최근에 visual search와 관련된 논문들을 읽고 있습니다. 대부분의 논문에서 visual search를 Content-based Image Retrieval과 동일한 용어로 정의합니다. 이 task는 이미지가 주어 졌을 때, 해당 이미지와 시각적으로 유사한 이미지들을 랭크를 매기는 task 입니다. 이번에 x-review에 작성하는 논문은 마이크로소프트의 검색엔진인 Bing에 적용된 visual search system에 대한 논문입니다. 그럼 시작하겠습니다.
Introduction
Bing이 최초로 visual search를 적용한 회사는 아닙니다. 산업계에서 visual search system에 대한 탐구는 주로 실현 가능한 vertical specific systems에 집중해왔습니다. Bing보다 먼저 Pinterest나 Ebay가 이러한 시스템을 개발했는데, 연구팀은 relevance, latency, storage에 대한 고려가 없다고 합니다.
실질적으로 web-scale에서 visual search를 수행하기 위해서는 데이터베이스가 특정 웹사이트에 한정되어서는 안된다고 합니다. (이건 다른 회사들과는 달리 Bing이 검색엔진이기 때문이겠죠?) 이 경우에는 세가지 관점에서 challenging한 문제가 생깁니다.
- 많은 연구가 적은 데이터셋에서 작동하도록 되어있어 적용하기 부적절함. (relevance 문제)
- 저장공간의 가용성에 문제가 있음. (storage 문제)
- modern visual search engine은 최적의 연관성 결과를 얻기 위해 다양한 feature 정보로 보완된 learning-to-rank 구조를 사용함. (latency 문제)
Bing에서는 이러한 문제점들을 해결하기 위해 공학적인 trade-offs를 고려한 방법론을 적용하여 효율적인 visual search system을 구축했다고 합니다.
- cascaded learning-to-rank framework를 통한, latency와 relevance의 trade off
- product quantization을 통한, relevance와 storage의 trade off
- SSD를 저장장치로 도입해, latency와 storage의 trade off
여기서 약간 첨언하자면, 이러한 visual search들은 기본적으로 이미지에서 object detection과정을 거치고, detection결과를 바탕으로 retrieval을 수행하는 것으로 보입니다. 세부적인 구조들은 각 회사가 보유한 데이터가 어떤 데이터인지, 그리고 어떤 서비스를 제공해야하는지에 따라 달라지고요.
System overview
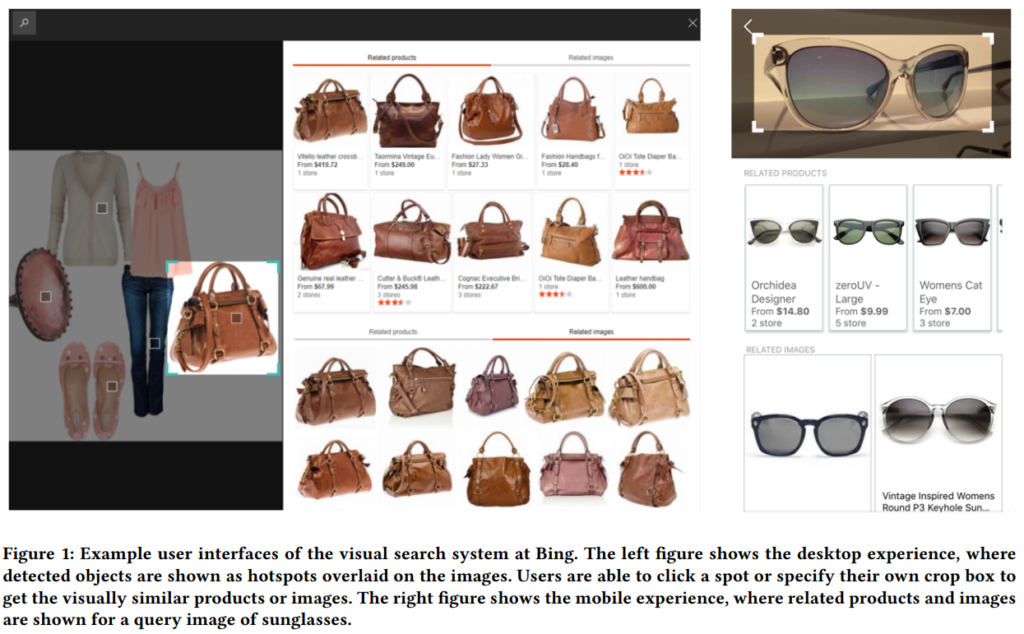
Bing에서 사용하는 visual search system은 위의 그림과 같습니다. 이 시스템은 크게 3단계(Query understanding, Image retrieval, Model training)로 구성됩니다.
