
해당 논문은 ‘Heng ZHANG‘이라고 Multispectral Pedestrian Detection을 열심히 수행하는 한 연구자가 작성한 논문입니다. 해당 저자는 Multispectral Pedestrian 연구를 활발히 진행중인 연구자 중 한명입니다.
해당 연구는 멀티스펙트럴 보행자 인식 연구를 통해서 강인한 보행자 인식이 가능하게 됐지만, 멀티스펙트럴 보행자 인식 네트워크들은 대부분이 two-stream 구조로 이뤄져 있어 모델의 추론속도가 느리고, 이로인해 RGB 기반 보행자 검출연구보다 상용화 가능성이 적다는 점에 대해서 문제를 제기합니다. 또한 카이스트 셋에서 제공하는 640×512 resolution을 갖는 열화상 카메라는 RGB 카메라에 비해서 가격이 비싼점도 한가지 문제라고 이야기 합니다. 그러면서 저자는 다음과 같이 이야기하고 있습니다.
A typical thermal camera of resolution 640 × 480 could cost more than 8,000 USD. When the resolution is reduced to 80 × 60, the price becomes much more affordable (around 200 USD).
따라서 이러한 문제점들을 해결하여 Low-cost의 Multispectral Scene Analysis(Pedestrian Detection, Semantic segmentation)을 수행하며, Modality Distillation을 제안하고 있습니다.
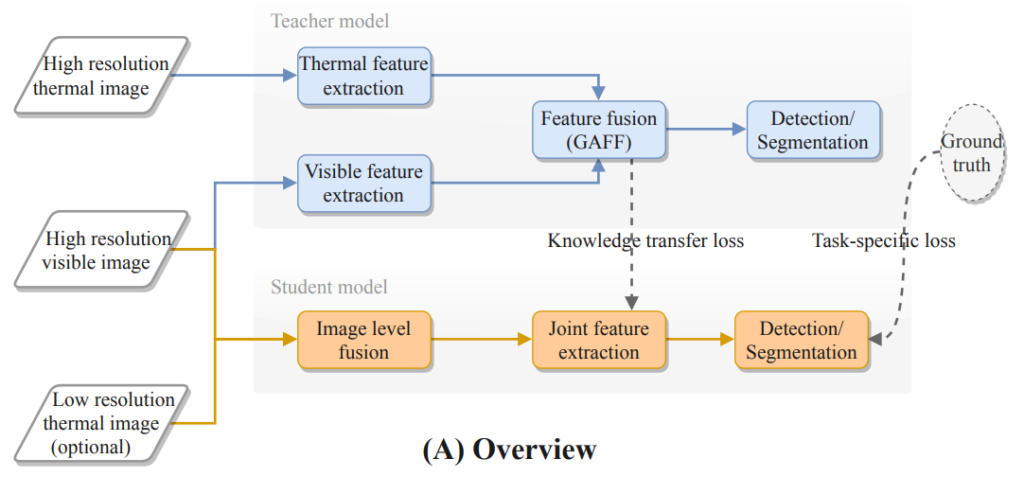
본 연구에서 제안한 방법의 Overview 입니다. 즉 기존 Teacher model의 경우 RGB와 Thermal에 대해서 각각 feature 를 추출하고 이후 fusion하는 형태의 two-stream 구조로 이뤄지고 있습니다. 본 논문에서는 이를 single-stream으로 변경하고 Teacher model의 weight를 Student model이 최대한 잘 가져오는 방법을 제안합니다. 이를 기존 컴퓨터비전 분야에서는 ‘knowledge distillation’이라고 이야기하는데, Teacher 모델보다 적은 파라미터를 가진 Student model이 teacher 모델이 추출한 feature map과 동일한 결과를 만들도록 학습하는 방식입니다. 해당 논문에서는 이러한 방법을 적용하여 Modality Distillation을 제안합니다.
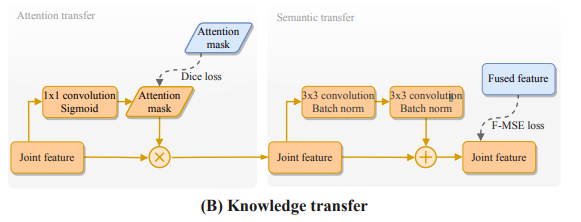
본 연구에서 제안하는 Modality Distillation은 크게 두가지로 나뉩니다. 첫번째는 Attention transfer과 Semantic transfer 입니다. 먼저 Attention transfer의 경우 본 논문에서 베이스라인으로 사용하고 해당 논문의 저자가 이전에 제안한 GAFF 모델에서 제안했던 attention 모듈을 그대로 전이하기위한 파트입니다.
