이번 논문은 Semantic Segmentation 관련 논문입니다. 그런데 Self-supervised monocular depth estimation을 통한 transfer learning & multi-task learning과 active learning과 data augmentation을 곁들인.
하나의 논문 안에 들어간 분야가 참 알차네요. 그럼 리뷰 시작하겠습니다.
Introduction
저자가 introduction에서 주장하고자 하는 말은 다음과 같습니다.
- Semantic Segmentation.. GT가 매우 부족하고 구하려면 노동력이 너무 많이 들어…
- 1번 문제를 해결하고자 Self-supervised learning 쪽 연구가 진행되고 있는데, 특히 Depth estimation 애들이 self-supervised learning으로 연구를 좀 활발하게 하네?
- Depth estimation이랑 Semantic Segmentation이랑 대충 비슷하지않나..? 기존 연구들 보면 Depth Estimation이랑 Semantic Segmentation이랑 multi-task learning 또는 transfer learning으로 성능 향상 많이 시키고들 하던데.
- 좋아 그러면 우리는 Self-supervised monocular depth estimation을 통해 semantic segmentation과 multi task learning도 하고 transfer learning도 하고, Depth가지고 data augmentation도 좀 하고, 추정된 depth 결과에 따라 uncertainty를 정해서 annotation을 보충하는 active learning도 다 해보자!
저자가 욕심이 많은건지 아니면 기존 연구들과 차별성을 두려고 그런건지는 모르겠지만.. 위의 요약에서도 볼 수 있듯이 해당 논문에서 하고자 하는 것들이 참 다양합니다. 물론 조금 더 자세히 말하면 기존 연구들 중에 Depth와 Semantic Segmentation을 함께 수행하는 연구들이 예전부터 꾸준히 제안되어왔는데, 해당 방법론들은 대부분 Fully supervision이거나, 아니면 self-supervised로 한다하더라도 Depth estimation 성능 향상에 초점을 맞춰왔다고 합니다.
하지만 저자는 최대한 Self-supervised learning을 지향하면서 동시에 Semantic Segmentation의 성능 향상을 초점에 맞추어 실험을 진행했다고 합니다. 해당 논문의 contribution들에 대해서 다시 한번 말하면
(1) semantic segmentation과 depth estimation의 multi-task & transfer learning이 있으며, 또한(2) DepthMix라고 하는 새로운 data augmentation과 (3) 마지막으로 self-supervised depth estimation을 proxy-task로 지정하여 중요한 데이터를 선정하는 active learning을 제안합니다.
이를 통해 결과적으로 semi-supervised segmentation에서는 SoTA를 달성하였고 전체 대비 1/30 수준의 label 데이터 셋을 사용하였을 때 Full annotation 대비 성능이 8%정도 밖에 drop 되지 않았으며, 만약 1/8 수준의 label을 사용할 경우 Full annotation보다 약간 더 성능이 우세했다고 합니다.
Method
자 그러면 본격적인 설명에 들어가기 앞서, 먼저 저자가 사용한 Self-supervised monocular depth estimation(SDE) 방법론에 대해서 간략하게 언급하고 가겠습니다. 저자가 사용한 SDE 방법론은 바로 monodpeth2 방법론입니다. 이미 x-review에 저 포함 다양한 연구원님들이 리뷰로 작성해놨기 때문에 자세한 설명을 드리기에는 손도 아프고 해당 논문이 segmentation에 초점이 맞춰졌으니 자세한 설명은 하지 않겠습니다.
대략적으로 깊이 추정하는 Depth Network와 카메라 포즈를 추정하는 Pose Network를 통해 각각 깊이맵과 포즈를 추정한 후 인접한 프레임과 현재 프레임 사이를 미분 가능한 warping을 통해 동일한 프레임으로 warping 시켜서 얼마나 잘 변환됐는지를 photometric loss로 비교하는 것입니다.
Automatic Data Selection for Annotation
자 그러면 먼저 어떤 데이터를 우선으로 annotation을 해야하는지에 대한 data selection(active learning) 부분부터 살펴봅시다.
