제가 멀티스펙트럴 영상에서의 Misalignment를 해결하기 위해 한때 Image-to-Image Translation을 사용하였는데, 2020년 CVPR에도 비슷한 내용으로 멀티스펙트럴 영상에서의 Misalignment를 해결한 논문이 있어 리뷰를 작성합니다. 이야기에 앞서 해당 논문의 저자가 공개한 코드에서 GIF를 잘 만들어놓아 해당 GIF를 먼저 공유합니다.

결국 멀티스펙트럴(RGB-Thermal) 영상에서 RGB 영상을 Thermal영상과 얼라인을 맞추고 있습니다. 위의 그림은 학습에 따른 결과를 나타내며, 해당 방법이 저렇게 얼라인을 맞추기위해 제안하는 방법론에 대해서 설명드리겠습니다.
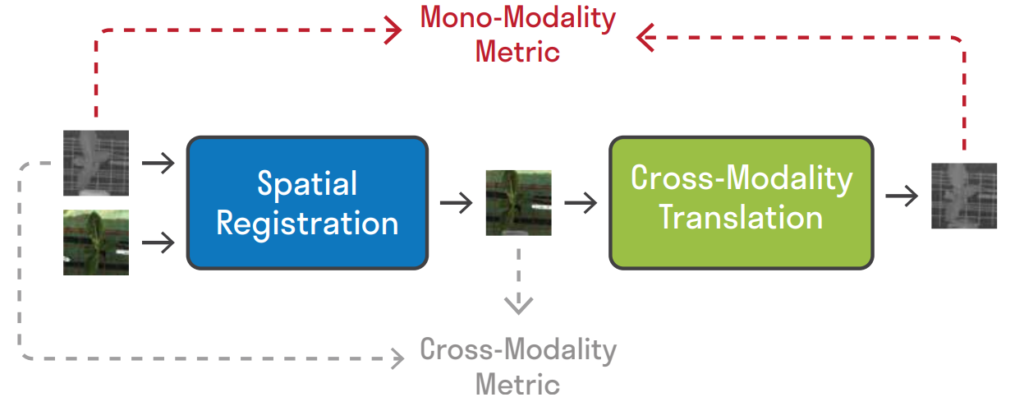
해당 논문에서 제안하는 방법은 정말 간단합니다. ‘Registration Network(Spatial Registration Network)’로 RGB와 Thermal의 얼라인을 맞추고, 이때 얼라인이 맞춰진 RGB를 다시 ‘Geometric Preserving Translation Network(Image-to-Image Translation)’을 통해 열화상 도메인으로 변경하고, 이를 기존 열화상 영상과 비교하여 Loss를 계산하는 방식입니다.
- Registration Network
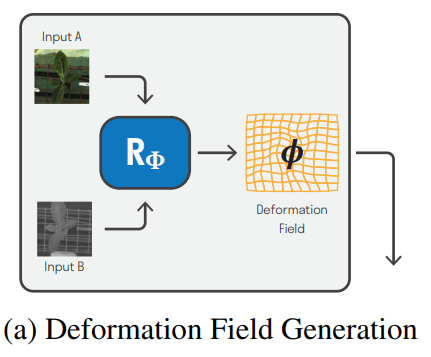
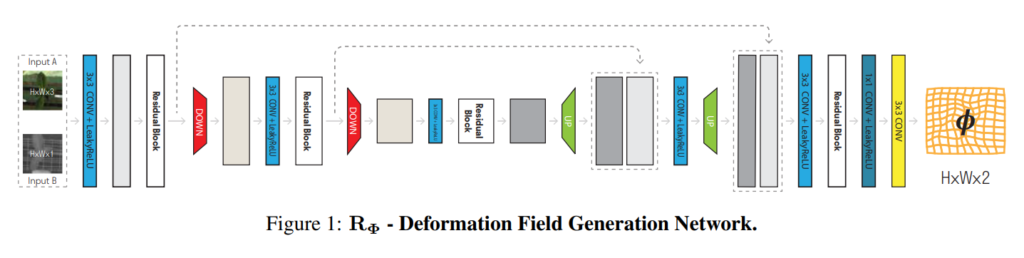
먼저 alignment를 맞추기 위한 Registration Network 입니다. 해당 네트워크의 두 모달리티의 입력이 들어가면, 모델은 deformation field라는 출력을 만들고, 이를 이용하여 두 모달리티 영상의 Registration을 수행합니다. 네트워크는 Deformation Field Generator와 Re-sampling Layer로 구분되는데, Deformation Field Generator가 두 모달리티 이미지를 입력받아 deformation field를 예측하고, 이는 픽셀레벨에서의 deformation(변형) 정보를 의미합니다. 그리고 이러한 deformation field를 이용하여 기존 영상을 변형시키는 레이어는 Re-sampling Layer라고 명명합니다.
