이번 주 x-review는 3D detection중에서 나온지 얼마 안되었고 일부 데이터셋에서 SOTA를 달성한 논문에 대해서 리뷰하겠습니다. 음… 공개된지 2주정도 된거 같고 상당히 좋은 학회인 AAAI 2022에 accepted된거 같네요.
개인적으로 3D detection에 대한 지식이 짧아서 읽기 상당히 힘들었던 논문인거 같은데 아마 다른 3D Detection관련 논문도 마찬가지 아닐까 싶습니다. 어찌됐든 극복해야할 관문인거 같습니다. 수식/코드 등의 디테일까지 온전히 이해하기는 아직 내공이 부족한거 같은데 일단 뭐 컨셉적인 면에서는 이해하는데 어렵지 않았습니다. 거의 1년만에 3D Detection관련 리뷰를 하는거 같네요.
해당 논문을 읽게된 계기는 papers with code 에서 찾게되었고, 성능이 좋은 논문중에 최신이면서 code가 공개되어 있었기 때문에 한번 살펴보고자 읽게 되었습니다.
논문
먼저 해당 논문은 라이다 센서를 이용한 3D detection 논문입니다. 해당 논문에서 다루고자하는 문제는 포인트 클라우드내에 존재하는 missing data입니다.
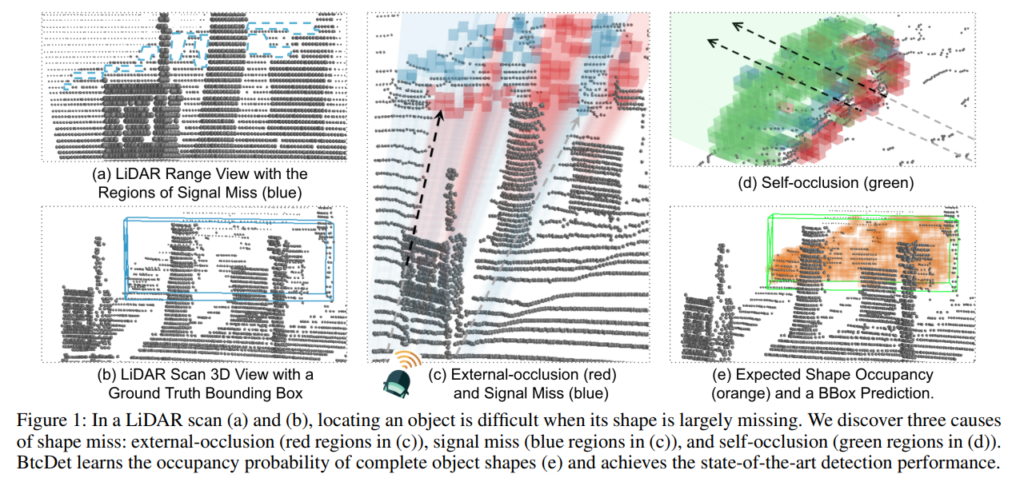
위의 그림과 같이 missing point들이 발생하는 원인에 대해서 분석을 하였는데, 해당 저자는 라이다 센서에서 missing data가 발생하는 이유를 3가지로 나누어서 설명합니다.
- external occlusion (EO)
- signal miss (SM)
- self occlusion (SO)
각각의 용어가 무엇을 뜻하는지 먼저 설명해드리겠습니다. external-occlusion은 어떠한 물체가 라이다센서의 경로상에 있어서 해당 물체 뒤에 있는 물체는 라이다센서가 잘 인식하지 못하는 경우입니다.
다음으로 signal loss는 라이다센서가 물체에 도달은 하지만, reflection되는 과정에서 loss가 발생해서 return 되는 값이없는 경우입니다.
마지막으로 self-occlusion은 모든 물체에 존재하며, 라이다센서가 물체를 투과할 수 없기 때문에 발생하며, 물체의 반대편에 대한 정보가 소실되는 현상을 말합니다. (라이다센서 기준 정면부분에 대한 정보만 획득가능)
위의 그림과 설명을 매칭해서 보시면 위의 3가지 용어확립에 좀 더 도움이 될거라고 생각합니다.
해당 논문에서는 위에서 정의한 3가지 이유로 point cloud 데이터가 일부 소실된 경우, 해당 소실된 데이터를 복원하는 방식으로 모델의 성능을 높였다고 말합니다.