저자는 K개의 (segmentation label이 없는) 시퀀스 데이터로부터 SDE를 학습시키게 되고, 이를 통해 동일한 도메인의 N개의 시퀀스 데이터 중 어노테이션이 가장 필요한 데이터 N_{A}를 선정하게 됩니다.
이 과정은 가장 기본적인 active learning과 거의 동일한 cycle을 가지게 됩니다. ( model training \rightarrow query selection \rightarrow annotation \rightarrow model training ). 하지만 동일한 사이클을 가진다고 할지라도 큰 차이점이 존재하는데, 저자가 제안하는 data selection은 SDE를 oracle로 하여 annotation을 수행하기 때문에 위의 과정에서 인간이 개입을 할 필요가 없게 됩니다.
이 부분에 대해서 조금 더 자세히 알아보겠습니다.
먼저 \mathcal{G}, \mathcal{G}_{A}, \mathcal{G}_{U} 는 각각 전체 이미지 데이터 셋, annotation을 위해 선정된 서브 셋, 그리고 선정되지 않은 서브 셋들을 의미합니다. 학습 초기에 당연히 annotation된 데이터가 없을테 \mathcal{G}_{A} = \0, \mathcal{G}_{U} = \mathcal{G}로 시작되게 될 것입니다.
그리고 이제 2가지의 방식으로 데이터 셋을 selection하게 되는데, 이는 각각 diversity와 uncertainty 입니다. Diversity sampling은 다양성을 추구하기 때문에 선정된 영상들이 서로 다른 장면들을 많이 포함하고 있으며, Uncertainty sampling의 경우 decision boundary와 매우 인접한 영상들을 위주로 추가하여 모델이 많이 어려워하는 데이터들을 위주로 선정한다고 보시면 될 것 같습니다.
일반적으로 Uncertainty 방식을 하게 될 경우, 먼저 모델을 학습한 후 uncertainty가 높은 데이터 셋을 \mathcal{G}_{A}로 업데이트하여 다시 학습하고 또 uncertainty를 평가하게 됩니다. 하지만 저자는 이렇게 계속해서 반복을 하는 것이 효율적이지 못하다고 판단하여 해당 방식은 딱 T회 까지만 학습하고 데이터 셋을 업데이트하였다고 합니다.
대략적으로 \sum_{t=1}^{T}n_{t} = N_{A} 라고 볼 수 있으며 이는 매 t 단계 이후에 모델은 \mathcal{G}_{A} 를 학습하고 \mathcal{G}_{U}를 평가하여 uncertainty를 업데이트 하게 됩니다.
Diversity Sampling
선정된 annotation 샘플들이 전체 데이터 셋을 잘 대변할 수 있을정도로 다양하다는 것을 보장하기 위해서, 저자는 iterative farthest point sampling을 사용했다고 한다. 쉽게 말하면 \mathcal{G}_{A}의 feature와는 매우 가까운 것들을 위주로 만나고 \mathcal{G}_{U}의 features들과는 L2 거리가 큰 방식을 통해 계산되어 구해집니다.
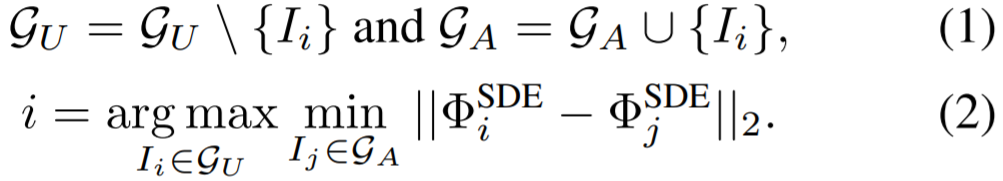
Uncertainty Sampling
Uncertainty Sampling에 대해서는 위에서도 간략하게 언급했지만 모델이 어려워하는 샘플들을 고르는데 초점을 두고 있습니다. 예를 들어 \mathcal{G}_{A}만으로 학습한 모델이 \mathcal{G}_{U}에서 잘 맞추지 못하는 샘플들이 있겠죠.
