작성중인 논문이 pseudo label을 이용하는 방식으로 self-training 방법론이라 찾아보게 된 논문입니다.
Astract
CAM을 이용하면 annotation 없이 픽셀 단위의 class값을 알 수 있지만 False Positive 비율이 높아 coarse한 시각화 결과를 산출합니다. 이를 완화하기 위해 학습 중에 픽셀 단위의 주석을 통합하는 active-learning(AL) 프레임 워크를 제안합니다. classification은 지도학습으로 진행하고 segmentation은 AL 방식으로 수행합니다. 기존의 AL은 sample 선택에 초점을 두었다면 해당 방법론은 무작위 샘플을 이용하여 pseudo-segmentation을 통해 레이블이 없는 많은 데이터를 사용합니다.
Introduction
CAM과 Grad-CAM 기반의 방법론을 이용하면 상대적으로 비싸지만 정확한 RoI를 찾지만 의료 이미지인 조직 분석 데이터와 같이 상대적으로 어려운 시나리오에서는 잘 작동하지 않습니다. 또한 CAM의 경우 비지도학습 방식이므로 잘못된 경우에 대해 픽셀 단위의 지도학습을 할 수 없고, 낮은 해상도를 가지기 때문에 복원하려면 interpolation이 필요하다는 한계로 인해 False Positive가 늘어나 실용적이지 못할 수 있다는 것에 주목했습니다. 따라서 class정보가 달린 학습 데이터를 이용하여 픽셀 단위의 주석을 얻었습니다.
또한 1)신뢰할 수 있는 모델을 만들기 위해 많은 데이터가 필요하지만 표준 AL은 일부의 신뢰할 수 있는 쿼리만 제공하고 2)AL 실험이 레이블이 있는 큰 집단을 이용하기 때문에 sample 선택 방식에 대한 연구의 신뢰도가 낮고 학습 초기 단계에서 얻은 sample을 신뢰할 수 있는 쿼리로 이용한다는 것이 일관성이 떨어지며 3) classification과 segmentation의 경꼐는 다르기 때문에 segmentation은 새로운 과제이고 4) 의료 이미지와 같이 이미지 획득 자체가 비싼 경우 휴면 데이터로 데이터를 두는 것은 비효율적이라는 이유로 표준 AL 방식에 제한이 있었습니다. 따라서 self- learning 방식으로 주석을 생성하였고, 이러한 경우 정확도가 떨어지는 것을 대비하기 위해 몇개의 오라클 주석 샘플을 이용하였습니다.
해당 논문의 기여는 1) 분류(ResNet)모델과 분할(U-Net)모델을 함쳐 CAM 보다 정확하고 고해상도의 결과물을 산출하는 구조를 설계하였고 2) 많은 샘플을 self-learning을 기반으로 주석을 생성한 것, 3) 의료 이미지와 새 이미지에서 실험을 수행했습니다.
Proposed approach
Weakly Supervised Learning(WSL) 모델 훈련을 위해 모든 이미지는 분류 라벨이 있고 픽셀단위의 주석은 오라클 쿼리를 통한 학습에서 점차 획득한다. AL 학습은 각 학습 라운드 r마다 전체 n개의 unlabeled, labeled 데이터 샘플로 구성된 학습 데이터 \mathbb{D}라 하고
- unlabeled subset: \mathbb{U} = \left \{ x_i,y_i, -\right \} ^u_{i=1}
- labeled subset: \mathbb{L} = \left \{ x_i,y_i, m_i \right \} ^l_{i=1} * m_i는 픽셀단위의 주석 정보이다.
일 때 초반에는 \mathbb{L}가 비어있다 점차 \mathbb{U}로부터오라클 쿼리를 통해 채워 이미지를 분류하고 segmentation을 할 수 있습니다.
\mathbb{D} = \mathbb{L}_r ∪ \mathbb{U}_r ∪ \mathbb{P}_r 이고, 먼저 \mathbb{U}_r'는 쿼리로 하여 오라클에 의해 label을 생성한 뒤 \mathbb{L}_r에 추가합니다. k-nn을 이용하여 \mathbb{U}_r''을 골라 모델로 pseudo label을 생성하여 \mathbb{P}_r에 추가합니다. 이때 \mathbb{L}_r을 빨리 늘리기 위해 \mathbb{P}_r은 쿼리로 선택되지 않도록 하고, 쿼리로 이요이 된다면 더이상 pseudo label이 아니게 됩니다.
k-nn 방식으로 이미지의 유사도를 측정하기 위해 해당 논문에서는 이미지 내용을 설명하는 색상 분포를 이용하였습니다. 색상 분포가 유사한 동일 class의 표본은 상대적으로 유사한 물체를 포함할 가능성이 높다는 가정이 있어 동일한 class의 샘플 쌍에만 k-nn이 고려됩니다.