그렇다면 해당 네트워크 학습을 위한 Loss는 어떻게 계산할까요? 논문에서는 deformation field에 대한 smooth loss를 다음과 같이 계산하고 있습니다.
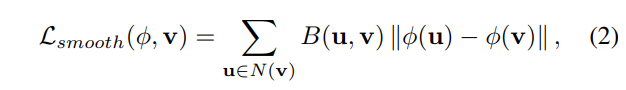
위의 수식에서 v는 (i,j)위치의 픽셀 값을 이야기하며, B는 bilateral filtering을 의미합니다. N(v) (=u) 는 v와 인접한 픽셀을 의미하며 본 논문에서는 3×3 영역에 대해서 비교를 했다고 설명하고 있습니다. 정리하면 smooth loss의 역할은 deformation을 수행할때, 인접하는 픽셀과의 유사도가 유지되는 역할을 수행합니다. 그리고 이때 bilateral filtering의 수식은 아래와 같은데, 이는 인접필셀의 차이가 최소가 되도록하는 smooth loss의 특성상 모든 픽셀값이 0이 될 수 있는데 이를 방지한다고 합니다.
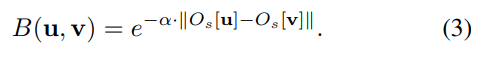
- Geometric Preserving Translation Network
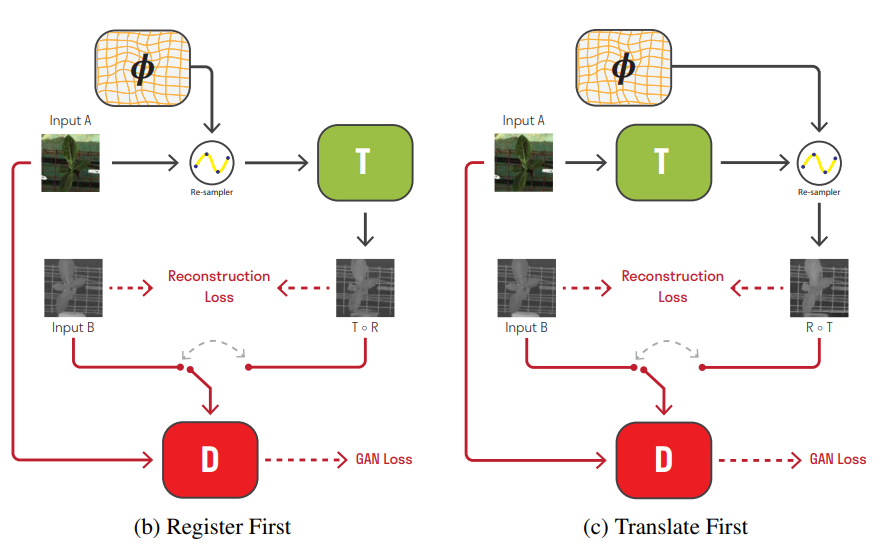
앞서 Deformation field를 만들었다면 RGB(혹은 Thermal)입력을 변형하여 다른 모달리티와 얼라인을 맞춥니다. 변형된 이미지는 다른 모달리티와 얼라인은 맞춘 상태이고, 해당 이미지의 모달리티를 image-to-image translation 네트워크를 이용하여 모달리티도 변경하고, 최종적으로 두 결과값을 비교하여 loss를 계산하는것이 해당 논문의 키 아이디어 입니다. 근데 이때 중요한건 image-to-image translation을 수행할때 geometric 정보도 함께 변형될 수 있으며, geometric 정보가 고정되지 않는다면 앞서 deformation field를 만드는 네트워크의 역할은 무용지물이 됩니다. 본 논문에서는 이러한 문제를 극복할 수 있도록 geometric 정보가 보존되는 translation network를 제안합니다. 해당 방법의 근거는 Translation을 먼저한 결과와 Registration(Deformation field를 구하는 네트워크)를 먼저하는 결과 모두 같아야 한다는 점을 근거로 방법을 제안합니다.


즉 Translation First와 Register First 모두 동일해야하며 위에서는 각각을 수식으로 아래는 그림으로 나타냅니다.
이러한 내용을 근거로 Loss도 설계하고 있는데 이는 reconstruction loss로 아래와 같이 정의됩니다.
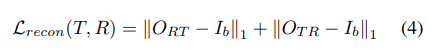
또한 GAN을 사용하는데 GAN에 대한 Loss도 위의 아이디어를 적용하여 Loss를 설계합니다.
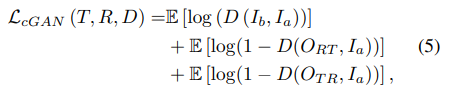
최종적으로 해당 논문에서 제안하는 방법론을 학습하기위한 loss는 아래와 같습니다.

본 논문에서는 실제 Registration의 정확도를 구하기위해서 직접 annotation을 하여 GT를 구했다고 합니다. 이때 데이터셋은 직접 촬영한 데이터셋을 사용합니다. Annotation 방법으로는 아래와 같이 실제 대응되는 포인트를 수동으로 계산함을 의미합니다.