보통 이 과정에서 active learning은 사람이 개입하여 uncertainty가 높은 데이터 셋을 선정하여 직접 annotation을 만들어주게 되는데, 해당 논문에서는 self-supervised annotation을 기반으로 한 proxy task 덕분에 사람의 개입 없이 완전 자동적으로 active learning을 사용할 수 있다고 합니다.
저자는 proxy task로 Single-image depth estimation(SIDE)을 사용했다고 합니다. 여기서 중요한 점은 Self-supervised monocular depth estimation(SDE)와 proxy task인 SIDE가 서로 다른 task라는 것을 명심해둬야 합니다.(처음엔 저도 같은 건줄 알았는데 저자가 각각을 서로 다른 명칭으로 부르더군요.)
더 자세히 얘기하자면 monodepth2와 같은 self-supervised 방식으로 학습한 SDE 덕분에 우리는 전체 데이터 셋 \mathcal{G}에 대하여 pseudo depth label을 구할 수 있게 됩니다. 그리고 해당 pseudo label을 통해 \mathcal{G}_{A}에 대하여 SIDE를 따로 지도 학습을 시킬 수 있게 됩니다.
이렇게 학습된 SIDE는 이제 한번도 보지 못한 \mathcal{G}_{U}에 대하여 uncertainty를 추정하게 되며 이때 Depth Estimation과 Semantic Segmentation은 서로 높은 상관관계가 있다보니 SIDE에서 구한 uncertainty가 높은 data를 semantic segmentation에서도 그대로 적용해볼 수 있다는 것이죠.
요약하자면 SDE는 SIDE 데이터 셋에게 질 좋은 pseudo label을 주기 위해 SIDE보다 더 방대한 양의 데이터 셋으로 학습을 수행하였고 이를 통해 SIDE는 annotation이 존재하는 \mathcal{G}_{A}에 대해서 pseudo label과 함께 학습을 진행합니다. 그 후 \mathcal{G}_{U}에서 uncertainty를 추정하여 그 값이 높은 데이터를 선정하는 작업을 거치게 되는 것이죠.
여기서 Uncertainty 계산은 student network f_{SIDE}와 teacher network f_{SDE}에서 추출한 disparity map 간에 log-scale L1 distance error로 계산하실 수 있습니다.
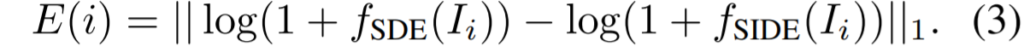
log-scale로 취해준 이유는 멀리 있는 물체들은 영상 속 영역에서 그 비중이 좁을테니 가까운 물체들에 대해 너무 loss가 큰 비중을 차지하지 못하도록 log-scale을 취했다고 합니다.
결과적으로 아까 전 Diversity sampling 수식에서 위의 Uncertainty Sampling을 추가한 수식은 아래와 같습니다.
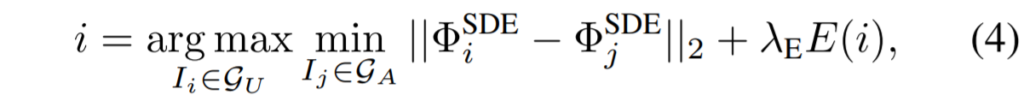
DepthMix Data Augmentation
다음은 두 번째 컨트리뷰션인 data augmentation에 대해서 알아보겠습니다. 기존 연구들 중에 영상과 pseudo 또는 real label 쌍을 가지고 mixup하여 데이터 셋을 늘리는 data augmentation 방법들이 종종 제안되는데, 저자는 이들에게 영감을 받아 self-supervised depth estimation을 활용하여 mixing하는 과정 중에 전체 구조가 깔끔하게 유지되는 DepthMix augmentation을 제안합니다.
