이번에 리뷰할 논문은 기존과는 매우 다른 테스크에서 가져왔습니다. 이 논문은 영상 검색을 위해서 영상을 vector로 만드는 테스크입니다. 본 논문을 고른 이유는 현재 제가 하려고 하는 연구가 열화상 영상에서 예측된 깊이 영상과 칼라 영상에서 예측된 깊이 영상이 유사해지도록 하는 것인데 그떄 두 영상을 비교하는 방식을 어떻게 할까 고민하며 찾게 되었습니다. 제가 예전에 네이버 챌린지를 참여하며 영상 검색을 했을 때의 기억을 바탕으로 두 영상을 비교할때 단순히 픽셀끼리 비교하는 것이 아닌 image 2 vector 변환 모델을 통과 시킨 output(vector)끼리 비교하는 방식도 괜찮겠다는 생각으로 이 테스크쪽 서베이를 하게 되었습니다. 제가 follow up을 오랬동안 안했었던 테스크라서… 이론 부분이 미흡한 설명+ 오류 가 있을 수 있습니다.
- Introduction
image retrieval을 위해서 영상을 vector로 바꾸는 기존의 딥러닝 기반의 방법론들 Supervised 로 학습을 해야해서 성능이 좋더라도 방대한 데이터 셋에서는 사용하기 어려웠고, Unsupervised 방식의 quantization 같은 경우는 다양한 문제( end-to-end X) 로 인해서 많은 연구가 이뤄지지 않고 있었습니다.
따라서 본 논문에서는 처음으로 Unsupervised end-to-end deep quantizaiton 방법론을 제안합니다.
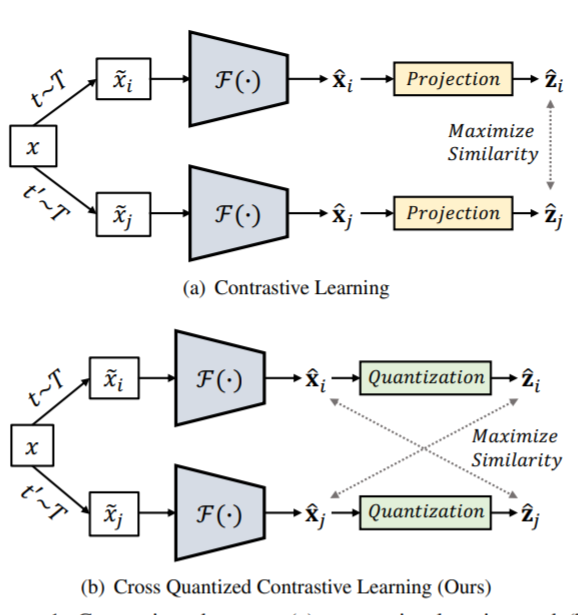
Self-supervised manner를 위해서 Contrastive learning을 도입했는데요, 위 그림과 같인 기존 contrastive learning같은 경우는 딥러닝 feature를 projection 시킨 vecotr 끼리 correlation을 높혔지만, 제안된 방법론은 딥러닝 feature와 codebook을 통해서 예측된 값의 유사도를 높여사 codebook 예측 학습과 feature 학습을 동시에 진행하므로 end-to-end로 학습이 됩니다.
