Before Review
정말 오랜만에 X-Review 인 것 같습니다. 바쁘다는 핑계로 X-Review 작성에 소흘했던 것 같습니다. 얼추 학기가 마무리되고 다른 일들도 마무리가 되어가니 다시 X-Review를 성실히 작성해야겠습니다. 이번 리뷰는 저번에 작성했던 Transformer 리뷰를 마무리 짓도록 하겠습니다. 저도 오랜만에 다시 보다보니 기억이 잘 안나서 지난번에 작성했던 리뷰를 간단하게 복기 하면서 시작하도록 하겠습니다.
Transformer and Encoder
Architecture

Transformer의 전체 구조 입니다. 크게 본다면 Encoder와 Decoder로 구성이 되어있고 각각의 Encoder와 Decoder는 같은 Layer로 구성되어 있지만 같은 Parameter를 공유하지는 않았습니다. Encoder를 보면 Multi-Head attention Layer와 Feed forward Layer로 구성이 되어있으며, 각 Layer를 거칠때 마다 Residual Connection으로 구성이 되어있습니다. 지난 리뷰에서는 Transformer의 구조와 Encoder에 대해서 알아봤습니다. Encoder에서 수행되는 Multi-Head Attention 개념은 Transformer의 정수라고도 볼 수 있으니 그 부분에 대해서 다시 한번 짚고 Decoder에 대해서 알아보도록 하겠습니다.
Encoder and Attention
- Transformer Encoder

Transformer의 Encoder는 크게 두개의 Sub-Layer로 구성되어 있습니다. Multi-Head Attention Layer와 Feed Forward Layer로 구성되어 있습니다. Multi-Head Attention Layer에서는 입력 문장들간의 dependency를 학습하게 되는 데 여러개의 헤드 즉, 여러개의 Linear Projection을 통해 더 깊은 Representation을 학습할 수 있다 볼 수 있습니다. Feed Forward Layer는 우리가 평소에 자주 쓰던 Linear Layer 2개를 가지고 있다. Multi-Head Attention Layer를 거친 Output을 입력으로 받아 원래 처음 Encoder에 들어왔던 입력과 같은 차원을 가지도록 만들어주는 역할을 합니다.
이렇게 두 Sub Layer로 구성된 Encoder를 N번 통과시켜주는 데 그 이유는 좀 더 높은 차원의 context를 이해하기 위해 여러 겹 통과 시킨다고 이해할 수 있습니다.
- Self Attention & Multi Head Attention
아마 Transformer에서 제일 중요한 핵심이라 볼 수 있는 데 자세한 설명은 지난 Part.1 리뷰에서 다루었으니 이번에는 간단히 서술만 하겠습니다. Attention을 준다는 것은 “어떠한 관계(dependency)를 이해하기 위해 가중치를 더해서 집중해보도록 하겠다.” 이렇게 이해할 수 있습니다. attention을 주는 방법은 여러가지가 있다고 하지만 본 논문에서는 scaled dot product attention을 기반으로 Transformer를 설계하였습니다.
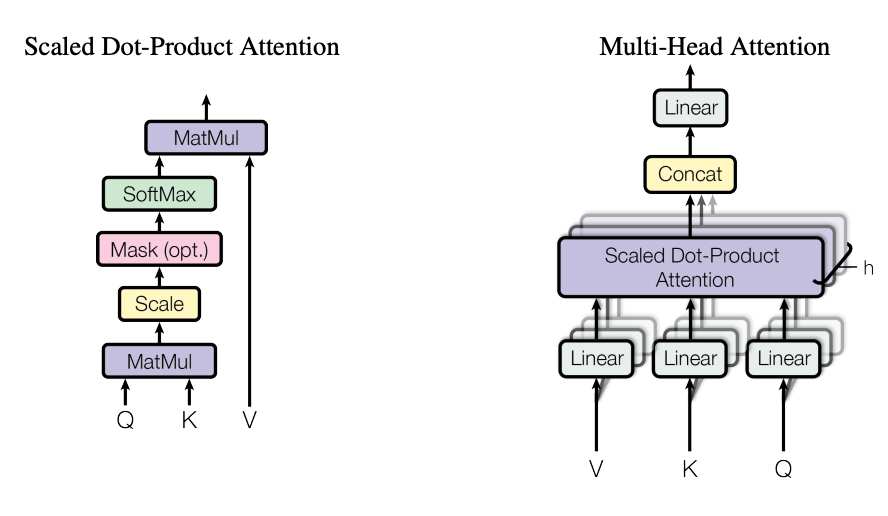
Encoder 부분에서는 입력 문장내에서 즉, 같은 문장 내에서의 의존성을 학습할 수 있도록 Attention이 설계되었습니다. 입력 Embedding Vector에 대해서 Linear Projection을 통해 Query , Key , Value라는 어떠한 Vector를 생성했습니다. Query와 Key 간의 행렬 곱을 통해 얻은 것을 우리는 Attention score 행렬이다! 이렇게 설계했습니다. 초기에는 원래의 목적성대로 attention이 잘 적용되지 않겠지만 학습이 이루어지면서 비슷한 context를 가지는 단어끼리 더 높은 attention이 적용되는 구조라 볼 수 있습니다.
Multi-Head Attention은 Scaled Dot-Product Attention을 독립적으로 여러번 수행하고 이를 Concat하고 다시 Linear Layer에 통과시키는 방법입니다. 지난 리뷰에서도 얘기했지만 이는 다른 관점을 가지고 context를 해석하기 위함 이라고 볼 수 있습니다.
“The animal didn’t cross the street because it was too tired.” 라는 문장이 있을 때 it이라는 단어를 해석하기 위해서 어디에 집중을 해야할까요?
it이 가리키고 있는 대명사인 The animal일까요 아니면 it의 상태를 나타내고 있는 was too tired일까요? 당연히 둘 다 중요합니다. 이렇듯 문장에서 단어와 단어 간의 관계는 하나의 헤드로 표현하기 힘들기 때문에 여러개의 Head를 가지고 Attention을 준다고 보시면 됩니다.
여기까지 해서 일단 간단하게 정리하는 것으로 하고 이제 Transformer Decoder와 Positional Encoding에 대해서 알아보도록 하겠습니다.
Positional Encoding
RNN이 자연어 처리에서 유용했던 이유는 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하는 RNN의 특성으로 인해 각 단어의 위치 정보를 가질 수 있다는 점에 있었습니다.
하지만 Transformer는 단어 입력을 순차적으로 받는 방식이 아니므로 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있습니다. 트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하는데, 이를 포지셔널 인코딩(positional encoding)이라고 합니다.