여기 동일한 해상도의 서로 다른 영상 I_{i}, I_{j}가 있다고 가정해봅시다. 여기서 mixup 방식은 I_{i} 속 특정 영역을 복사하여 I_{j} 영역에 가져다가 붙여버리는 것을 의미하는데, 이때 영역을 복사하는 마스크를 M라고 정의하겠습니다. 그러면 새로운 영상은 아래 수식과 같이 만들어지게 됩니다.
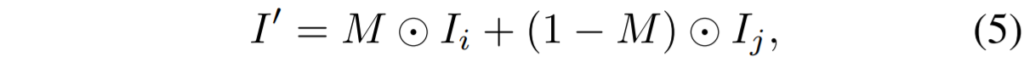
주로 mixup은 한쪽은 segmentation label이 있고 다른 쪽은 없는 경우에 많이 사용하게 되는데 실제 segmentation label일수도 있으며 또는 pseudo-label일 수도 있습니다. 현존하는 data mixup 방법론들은 대부분 randomly sampled rectangular regions을 사용하거나 또는 randomly selected object segments를 사용하곤 했습니다.
하지만 이 방법론들은 장면의 구조나 이런 것들은 전혀 고려하지 않았기 때문에 실제로 물체와 배경 간에 전경과 후경의 경계가 모호해지는 현상등이 발생하게 됩니다. 또한 저자는 이러한 합성 방식이 종종 물체들 사이에 기하학적인 관계들도 무시해버리게 된다고 말합니다.
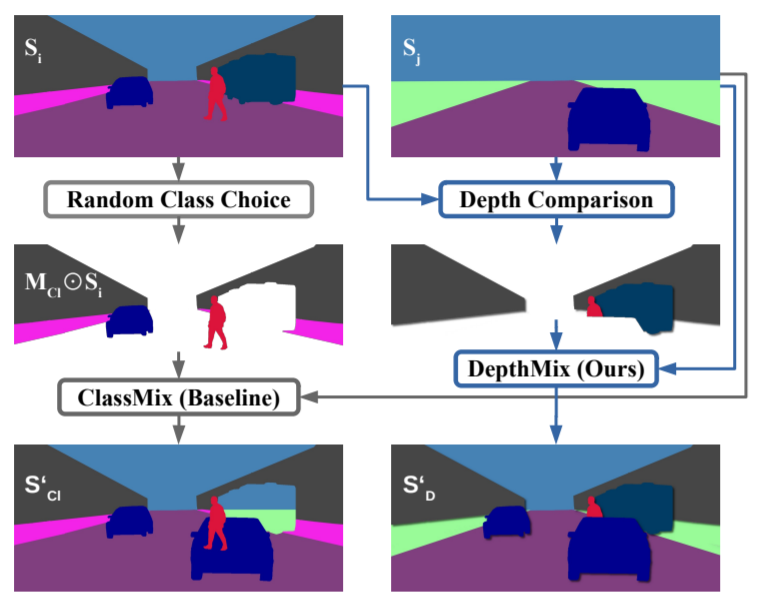
보다 자세한 예시를 들어보면 그림1에서 왼쪽 열은 기존의 Mixup 방식을 표현한 것입니다. 보시면 기존 입력에는 차량 두대와 보행자 한명이 존재하게 되는데, 이때 우측 차량은 제거되고 다른 영상 속 차량을 집어넣게 될 경우 사람이 차 안에 박혀있거나 기존에 차가 있던 자리에 하늘과 도보가 있는 기하학적으로 불가능한 현상들이 발생합니다.
반면 논문에서 제안하는 DepthMix 방법론은 i,j번째 영상들에 대하여 추정한 깊이 맵 \hat{D}_{i}, \hat{D}_{j}을 활용하여 geometry 개념을 반영한 새로운 mix mask M을 설계하게 됩니다. 컨셉은 매우 단순한데, I_{i} 영상 속 동일 픽셀 위치에서 오직 깊이 값이 I_{j}보다 더 작은 픽셀들만을 골라오게 하는 것입니다.