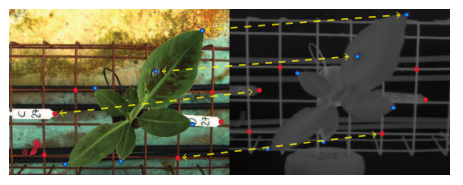
이렇게 수동으로 라벨링한 annotation을 기준으로 registration accuracy라는 평가방법을 제안하였고, 기존 방법론들과 자신들의 방법을 아래와 같이 비교합니다. registration accuracy는 맞춘 정확도라고 생각하여 높은게 좋다고 생각할 수 있지만, 해당 메트릭은 실제 대응되는 포인트의 GT가 있으므로 deformed source points와 대응되는 target points의 Euclidean distance 의 평균값을 의미합니다.
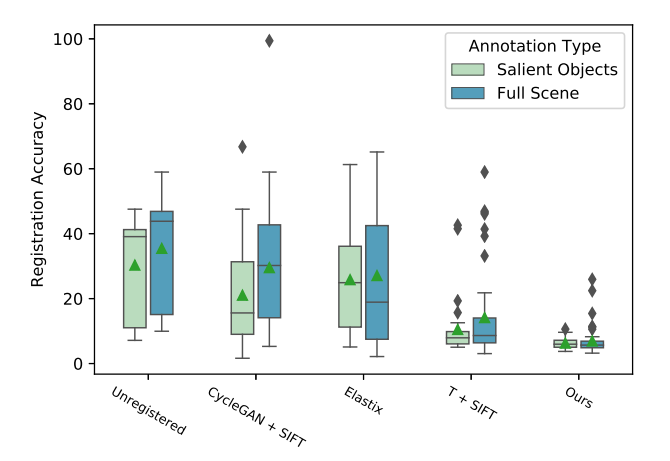
따라서 본 논문에서 제안하는 방법론이 기존 SIFT를 쓰거나 CycleGAN+SIFT 등의 고전방법론보다 더 적은 오차(더 높은 정확도)를 나타냄을 위의 그림을 통해 알 수 있습니다. 해당 연구에서는 RGB-Thermal 뿐만 아니라 RGB-Depth에 대해서도 실험을 수행하였고, 이에 대한 정석적 결과는 아래와 같습니다.

또한 본 논문에서 제안한 Smoothness Regularization에 대한 (앞서 Bilateral filtering 사용한 부분에서 언급) Ablation study도 진행하여 아래와 같이 나타내고 있습니다.
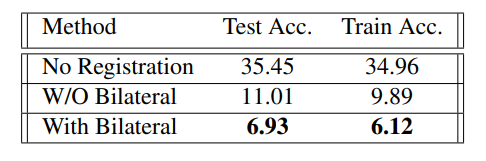
Image-to-Image translation을 이용하여 misalignment 문제를 해결하려고 하였는데, 해당 논문에서 언급된 것과 마찬가지로 다른 모달리티로의 변경을 학습할 때, geometric 정보가 깨지면서 변환되어 제대로 문제를 해결할 수 없었습니다. 해당 논문은 나름 간단한 데이터셋을 이용하여 증명하였지만, 이를 실제 카이스트나 FLIR 데이터셋에서 사용이 가능한지 확인해보고 증명하면 유용한 방법론이 될 것 같습니다. 또한 해당 논문의 저자가 코드도 잘 공개하고 있어 사용해볼 가능성이 높은 논문이라고 판단됩니다.
Image registration을 위한 model과 RGB-to-Thermal translation을 위한 모델을 사용하는 간단하면서도 직관적인 흥미로운 방법이네요.
다만 제 개인적인 생각으로는 처음에 gif에서 보여주는 예시처럼 misalignment문제가 큰 경우에는 득이 될 수 있지만, 그렇지 않은 경우에는 오히려 2개의 과정에서 생긴 error들로 인해 득보단 실이 클 수도 있겠네요.
뭐.. 실험을 해봐야 알겠지만요.
해당 모델에서 최종적으로 사용하는것은 Deformation field generator 입니다. 학습에서 GT가 없으므로 unsupervised학습을 위해 translation 모델을 사용하지만 실제 추론에서는 translation모델은 사용하지 않습니다.
리뷰 잘 읽었습니다.
최종적으로 deformation field 라는 것은 optical flow와 같이 각 픽셀들이 x, y 축으로 얼만큼 이동해야하는지에 대한 2채널 방향 벡터를 의미하는 건가요? 그리고 해당 값을 통해 기존 좌표값들을 shift 시킨 후 이 값들을 sampling operator에 적용하여 registration을 수행하나요?
re-sampler layer라는 말이 리뷰에 명시되어 있는데 설명은 없는 듯 하여 여쭤봅니다.