 있습니다.
Reference
[1] https://arxiv.org/pdf/2108.02722v1.pdf