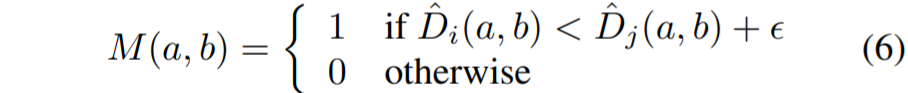
위 수식에서 엡실론은 땅 또는 하늘과 같이 동일한 깊이 평면을 가지는 곳에 대해서 비교 계산이 충돌나게 될 경우를 방지하고자 더한 값이라고 보시면 될 것 같습니다.
아무튼 이렇게 새로 정의한 M 마스크 덕분에 양쪽 영상들 속 물체의 깊이를 고려하여 오직 더 가까운 물체들만이 더 멀리 있는 물체들을 가려버릴 수 있도록 설계하였습니다.
Semi-Supervised Semantic Segmentation
마지막으로… Multi-task learning에 대한 방법입니다. 먼저 파이프라인 부터 살펴보시죠.
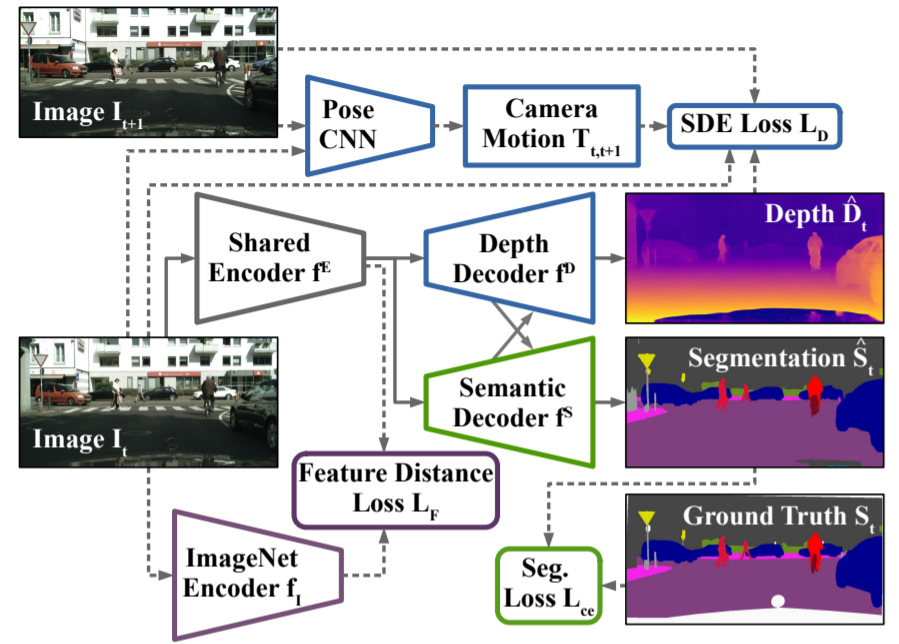
그림2를 대충 살펴보면 Segmentation과 Self-supervised depth estimation을 동시에 진행한다라는 점이 먼저 보이고 있습니다. 그래서 위의 남색 부분은 모두 depth estimation과 관련된 부분들이니 그냥 넘어가고 크게 2가지가 눈에 보이는데 하나는 encoder는 쉐어하고 디코더를 분리해서 사용한다는 점과 둘째로는 ImageNet encoder를 통해 Feature distance를 계산한다는 점이겠네요.
ImageNet Encoder와 feature distance를 왜 계산하는지에 대해서 먼저 말씀드리면, 저자는 semantic segmentation을 학습하기 전에 Self-supervised depth estimation을 먼저 학습하여 Depth Decoder와 Pose Encoder를 초기화하게 됩니다.