- Query understanding
이미지에서 다양한 종류의 feature(category recognition features, face recognition features, color features, duplicate detection features)를 여러 DNN 모델을 통해 추출합니다. 그리고 쿼리 이미지의 특징을 표현할 수 있는 image caption도 생성합니다.
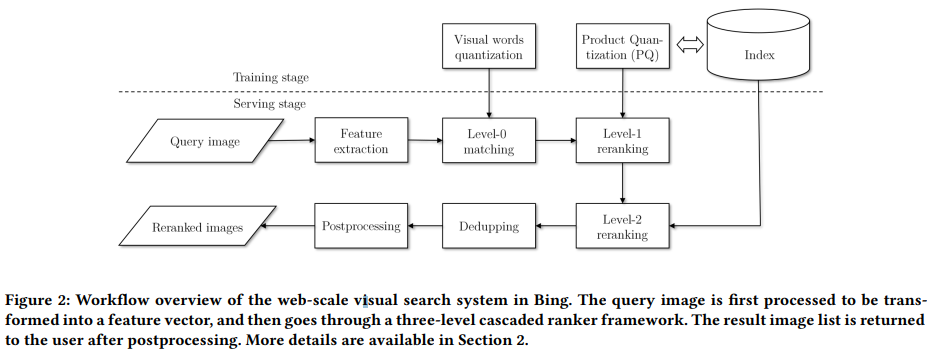
- Image retrieval
Bing에서는 이 과정을 두단계로 진행합니다. 위의 그림처럼 쿼리 이미지가 주어졌을 때, feature를 뽑고 (이 단계가 아까 말한 Query understanding의 단계) level-0 matching과 level-1 matching으로 나뉘어집니다. 각 단계는 뒤에 설명이 나옵니다.
- model training
학습과 예측 단계에서 어떻게 쓰였는지 개략적인 설명이 나옵니다.
- 다양한 DNN 모델들과 loss들이 학습에 사용됩니다.
- joint K-means 알고리즘을 통해 level-0 matching에서 사용할 inverted index를 구축합니다.
- 서빙할 때 latency 문제를 해결하기 위해 PQ가 적용되었습니다.
Approach
Bing에서 3가지 문제점들을 제시한 만큼 이 파트에서는 각각의 문제점들을 어떻게 해결했는지를 다룹니다.
