Temporal action proposal 생성을 하기 위해 제안된 방법인 BSN (Boundary-Sensitive Network)에 대해 소개하는 논문입니다. 간단히 말하면 액션의 경계에 좀 더 민감하게 반응하는 네트워크예요.
우선 Temporal action proposal이 필요한 이유부터 말하자면, 대부분의 Real-world 영상은 duration 이 길고, 액션이랑 상관 없는 콘텐츠 비중이 높은데요, 이로부터 action content 가 풍부한 부분을 알아내기 위함입니다. 즉, 비디오에서 어떤 행동이 시간적으로 어느 부분에 위치하는지 찾아서 제안(proposal)하는 것입니다.
이 문제는 아래 두 가지 방법을 필요로 합니다.
- 정확한 시간 경계 proposals 을 생성하는 것
- 상대적으로 적은 proposals 을 사용해서, recall 과 overlap 이 높은, truth action instances 를 커버할 수 있는 proposals 를 retrieve 하는 것
해당 논문에서는 이런 것들을 해결하기 위해서, 효과적인 proposal generation method 인 “BSN (Boundary-Sensitive Network)” 를 소개합니다. BSN은 “local to global” 방식을 채택했다고 합니다.
Locally
먼저 temporal boundary 일 확률이 높은 곳들을 찾고, 그 이후에 이걸 직접 결합한 것을 proposals 이라고 합니다.
Globally
그 후, Boundary-Sensitive Proposal feature 을 사용해서, 해당 proposal 의 region 안에 action 을 포함하고 있는지 아닌지에 대한 confidence 를 평가함으로써 proposals 을 retrieve 합니다.
이렇게 두 가지 방식을 거쳐서, action 을 포함하고 있는 temporal action proposal 을 만드는 것이죠.
이 논문에서는 두 개의 challenging dataset (AcitivityNet-1.3, THUMOS14) 에 대해 실험을 수행했습니다. 둘 다 에서 BSN 이 다른 SOTA temporal action proposal generation methods 보다 outperform 했음을 실험을 통해 알 수 있었다고 합니다.
마지막으로, existing action classifiers 를 BSN과 합치면 sota action detection performance 를 향상시킬 수 있을 것이라고 further experiments 설명하는 것으로 끝이 납니다.
abstract 에 나온 간략한 순서는 이렇습니다.
Introduction
서두는 다른 논문들과 비슷합니다. 카메라와 인터넷이 급속도로 잘 성장했고, 비디오가 엄청 늘어났고… 아무튼 그래서 자동적으로 비디오 컨텐츠를 분석해주는 방법에 대한 수요가 늘고 있는 상황입니다. 이 비디오 분석 분야에서 메인이 action recognition 인데요, 이건 trimmed video clips 이 어떤 action instance 를 포함하고 있는지 분류하는 것을 목적으로 하는 문제입니다. 실제 영상들은 보통 길고, untrimmed 이고, 여러 개의 action 인스턴스를 포함하고, 관련 없는 컨텐츠들도 포함되어 있습니다. 이런 이유들로 인해 temporal action detection 이 어려워집니다.
Spatial domain 의 Object detection 처럼, temporal action 또한 2개의 stage 로 나눌 수 있습니다. ‘Proposal’ 과 ‘Classification’ 으로요. Proposal stage 는 action 인스턴스를 포함하고 있는 temporal video regions 를 생성하는 것을 목적으로 하고, Classification stage 는 후보 proposals 의 class 를 분류하는 것을 목적으로 합니다.
성능이 좋은 proposals 이라면 아래의 두 가지 key properties 를 갖춰야 한다고 합니다.
- 높은 recall 과 overlap 으로 truth action regions 를 커버할 수 있어야 한다.
- 상대적으로 적은 수의 proposals 를 사용해서 1.을 달성해야 한다. (computation cost 를 줄이기 위해서!)
이렇게 좋은 성능을 달성하기 위해서, proposal 생성 메소드는 flexible 한 temporal durations 과 정확한 temporal boundaries 를 가진 proposal 을 생성하고, 그리고 그 중에 믿을만한 confidence scores 를 가진 proposal 을 retrieve 합니다. 이때, confidence score 는 해당 proposal 이 action 인스턴스를 포함하고 있을 확률을 나타내는 값이라고 합니다.
기존에 사용하던 proposal generation 메소드에는 drawback 이 있기에 이 논문에서는 해당 이슈를 해결하고 보다 퀄리티 높은 proposal 을 만들기 위해 BSN (Boundary-Sensitive Network)를 제안합니다. Locally 하게는 높은 확률의 boundaries 를 합쳐서 proposal 로 묶는 것이고, Globally 하게는 proposal-level feature 를 사용하여 candidate proposals 를 retrieve 하는 것이죠.
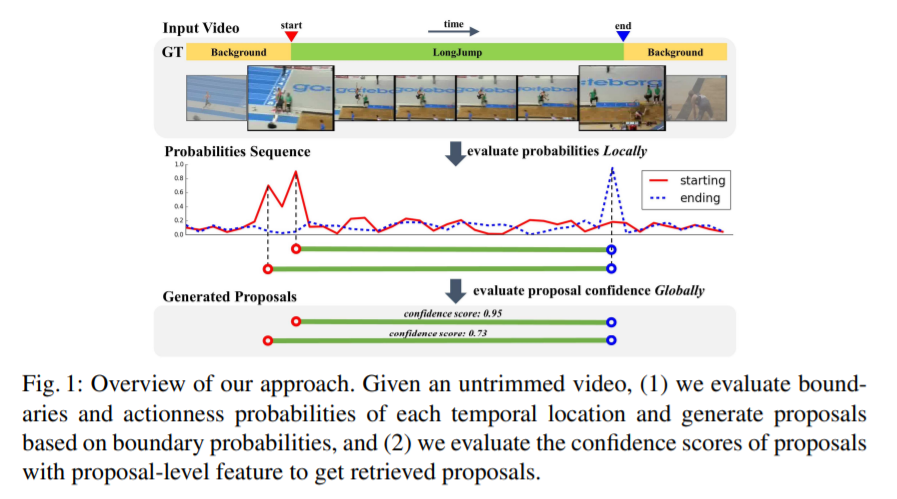
자세한 설명을 통해 한 번 이해해봅시다.