포지셔널 인코딩 벡터는 사인파와 코사인파로부터 얻을 수 있는데 수식은 아래와 같습니다.

pos와 i라는 변수가 무엇인지 그림을 통해 살펴보도록 하겠습니다.

pos는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, i는 임베딩 벡터 내의 차원의 인덱스를 의미합니다. 수식을 보면 임베딩 벡터의 차원이 홀수번째 차원이라면 코사인파를 사용하고 있고 착수번째 차원이라면 사인파를 사용하고 있습니다.
위와 같은 포지셔널 인코딩 방법을 사용하면 순서 정보가 보존되는데, 예를 들어 각 임베딩 벡터에 포지셔널 인코딩값을 더하면 같은 단어라고 하더라도 문장 내의 위치에 따라서 트랜스포머의 입력으로 들어가는 임베딩 벡터의 값이 달라집니다. 결국 트랜스포머의 입력은 순서 정보가 고려된 임베딩 벡터라고 보면 되겠습니다.
그렇다면 코사인 , 사인함수를 사용하는 이유는 무엇일까요? 그 이유는 다음과 같다고 합니다.
- 각각의 고유한 토큰의 위치값은 유일한 값을 가져하기 때문입니다.
- 서로 다른 두 토큰이 떨어져 있는 거리가 일정해야 하기 때문입니다.
- 서로 다른 길이의 시퀀스에 대해서 적용이 가능해야 하기 때문입니다.
더 깊게 들어가기엔 저의 이해력이 아직 받쳐주기 못하기 때문에 포지셔널 인코딩은 왜 하는지 어떻게 했는지 정도로만 파악하고 넘어가도록 하겠습니다.
Transformer Decoder
Decoder도 Encoder와 비슷한 구조를 가지고 있습니다. 하지만 다른 점이 두가지가 있습니다. 하나는 Encoder Decoder Attention Layer이고 하나는 Masked Multi-Head Attention Layer 입니다. Decoder 구조는 총 세개의 Sub-Layer로 구성이 되어있습니다. 그 중 Encoder Decoder Attention Layer와 Masked Multi-Head Attention Layer에 대해서 알아보도록 하겠습니다.