Relevance
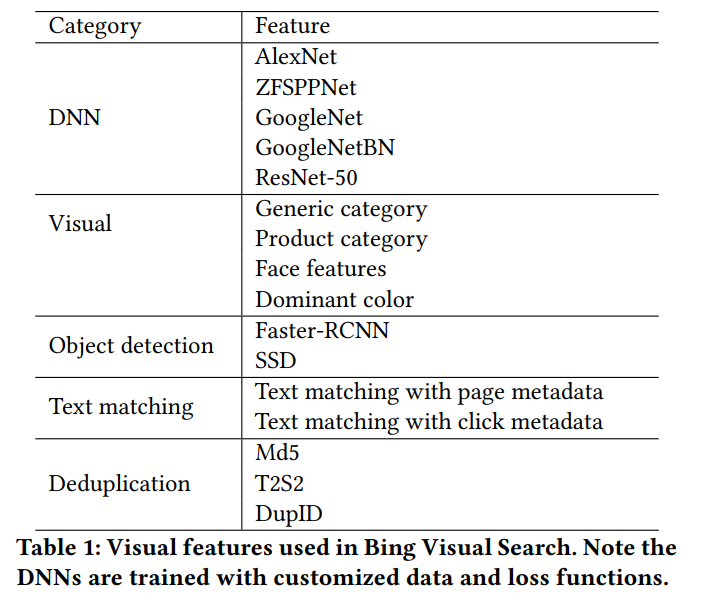
먼저 좋은 feature를 뽑기 위해 이 당시의 SOTA DNN 모델들은 전부 테스트하고 사용했다고 합니다. 물론 feature를 많이 뽑는 만큼 모델도 분산되어 있기 때문에 이를 학습하기 위해 multiple loss function과 triplet loss를 사용했다고 합니다.
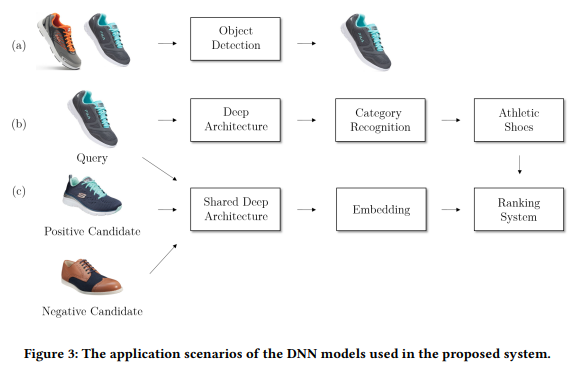
이 구조를 잘 보여주는 그림이 위의 그림입니다. Introduction의 첨언으로 visual search들이 일반적으로 object detection을 수행하고, 수행한 결과를 바탕으로 retrieval을 한다고 말씀드렸는데요. 이 그림이 전형적인 그 구조를 따르고 있습니다. (a)가 물체를 찾는 과정이고요. (b)에서는 이제 Inception-BN network를 사용해서 Category feature를 학습합니다.
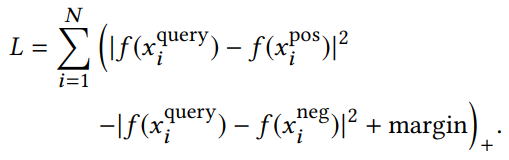
그리고 (c)에서는 triplet loss를 사용한 visual search학습이 수행됩니다. 많은 feature를 뽑는다고 말씀드렸는데요 이 과정에서 aggreagtion해서 사용합니다. 그리고 최종적으로는 lambdaMART ranking model을 학습시킵니다. (Learning to Rank라고 search engine ranking에서 순위를 학습하는 분야에서 쓰인다고 합니다. 이 모델은 “multivariate regression tree model with a ranking loss function”라는데 해당 분야를 조금 더 공부해야 알 수 있을 것 같습니다.) 속도 문제를 해결하기 위해 local feature를 사용해서 중복 이미지도 제거하는 방법도 적용되었다고 합니다.