2. Method
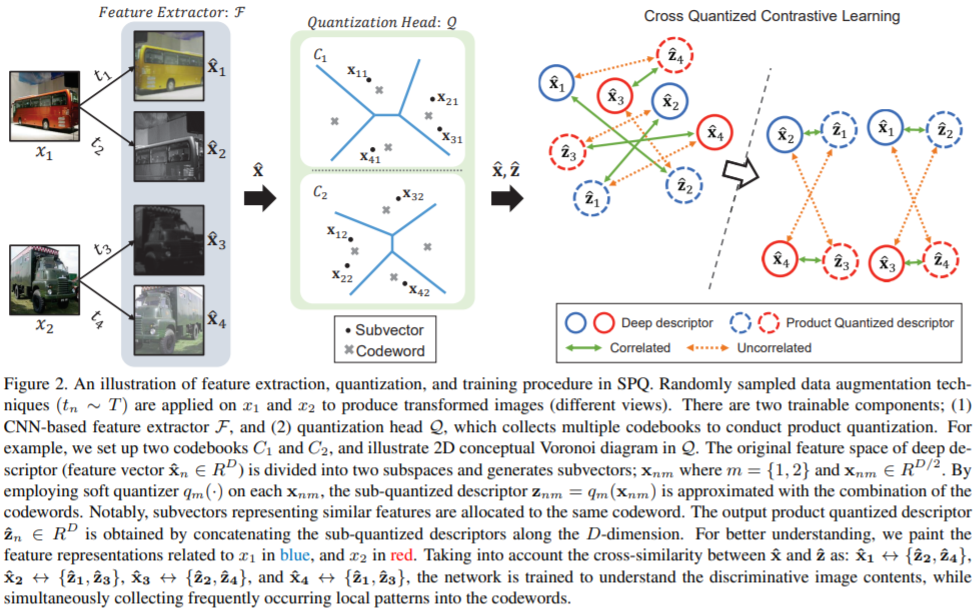
학습의 전체적인 파이프라인은 위와 같습니다. 기준 영상 x1을 augmentation 방법법론을 통해서 두개로 변환한 후 각각을 quantization 합니다. 그리고 기준영상 x2 또한 동일한 과정을 밟은 후 마지막 부분과 같이 기존 x1과 x2의 output들은 멀어지도록 기준 x1에서 나온 것들은 유사해지도록 학습을 해서 돌일한 컨텐츠를 담은 영상은 유사한 vector를 생성할 수 있도록 합니다.
Quantization
이때 quantization 의 방식은 아래 식과 같이
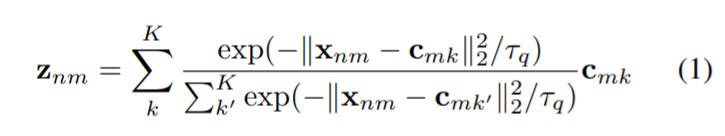
0~1 사이로 이뤄진 초기화된 codebook center( 학습 파라미터) 를 이용해서 다음과 같인 Soft assignment 와 같은 방식으로 계산을 해서 feature를 quantizaiotn 하게 된다. (틀릴 수 있음)
Self-Supervised
그리고 제안된 Crossquantized contrastive learning 에 대해 이야기 하자면 위 그림에서 설명한 것과 동일하게 동작하며 자기 자신에 대한 feature과 vector의 유사도를 높이는 것을 추가할경우 다른 벡터와의 계산을 무시해버려 학습을 방해하기 때문에 없앴다고 합니다.
Augmentation
기준영상에서 새로운 영상으로 만들때 사용한 augmentation은 resize, horizonflip, colorjitter, grayscale, gaussian blur를 랜덤하게 섞어서 사용했다고 합니다.
3.Experiments
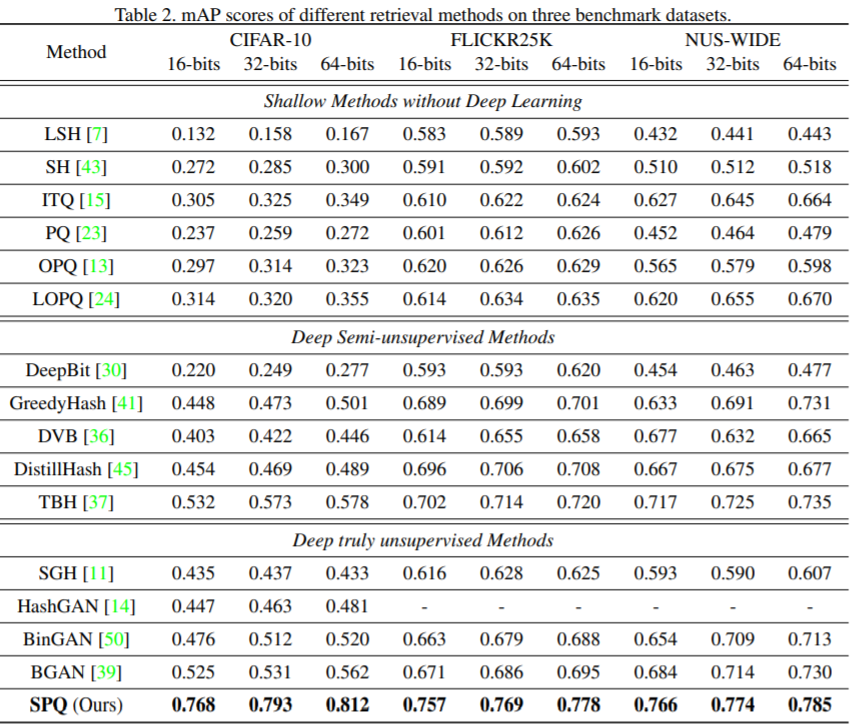
benckmark 에따라서 모든 방법론들의 성능 비교 입니다. 다른 방법론들과 비교해서 굉장히 높은 성능 향상을 볼 수 있습니다.