- Masked Multi-Head Attention
Transformer Decoder에서도 임베딩 입력을 받고 Positional Encoding을 한 후 입력 문장들끼리의 Attention을 계산합니다. 하지만 여기서 Masked Padding이라는 것을 도입하게 됩니다. 예를 들어 <sos> je suis étudiant 라는 임베딩 행렬을 한번에 입력으로 받았을 때 suis의 target 단어가 무엇인지 예측하는 상황이라 가정하겠습니다. Transformer의 Decoder에서는 현재 시점의 예측에서 현재 시점보다 미래에 있는 단어들을 참고하지 못하도록 즉, <sos> je 만 참고해서 suis을 예측할 수 있도록 Maksed-Attention을 수행합니다.

그림과 같이 미래 시점에 있는 단어간의 attention은 음의 무한대 값을 가지도록 설정하여 Masking 해주었다고 합니다.
- Encoder – Decoder Attention
위의 그림에서 빨간색으로 사각형으로 칠해진 부분이 Encoder-Decoder Attention Layer 입니다. 앞서 살펴봤지만 Attention을 할 때는 Query , Key , Value 행렬을 가지고 진행했었습니다. Encoder-Decoder Attention Layer 에서 Key , Value 행렬은 Encoder의 마지막 output을 가지고 만들어내는 반면 Query 행렬은 그 이전 Layer로 부터 가져옵니다. 즉 쉽게 말하면 서로 다른 문장간 단어들 끼리의 의존성을 학습한다고 보면 됩니다.

이렇게 독일어를 영어로 번역하는 작업을 진행한다고 할 때, 서로 다른 언어간의 Attention Score를 구해주는 Layer입니다.
여기까지 해서 Decoder를 알아보았습니다. 마지막으로 Transformer는 어떻게 output을 만들어내는지 까지 살펴보고 Decoder 설명을 마무리하도록 하겠습니다.
- Trasnformer Output
결국 Transformer는 분류 문제를 풀게 됩니다. 마지막 Decoder를 통과해서 나온 Feature를 가지고 지금 이 Feature가 학습하려고 하는 Target 단어중 어떤 것에 속하는 지 맞추는 Classification 문제를 풀게 됩니다.
그림에서 나와있는 vocab_size는 사전에 정의하는 값으로 우리가 학습하고자 하는 target 단어의 갯수입니다.
여기까지 해서 Transformer를 알아보았습니다. 이제 실험 부분을 살펴보고 리뷰 마치도록 하겠습니다.
Experiments
- Why Self Attention?