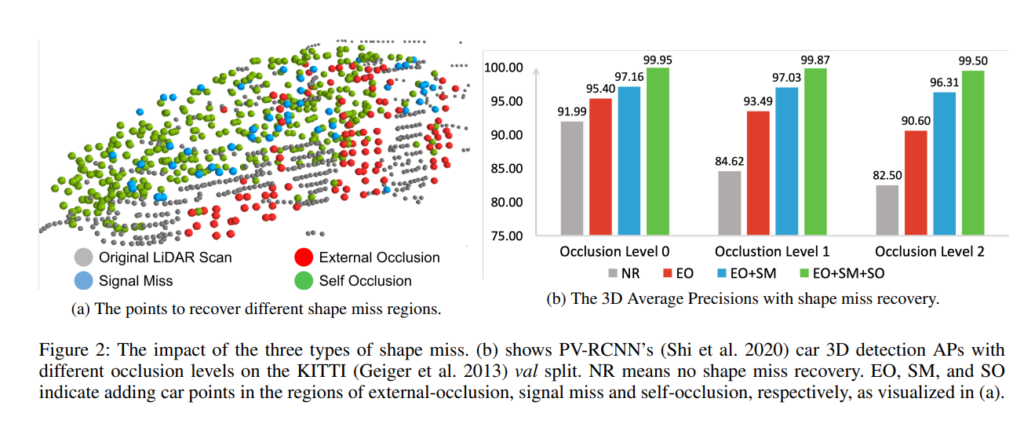
위의 그림 (a)에서는 위에서 정의한 포인트 클라우드 데이터 소실의 원인인 3가지 문제들의 예시를 보여주며, (b)에서는 각 3가지 문제를 복원하는 방식으로 모델을 학습하고 평가했을때, 정량적 결과입니다. KITTI 데이터셋에는 occlusion 정도에 따라서 level 0~2로 나뉘고, 해당 level별로 missing cloud points를 recovery한 다음에 성능이 확연히 오른 것을 알 수 있습니다.
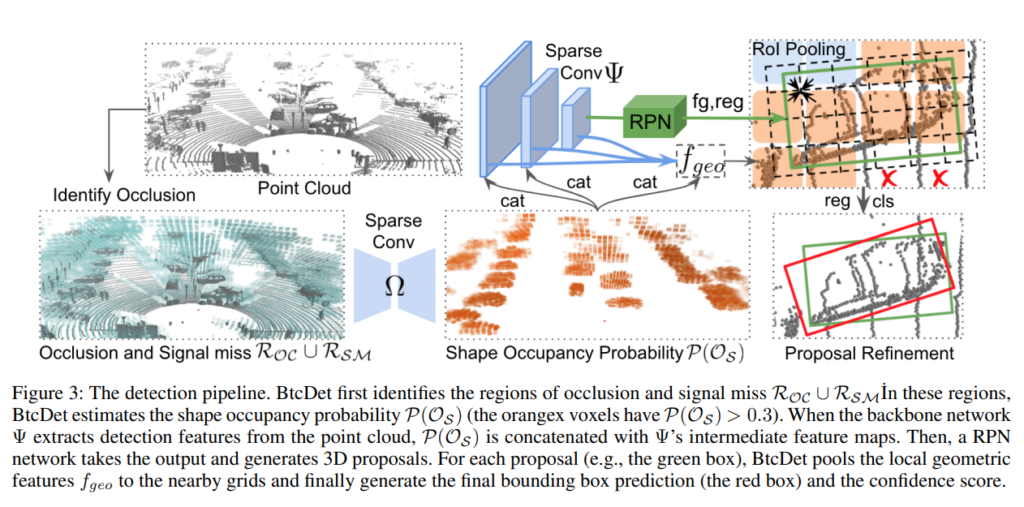
위의 그림은 전체적인 프레임워크입니다. “포인트 클라우드에서 먼저 occlusion과 signal miss가 있는 곳의 합집합을 구하고 해당 부분에서 shape occupancy probability 맵을 구합니다.” 해당 말이 좀 어려운데 쉬운말로 하면, 포인트클라우드에서 데이터가 빈곳들의 집합을 찾고, 해당 빈 데이터들에 데이터를 채워넣어야 할것인지 말것인지에 대한 확률값을 구하는 것입니다.
그렇게 나온 shape occupancy probability map에서 thread cut을 0.3으로주고 0.3이 넘는 곳들은 data를 채워넣습니다. 그리고 데이터가 복원된 point cloud맵에서 multi-scale feature 피쳐를 추출하여 사용합니다.
해당 multi-scale 피쳐와 shape occupancy probability map에서 얻은 확률값을 인풋으로 RoI proposal들을 구해줍니다.
각각의 RoI proposal들을 grid로 나누고 grid마다 local feature를 구해줍니다.
이제 마지막으로 이러한 proposal과 local feature를 refinement하는 과정을 통해 최종적인 bbox prediction과 confidence score가 계산되게됩니다.
여기까지 전체적인 파이프라인을 살펴보았는데 과연 missing point 복원을 위한 네트워크의 학습은 어떻게 하는 것 일까요? 그런데 학습데이터의 경우 GT데이터가 있지만, 테스트 데이터에선 GT가 없는데 과연 어떠한 방식으로 missing point를 복원 할까요?