하지만 저자는 ImageNet으로 사전학습한 encoder weight들은 분명 의미론적으로 유용한 정보들을 표현하고 있을 것이라 판단, SDE 학습으로 인해 Encoder가 semantic feature를 잘 표현하지 못하는 것을 방지하고자 가장 끝단에 bottleneck feature 끼리 서로 weight 값을 L2 loss로 비교하는 loss를 사용하게 되었습니다.(굳이? 그래야하나 싶긴한데 그렇다고 하네요.)
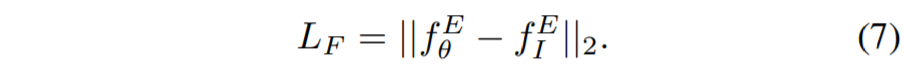
즉 SDE 학습을 수행할 때 단순히 Depth 관련 loss만 사용하는 것이 아닌, ImageNet Encoder feature와도 유사하도록 하는 loss를 추가하여 학습을 진행하게 됩니다.
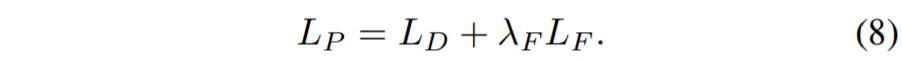
마지막으로 segmentation 관련 loss는 semi-supervised 방식으로 진행되는데 label이 있는 데이터 셋과 그렇지 못한 데이터 셋에 대하여 exponential moving average 방식을 취했다고 합니다.
Experiments
다음은 실험 결과입니다. 평가용 데이터 셋으로는 CityScape 데이터 셋을 사용했습니다.
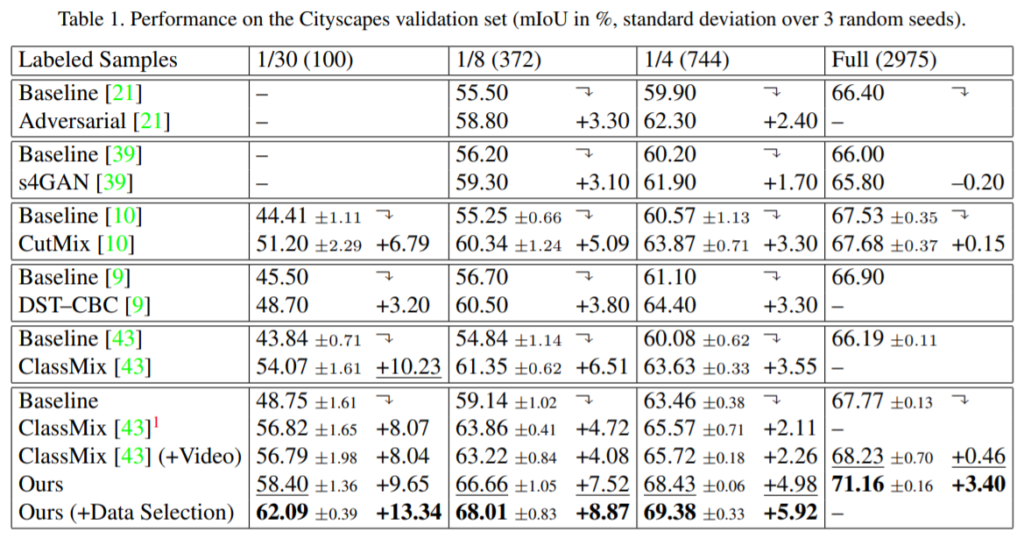
위의 labeled sample은 전체 label이 있는 dataset 중 각각 1/n만큼 사용했다는 것을 의미하는데, 제안하는 방법론이 기존 ClassMix라는 방법론과 비교하여 더 좋은 성능을 보여주고 있으며 특히 Data Selection을 수행하게 될 경우 1/30 데이터 셋만 활용했을 때 매우 큰 성능 향상폭을 보여주고 있습니다.