Latency
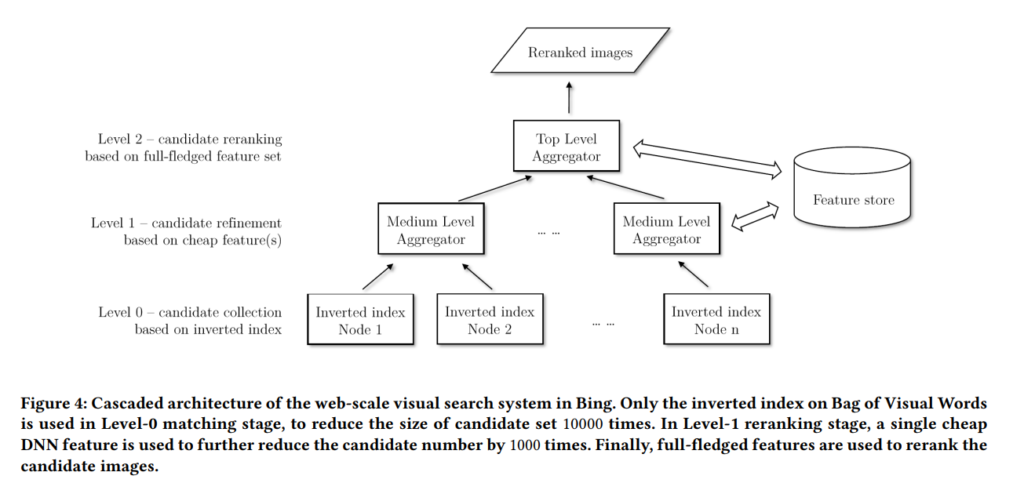
학습과 더불어 핵심 부분이라고 볼 수 있는 부분입니다. 먼저 이미지 자체가 워낙 많기 때문에 전체 이미지에 대한 유사도를 측정해서 랭킹을 매길 수 없다는 것은 자명한 사실입니다. 그래서 Bing에서는 유사하지 않은 이미지를 걸러냈습니다. 이렇게 초기 후보군을 inverted index를 통해 생성합니다. 이 단계를 마치면 위의 그림에서 Inverted Index Node들이 만들어집니다.
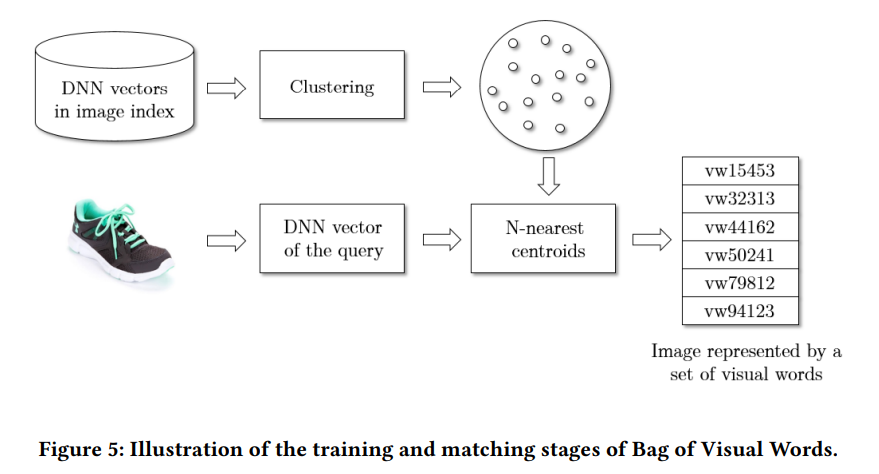
유사한 이미지는 위와 비교 됩니다. 쿼리 이미지와 visual word가 일치하는 경우의 이미지들만 비교하는 방식입니다. 그렇다고 하더라도 이미지의 수가 여전히 많고, 뽑힌 DNN feature는 여전히 큰 용량입니다. Introduction에서 말한 product quantization이 여기서 적용됩니다.