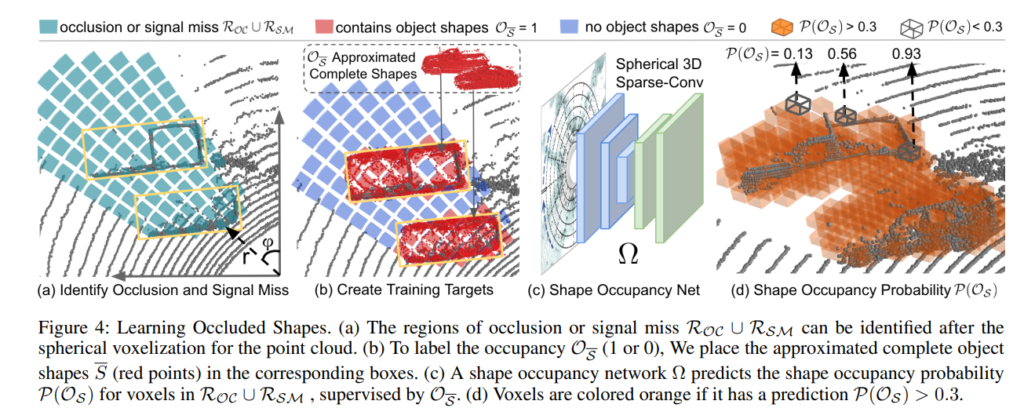
위의 그림을 보면 그러한 과정이 나와있습니다. 먼저 spherical voxelization을 진행하는데, 간단히 말하자면, 우리가 흔히 익숙한 직각좌표계가 아니라 회전좌표계에서 voxel화를 진행하는 것 입니다. voxel이란 grid cell이랑 비슷한 개념이며, 위의 그림 (a)에서는 사각형(곡선이 석여있으므로 정확히 사각형은 아님) 한개 한개를 뜻합니다.
그다음 해당 spherical 좌표계 위에 Region of occlusion을 (a)와 같이 쳐줍니다. 해당 Region of occlusion에 대한 라벨값은 1 혹은 0 이며, 이때 해당값은 occupancy를 의미합니다. 여기서 occupancy에 대항 GT값은 물체의 특성을 이용합니다. 예를들면, 자동차나, cyclist 같은 경우에는 대칭구조이기 때문에 missing point를 이러한 구조를 이용해서 복원할 수 있을 것 입니다. 음.. 여기서 든 생각이 물체의 구조가 대칭적 특징이 있는경우에만 활용할 수 있겠다란 생각이 드네요.
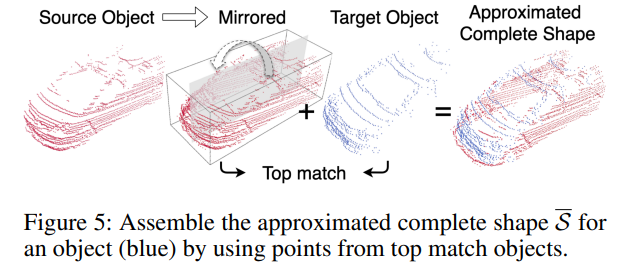
단순화 시켜서 생각해보면 없는 데이터값을 채워 넣는 approximated complete shape의 과정은 아래 그림과 같습니다.
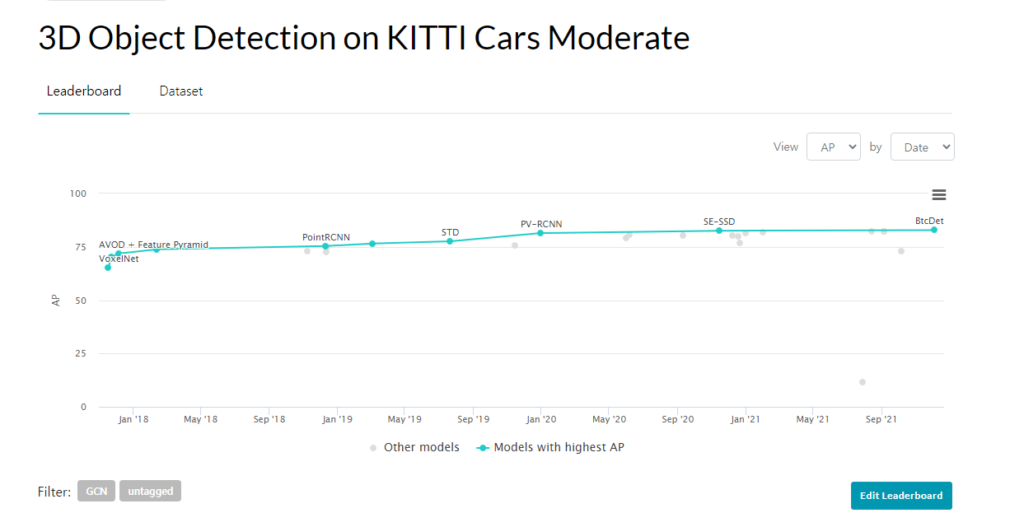
실제로 paper with code에서도 위의 그림과같이 moderate car에서 SOTA를 달성하였는데 car같은 경우에는 대칭적인 구조를 띄기 때문입니다. 근데 생각보다 성능차이가 드라마틱하진 않네요. 뭔가 압도적 SOTA를 찍은 그런 모델이 없는가 봅니다.