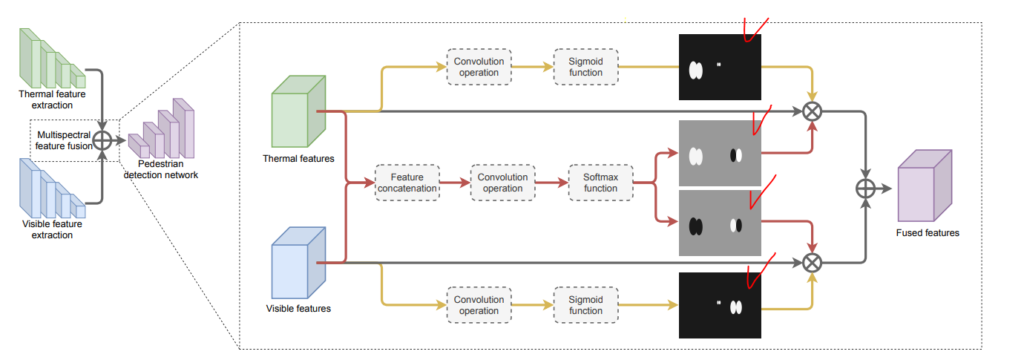
위의 그림은 GAFF의 전체 아키텍처이며, 모델은 빨간색으로 체크한 attention map을 이용하여 fusion을 수행합니다. 해당 논문에서도 이러한 GAFF에서 구하는 attention mask를 그대로 전이학습하기위해서 해당 파트를 추가합니다. 해당 파트는 1×1 convolution을 태우고 바로 sigmoid를 취해서 attention mask를 얻어내며, 이때 해당 파트의 weight를 학습하기위한 GT는 GAFF에서 추출한 attention mask가 됩니다.
다음으로 해당 논문에서는 fused feature map에 대한 전이학습도 진행하기위한 Semantic transfer를 추가합니다. 이는 resolution이 낮은 thermal가 입력으로 들어가더라도 fused feature map에서 RGB와 Thermal의 resolution이 잘 맞춰지도록 teacher model에 512×640 멀티스펙트럴 영상을 통해서 얻은 fused feature map을 전이학습하기위한 파트입니다. 해당 부분에서 teacher model의 fused feature map과의 loss를 계산하여 student model이 저해상도의 열화상 이미지가 들어와도 고해상도의 이미지에서 학습된 teacher model의 fused feature map과 같이 잘 만들어지도록 학습합니다.
또한 해당 모델은 single-stream으로 두 이미지가 다른 백본에 들어갔던 기존 모델과는 다르게 이미지 레벨에서 두 영상을 합치고, 합쳐진 영상을 모델에 입력합니다.
본 논문에서 제안하는 방법론에 대한 유용성을 본 연구에서는 보행자 인식과 의미론적 영상분할에 대해서 검증합니다.
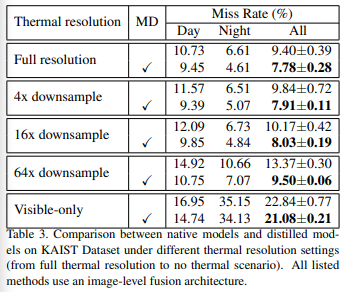
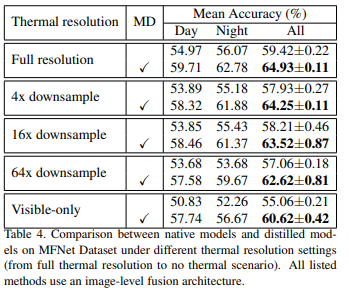
우선 자신들이 제안하는 방법인 Modality distillation을 수행하였을때, 열화상 영상의 resolution이 위와 같이 다운되더라도 성능드랍이 적게 일어남을 실험적으로 증명하고 있습니다. (첫번째는 보행자검출, 두번째는 의미론적 영상분할에 대한 결과입니다.) 또한 자신들의 방식으로 single-stream으로 변경시 기존 연구들보다 더욱 빠른 추론이 가능함을 아래 표와 같이 나타냅니다.
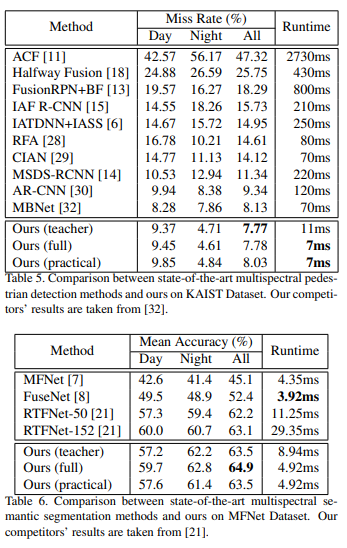
위와 같이 two-stream 기반의 방식을 single-stream으로 변경하여 추론속도가 빨라짐을 입증하고 있습니다. 위의 표에서 full과 practical이 있는데 full은 original size를 의미하며, practical은 visible 이미지 대비 16배 resolution이 작은 열화상 이미지를 입력으로 준 경우를 이야기 합니다. 원본 영상을 사용하더라도 two-stream에서 single-stream으로 줄이는 것만으로도 속도가 빨라짐을 확인할 수 있으며, resolution이 작은 열화상 이미지가 입력으로 들어가더라도 성능의 차이가 크지 않음을 확인할 수 있습니다.
마지막으로 본 연구에서는 2가지 방식으로 전이학습을 수행하는데, 이에 대해서 각각에 대한 ablation study 결과를 다음과 같이 나타내고 있습니다.