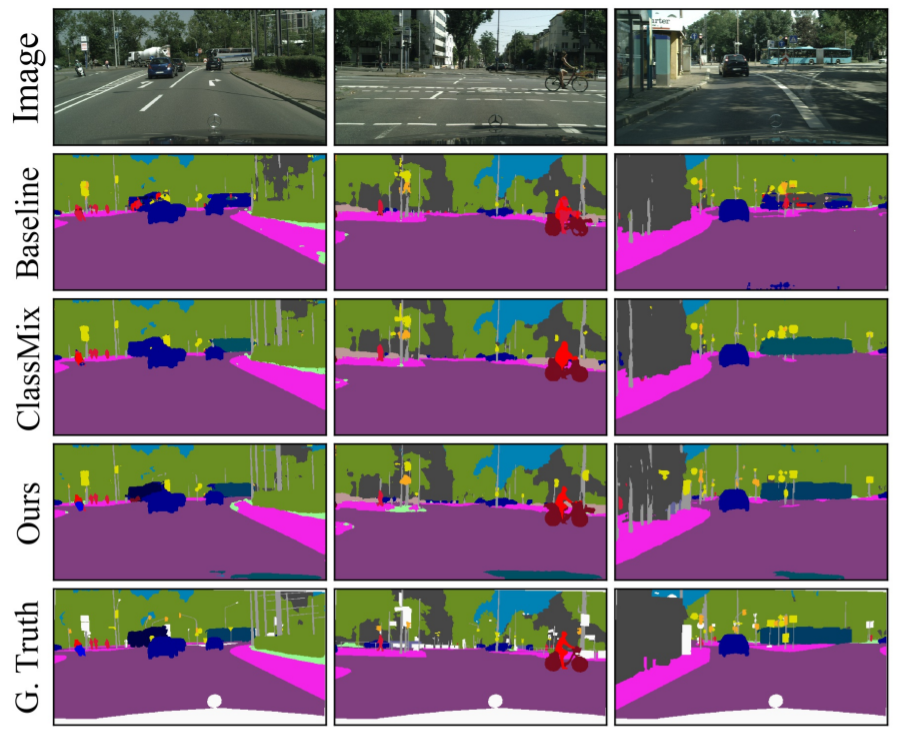
다음은 정성적 결과입니다. 제안하는 방법론이 더 세부적으로 디테일 있고 선명한 것을 확인할 수 있습니다.
결론
제가 기존에 생각했던 multi-task learning은 단순히 각 task에 대해서 동시에 수행함으로써 알아서 encoder 또는 네트워크 전체가 잘 학습해라~였는데 해당 논문은 multi-task를 통해 학습 방식, augmentation, active learning 등 정말 다양한 방면으로 depth estimation을 알차게 활용했다는 점에서 매우 인상 깊은 논문이었습니다. 논문에서 다루는 내용이 조금 방대해서 해당 리뷰에서는 깊게 다루지 못하였는데, 시간이 생기면 꼼꼼하게 다시 읽고 추후 논문 작업에 영감을 주는 방향으로 고민을 더 해봐야 할 것 같습니다.
어렵네요… multi task… 괜히 내년 목표로 잡은 건가 싶기도 하고… 뭔가 Ablation Study가 안되어 있는거 같은데, 혹시 저 ImageNet feature하고 비교하는 Loss 빼면 성능이 얼마나 안좋아지는지 리포팅되어있나요?
Multi-task learning에 대하여 더 다양한 논문들을 읽어봐야 하겠지만 아마 이번에 제가 리뷰한 논문과는 다른 방식의 방법들도 있을 듯 합니다. 그리고 저희가 다소 다루지 않은 분야들이 자주 등장해서 그렇지 막상 논문을 읽어보면 그리 어렵지는 않습니다. 결론에서도 말했지만 해당 논문은 말 그대로 multi-task를 통해 active learning, data augmentation 등 다양한 방식으로 접근할 수도 있다 정도로만 이해하면 좋을 것 같네요.
말씀해주신 ImageNet feature 관련 내용이 논문에 있는지는 모르겠으나 Ablation study는 제가 리뷰에 리포팅 안한게 맞습니다. 여유 생기면 추가해서 올리도록 하겠습니다.