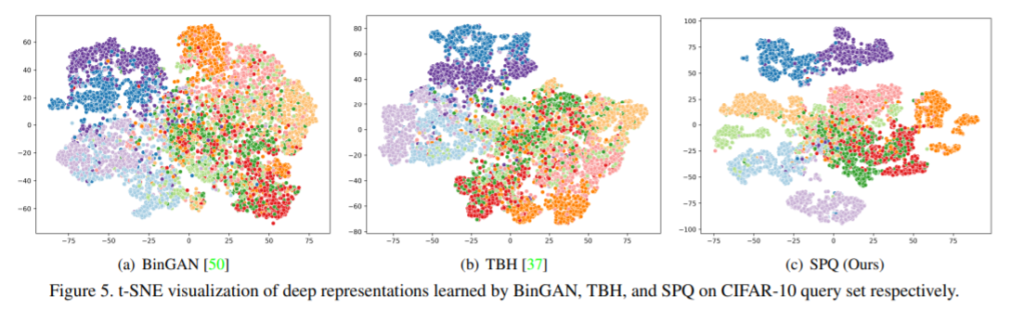
vector를 visualization 했을떄 결과 입니다. 보시면 다른 방법론들과 비교해서 굉장히 뚜렷하게 class 별로 분류하는 것을 볼 수 있습니다.
본 논문을 읽은 이유가 영상을 vector로 변환하는 방법론의 최근 워크 follow up이였었는데, 흠… 괜히 quantizaiton으로 고른 것 같습니다. 사실 제가 quantization 까지는 할 필요가 없어서… 다른 논문도 찾아봐야할 것 같습니다. 그래도 CSQ 다음으로 읽었던 quantization 논문이 생각보다 괜찮았던 것 같습니다. relative work를 잘 찾아서 다른 워크를찿으러 출발…
리뷰 잘 읽었습니다. 제가 궁금한 부분은
Quantization은 Retrieval Task에서 어떤 목적을 가지고 진행이 되는 것인가요?
단순하게 생각해봤을 때 성능을 올리기 위해서는 아닌 것 같은데 본 리뷰에서 Quantization을 하는 이유에 대해서 나와있지 않는 것 같아서 질문드립니다.
해당 논문을 읽으신 이유가 결국 ‘depth estimation을 위한 Encoder-Decoder 구조에서 RGB와 Thermal 각각 Ecoder 이후 나온 벡터가 유사(or 동일)하면 이후 Decoder에서 유사(or동일)하게 Depth를 잘 추론할 수 있다’라는 가정이 맞을까요? 그러면 질문은 결국 Thermal은 악조건의 조도환경에서도 Depth를 잘 추론하는게 장점이 될텐데, Thermal 영상이 악조건의 조도환경에서 Depth가 잘 추론되지 않는것도 배울수도 있을것 같은데 이러한 부분에서는 Thermal 영상에서 추출한 벡터가 선택적으로 RGB 벡터와 동일하도록 loss를 설계하시는건가요?