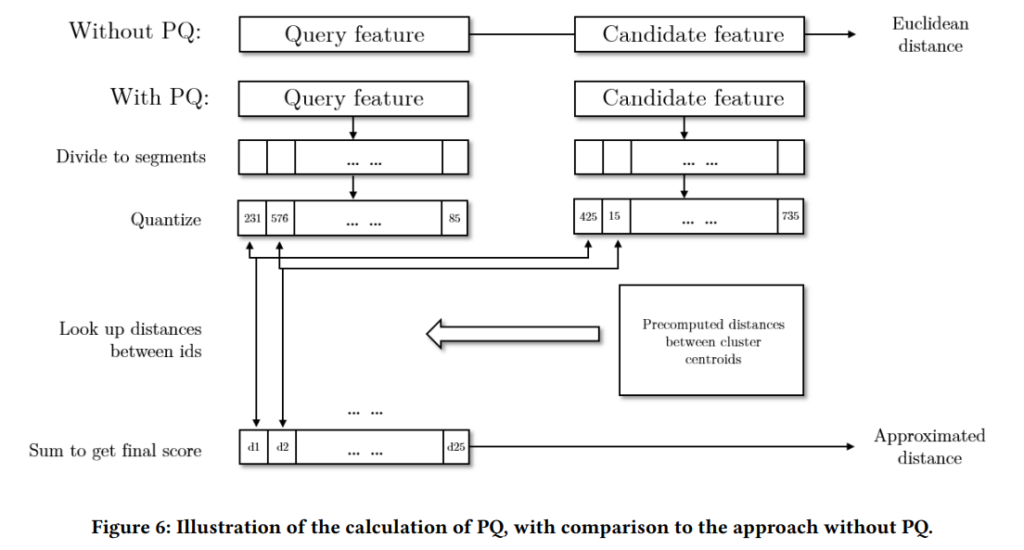
고차원의 feature를 직접 비교하는 방법 대신 cluster center를 이용해 feature vector들의 근사치를 구하는 방법을 통해 해결합니다. 이렇게 할 경우 클러스터 간의 거리를 사전에 계산해둘 수 있습니다. PQ에 대해서도 처음 보는 방법이라 찾아봤는데, 연구적인 부분에서 경량화를 위해 사용한다고 합니다. 원본 벡터를 sub-vector로 줄이고 각각의 sub-vector를 centroid의 id로 대체하는 방법으로 요약할 수 있겠네요.
사실 이렇게 해도 되는지가 조금 이해가 어려웠는데, Visual search의 A 이미지와 B 이미지의 유사도를 구하는 것이 목표가 아니라, 유사한 이미지들의 순서를 구하는 문제라 이런 방법이 가능한 것 같습니다.
Storage
크게 2가지 방법을 이용합니다. 첫째로 실제 값 대신 PQ IDs를 적용해, DNN feature의 물리적인 용량 자체를 8KB에서 25byte로 줄였습니다. 이렇게 되면 이미지 매칭을 위한 visual word 크기 자체가 크게 감소합니다. 여기서 끝이 아니라 이 feature들을 수백개의 머신에 분산처리합니다.
Object detection
당시 SOTA 방법론이었던 Faster R-CNN과 SSD를 모두 백본으로 사용했다고 합니다.
Engineering
이 부분부터는 정말 공학적인 내용이라 간단하게만 요약하면, CPU와 GPU에서의 처리 속도를 비교하고 역시 MS 답게… 자사 클라우드인 AZURE를 통한 최적화도 수행했습니다.
Expreiments

정량적인 결과를 보면 의도한 대로 잘 작동하는 것을 볼 수 있습니다.
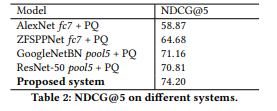

실험들이 더 많긴 한데, 두개만 가져와서 보자면 Bing에서 제안한 시스템의 성능이 다른 모델들에 비해 성능이 잘 나오는 것을 볼 수 있습니다. 그리고 아래 표를 보시면 엄청난 양의 이미지가 있는 것을 감안하면 속도도 매우 빠른 것을 확인할 수 있었습니다.
문제점이라고 볼 수는 있을지 모르겠지만, 결국은 이러한 visual search는 특정 회사가 보유한 데이터셋에 대한 성능으로 측정해서 비교는 어려운 것 같습니다.
결론
Visual search 자체가 각 회사들의 필요에 따라 만들어지다 보니, 비교가 어려운 것 같습니다. Pinterest나 ebay의 사례 등을 읽어봐도 아직 이 분야에 생소한 제가 보기 너무 어렵네요. 제가 파악하기로는 엔지니어링 관점에서 적용 가능한 신 기술이 많아 실무자들이 관심 있어하는 논문들인것 같습니다.