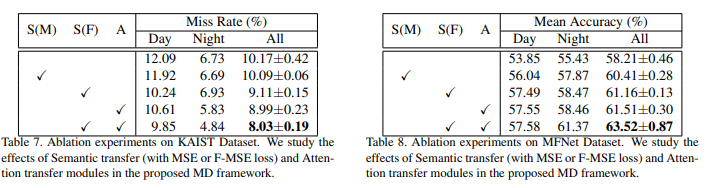
위의 표에서 S는 Semantic transfer를 A는 Attention transfer를 의미합니다. 그리고 Semantic transfer에서 M과 F가 있는데, 제가 본문에서 설명하지 못했지만 M은 MSE loss를 사용하는 방법, 그리고 F는 본 연구에서 제안한 F-MSE loss를 사용하는 방법에 대한 차이를 나타냅니다. 여기서 F-MSE loss란 Focal loss에서 영감을 얻어 본 논문에서 제안하는 방법으로 아래와 같이 정의됩니다.

Focal loss의 자세한 내용은 조원 연구원의 리뷰 를 확인하시면 됩니다. 마지막으로 정성적 결과를 확인하면 다음과 같습니다.

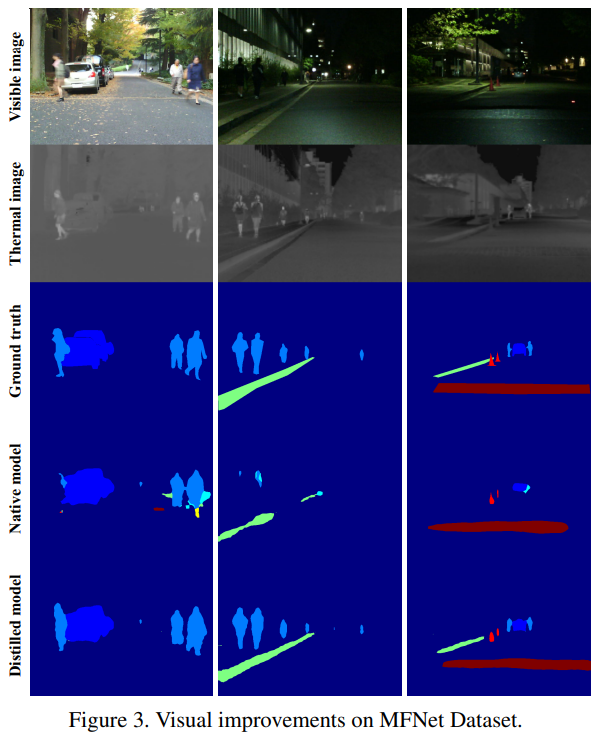
해당 논문을 정리하면 기존 멀티스펙트럴 연구가 two-stream 기반의 네트워크를 사용시 추론속도가 상대적으로 느리고, 이는 상용화에 있어서 중요한 문제가 됩니다. 따라서 본 연구는 기존 two-stream으로 학습한 모델을 single-stream(one-stream)으로 전이학습하는 방법을 이야기하고 있습니다. 이때 입력은 결국 이미지 레벨에서 합치는 방법을 사용합니다. 본 논문을 읽으면서 든 생각을 정리하면 크게 2가지 입니다. 이제 멀티스펙트럴 영상에 대한 아이디어를 제안할 때 Pedestrian Detection 뿐만 아니라, Semantic segmentation을 통해 함께 보여주는게 더욱 설득력을 높여줄 것이다. 현재 제안되는 모든 방법론이 Halfway fusion과 같이 feature-level에서의 fusion이 가장 좋은 성능을 나타냄을 근거로 만들어졌지만, 상용화 가능성등을 미뤄 생각했을때 전이학습을 통해 one-stream으로 변경하는것이 필요할 것 같다. 그리고 마지막으로는 해당 논문도 결국은 이미지레벨에서 합치는데 이때 misalignment가 발생하면 큰 성능 드랍이 일어날 가능성이 매우매우 많으므로 misalignment를 근본적으로 해결할 방법은 아직까지 모두에게 필요한 연구이다.
만약 vis 3채널 infrared 1채널이면 element-wise summation은 안 될거 같은데 이미지를 합치는데는 어떠한 방법을 사용하나요?
리뷰 잘 읽었습니다.
생각보다 teacher와 student 간에 성능 차이가 크지 않아서 애초에 네트워크 자체가 잘 동작하거나 풀고자 하는 문제가 너무 쉽나 생각했는데, ablation study를 보니 저자들이 제안한 방법들이 distillation을 효과적으로 하고 있었네요.
한가지 궁금한 점은 Attention transfer의 경우 저자가 teacher model로 사용한 GAFF? 모델에서만 사용가능한건가요? 그렇다면 MLPD 등 다른 모델들의 경우에는 F-MSE Loss밖에 못사용하나요?
GAFF에서 attention module이 존재하고, 이를 전이학습 하기위해 행긴부분이므로 MLPD에는 attention module자체를 적용할 수 없을것 같습니다.