매 round 마다 pseudo-labeled sample과 queried를 함께 학습에 사용하고 다음 loss 함수를 이용하여 최적화합니다.
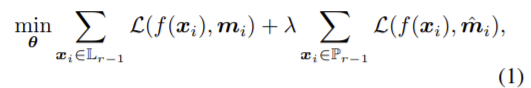
\mathcal{L}는 segmentation loss이고 λ는 양수 스칼라 값입니다. AL에서는 전체 이미지와 픽셀단위에 라벨 수가 불균형을 이루기 때문에 동시에 학습하는 것을 피합니다. 따라서 분류 모델을 먼저 학습한 후 분류 파라미터는 freeze 하고 segmentation을 학습합니다. 다음은 학습 과정을 pseudo code로 나타낸 것입니다.

Result


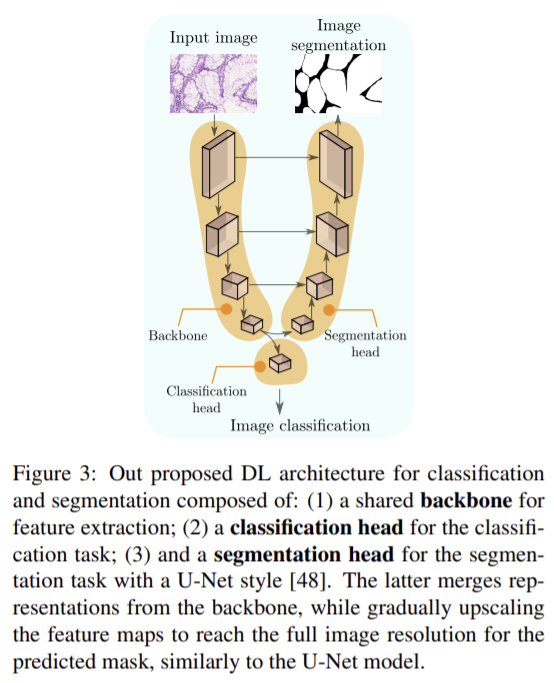
해당 논문의 pseudo label은 그림3의 segmentation head에서 얻어진 것으로 segmentation을 위한 3가지 다른 AL의 선택 방식과 비교됩니다. ( 1_무작위 선택(Random), 2_entropy 기반 선택(Entropy), 3_monte-carlo dropout 불확실성 점수를 이용한 방식(MC_Dropout))
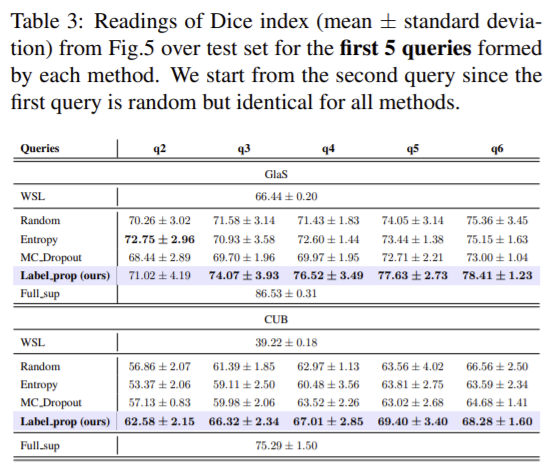
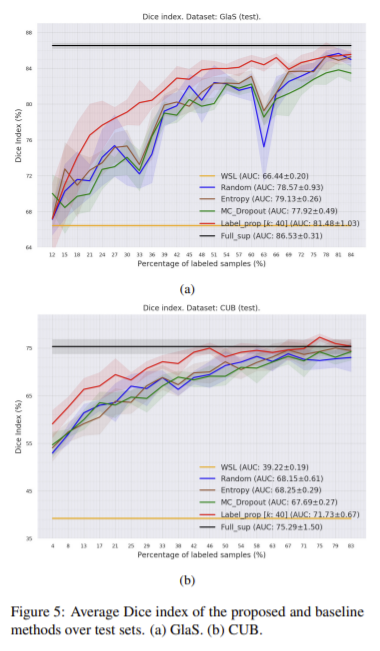
그림5 (a)는 GlaS의 Dice 정확도로 레이블을 더 추가하면 모든 AL 방법이 WSL 방식 보다 높은 성능을 보입니다. 표 3에서 확인할 수 있듯 class당 4개의 데이터만 무작위로 labeling 해주면 WSL을 능가하는 것을 확인할 수 있습니다.
contribution으로 분류 모델과 분할 모델을 함쳐 CAM 보다 정확하고 고해상도의 결과물을 산출하는 구조를 설계한것을 주장했는데 모델에 관한 설명이 조금 부족했던 것 같습니다.
self-learning의 기본적인 내용을 더 공부해봐야 할 것 같습니다..