이 Table에서는 Self Attention을 왜 사용해야하는 지를 계산 복잡도 관점에서 설명하고 있습니다.
Self attention 기법과 Recurrent 기법 , Convolution 기법을 비교 하고 있습니다.
첫번째 비교는 Layer당 계산 복잡도 입니다. 일반적으로 문장의 길이 n이 임베딩 차원인 d 보다 작기 때문에 Recurrent 방식보다 Layer 당 계산 복잡도 낮다고 합니다.
그 다음으로는 직렬처리 연산입니다. Recurrent 계열의 방식은 입력을 순서대로 넣어줘야 하기 때문에 n개의 단어를 처리하려면 n번의 operation이 필요한 반면 Self attention기법은 한번에 행렬처리를 할 수 있기에 상수번의 operation만을 필요로 합니다. 그렇기에 병렬화가 가능한 computation이 늘어났고 더 빠른 처리를 할 수 있게 됩니다.
마지막으로 maximum path length 입니다. 이 maximum path length는 처음 보는 개념이었는데 단어들간의 의존성을 학습하는 데 있어 거쳐야하는 connection이 최대 몇 단계 인가를 나타내는 수치라고 합니다.
이 path의 길이가 짧을 수록 단어들 간의 의존성을 학습 하기 쉬워진다고 볼 수 있습니다.
본 논문 에서는 모든 단어들간의 attention을 한번에 주기 때문에 이 path의 길이가 1이라고 볼 수 있습니다.
RNN 같은 경우는 모든 의존성을 학습하기 위해서는 Sequence의 길이만큼 즉, n만큼 요구를 하고 있고 , CNN의 경우는 kernel 사이즈의 k일 때 logk(n) 만큼을 필요로 한다고 합니다.
테이블에는 나와있지 않지만 또 하나 중요한 사실은 Attention을 통해 어느정도 해석이 가능하기 때문입니다. Attention Score를 통해 단어를 인코딩 할 때 어디를 중요하게 봤는지를 히트맵 형식으로 표현이 가능해지기 때문에 해석 가능하다고 얘기합니다.
- Machine Translation
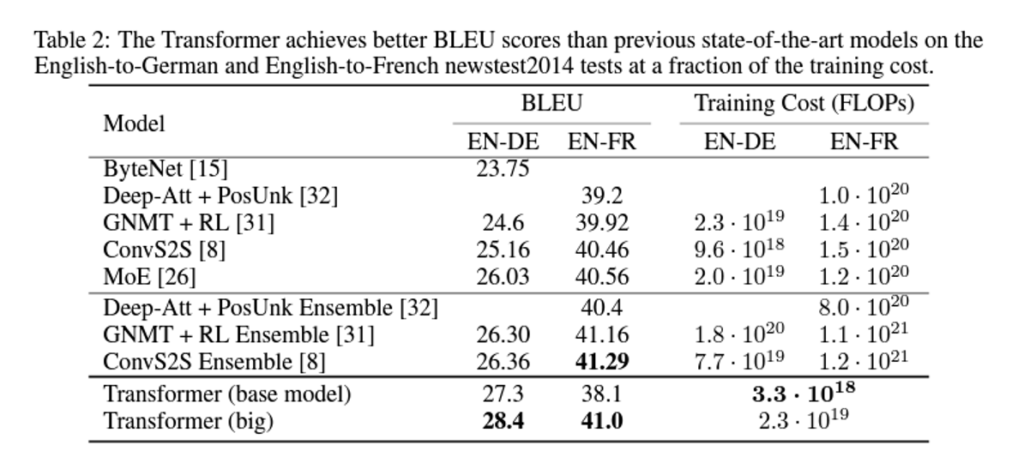
Metric으로 사용된 BLEU score는 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 방법입니다.
우선 , 영어 -> 독일어 번역 task에서는 SOTA를 달성 했다고 합니다. 영어 -> 프랑스어 번역에서는 ensemble 모델이 SOTA긴 하지만 충분히 비교할 만한 성능을 얻을 수 있었습니다.
무엇보다 중요한 것은 Training 연산량인데 제일 COST가 적었던 모델보다도 ¼ 정도로 COST가 적었다고 합니다.
연산량은 적게 가져가면서 성능은 SOTA 급이니 NLP에서 왜 transformer가 자연어 처리 분야에서 메인 스트림인지 얼추 짐작할 수 있을 것 같습니다.
Conclusion
사실 Transformer의 Contribution은 이 논문의 Citation이 말해주는 것 같습니다. 그래도 저자가 강조했던 Contribution을 다시 한번 정리해보면 Recurrent 나 Convolution 연산 없이 오로지 Attention 에만 의존하는 구조를 제안하였다는 점 입니다. 실험 부분에서도 연산 복잡도를 살펴보았지만 확실히 어텐션을 모든 위치에 대해서 한번에 줄 수 있다는 것이 연산량을 크게 줄일 수 있었습니다.
다르게 말하면 Matrix 연산 한번으로 처리할 수 있는 방법을 고안하여 병렬처리를 보다 더 용이하게 만들었고 학습 속도를 크게 단축 시킨 동시에 기계번역 부분에서 SOTA까지 달성한 그런 구조 였습니다.
Transformer를 이제야 조금 이해하게 됐습니다. 후속 연구도 정말 많고 Vision 분야에서도 연구가 적지 않게 이루어지고 있는 상황인데, 제가 찾아보고 있는 비디오 진영에서도 Transformer를 많이들 사용하고 있는 추세인 것 같습니다. 비디오 진영에서 Transformer를 사용하는 논문도 조만간 리뷰해보도록 하겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
positional encoding vector를 얻을 수 있는 수식에서 사인파와 코사인파를 사용한 이유가 각각의 고유한 토큰의 위치값은 유일한 값을 가져야하고, 서로 다른 두 토큰이 떨어져 있는 거리가 일정해야 하며, 서로 다른 길이의 시퀀스에 대해 적용이 가능해야 하기 때문이라고 하였는데, 사인 코사인 외에 다른 주기성 함수를 사용해도 앞에서 언급한 조건들이 만족하는지 궁금합니다.
또 차원을 짝수, 홀수에 따라 사인, 코사인을 구분지어 사용하는 이유가 있을까요 ?
감사합니다.
https://gaussian37.github.io/dl-concept-positional_encoding/
이거 이상으로 잘 설명되어 있는 곳이 없어 자료 올립니다.