평가는 KITTI하고 Waymo 데이터셋에서 하였습니다.
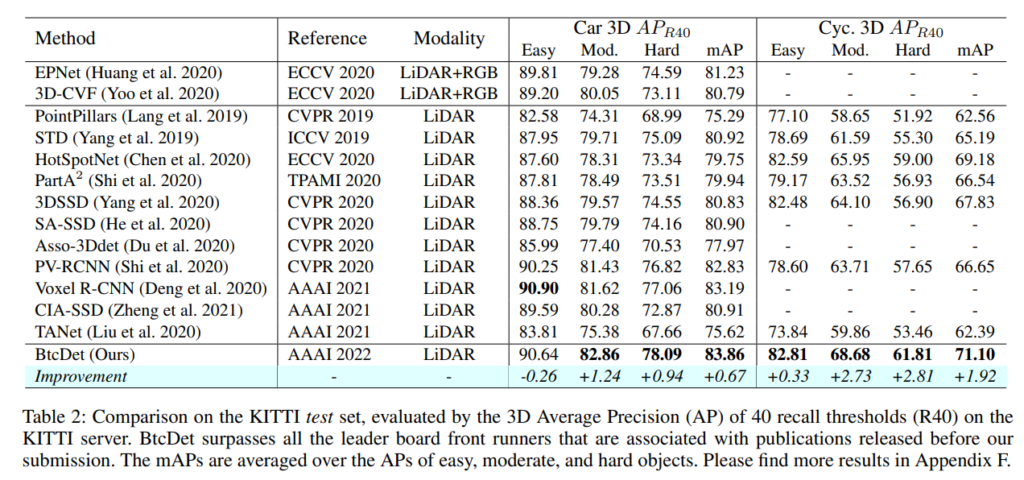
KITTI test set에서의 평과 결과를 보면, car하고 cyclist에서 성능이 잘나왔는데, 이는 object completion과정을 하기위해서는 symmetric한 구조를 띄고있어야 하기 때문입니다. 애초에 symmetric하지 않은 경우에는 해당 방법을 적용하기 힘들어보입니다.
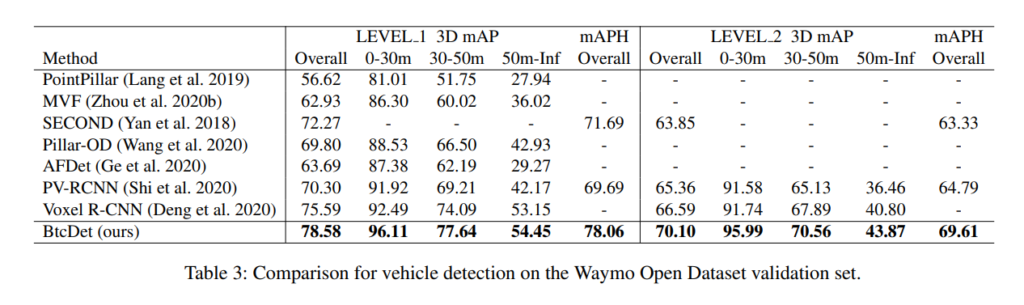
Waymo에서도 좋은결과를 보였습니다.
음.. 평가 protocol을 citation한 다음에 거기를 따라했다고 했는데 제가 이분야에 대해 아직 잘 몰라서 정형적으로 쓰이는 프로토콜인지 모르겠네요. 좀 특이한점이 AP score를 측정할때 IoU 쓰레드컷을 car은 0.7을 나머지는 0.5를 사용했단 것과 validation set을 0.2퍼센트로 나누었단점 입니다. 또 개인적으로 드는생각은 왜 AP를 측정할때 일반적인 IoU만을 사용할까요? 단순 오버랩된 정도만이 아니라 bbox의 aspect ratio나 center coordinates까지 고려하는 DIoU, CIoU등 다른 IoU도 있을텐데 말이죠.
3D 논문을 읽으려니 생각할게 정말 많아지네요. 아무래도 평가 프로토콜이나 전체적인 프레임워크는 몇번 읽다보면 익숙해질거 같긴한데 코드까지 볼생각 하니 좀 막막하네요. 그래도 모르는게 워낙 많다보니 하나하나 해결해나가는 보람이 있는거 같습니다.