- BSN 이 비디오에 있는 각 temporal location 의 probabilities 를 평가합니다. starting, ending, actioness 일 확률 sequence 를 구하기 위해, 각 temporal location이 실내인지 외부인지, GT action 인스턴스의 boundary 에 있는지 아닌지에 평가하는 겁니다.
- 높은 starting probabilities 와 높은 ending probabilities 를 가진 temporal locations 를 직접적으로 합침으로써 proposals 를 생성합니다. 이런 bottom-up fashion 을 사용해서, BSN 은 flexible한 duration (
이게 왜 flexible 하다는 것인지는 아직 잘 모르겠는…!아 길이가 고정적인 게 아니라 flexible 하다고 표현한 듯 합니다.)과 정확한 boundary 를 가진 proposals 를 만들 수 있게 돼요. - proposal 주변의 actioness scores로 구성된 features 를 사용해서, BSN 은 proposals 를 retrieve 합니다. 이때, proposal 이 action 을 포함하고 있는지 아닌지에 대한 confidence 를 평가함으로써 retreive 하는 것입니다. 이런 proposal-level features 는 더 나은 evaluation 을 위한 global information 을 제공한다고 합니다.
Our Approach
Problem Definition
하나의 untrimmed video sequence 를 X = \{{x_n}\}^{l_v}_{n=1} 라고 정의합시다.
- 이때 X는 l_v 개의 frame 을 갖고, x_n 이 X 의 n번째 frame 입니다.
비디오 X에 대한 Annotation 은 action 인스턴스들의 집합인 {\Psi}_g = \{ {\varphi}_n = (t_{s,n}, t_{e,n}) \}^{N_g}_{n=1} 으로 이루어져 있습니다.
- 이때 N_g 은 비디오 X 에 있는 truth action 인스턴스들의 개수 입니다.
- 그리고 t_{s,n}, t_{e,n} 는 각각 action instance {\varphi}_n 의 starting time 과 ending time 입니다.
training 을 하는 동안에는, Annotation Set {\Psi}_g 이 사용됩니다.
prediction 을 하는 동안에는, 생성된 proposals set {\Psi}_p 가 {\Psi}_g 를 높은 recall 과 temporal overlap 으로 커버할 수 있어야 합니다.
( g 는 ground truth, p 는 proposal 인 것 같습니다. 즉, BSN 을 통해 생성한 proposal 이 실제 action 인스턴스의 ground truth 을 충분히 커버해야 된다는 뜻이라고 이해했습니다.)
Video Feature Encoding
input video 에 대한 proposals 를 생성하려면, 우선 video 의 feature 부터 뽑아서 비디오의 비주얼 컨텐츠를 encode 해야 합니다. 우리의 프레임워크에서는 two-stream network 를 visual encoder 로 사용했는데요, 이 architecture 는 action recognition task 에서 좋은 성능을 보이고, temporal action detection 과 proposal generation tasks 에서도 널리 사용되고 있다고 합니다.
Two-stream network 는 2개의 branch 를 포함합니다. Spatial network 는 appearance feature 를 capture 하기 위해 single RGB frame 에 대해 작동을 하고, Temporal network 는 motion information 을 capture 하기 위해 stacked optical flow field 에 대해 작동을 합니다. (여기서 optical flow란, ‘광학 흐름’ 이라는 말인데, 영상 내에 있는 물체의 움직임 패턴을 뜻합니다.)
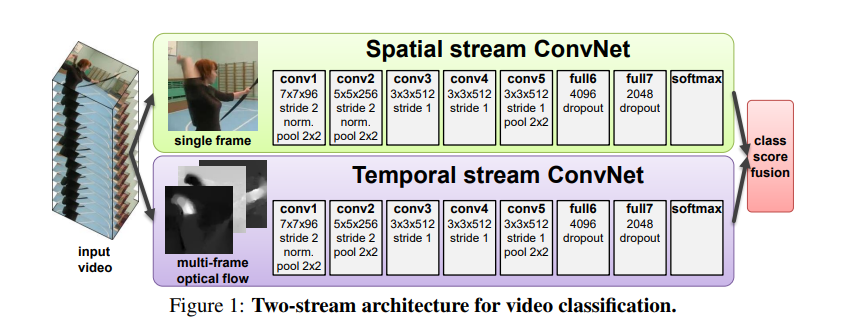
다른 논문에서 two-stream network 에 대해 찾아본 내용입니다.
Video 는 Spatial components 와 Temporal components 로 나눠질 수 있다고 합니다. Spatial part 는 개별적인 frame 의 모습을 하고 있고, video 에 묘사된 장면과 물체에 대한 정보를 담고 있습니다. 반면 Temporal part 는 여러 frame 동안 걸쳐져 있는 motion 의 모습을 하고 있고, 관찰자 (camera)와 물체의 움직임에 대한 정보를 담고 있습니다.
따라서 이에 걸맞게 video recognition architecture 을 2개의 stream 으로 고안해낸 것이 two-stream network 입니다!
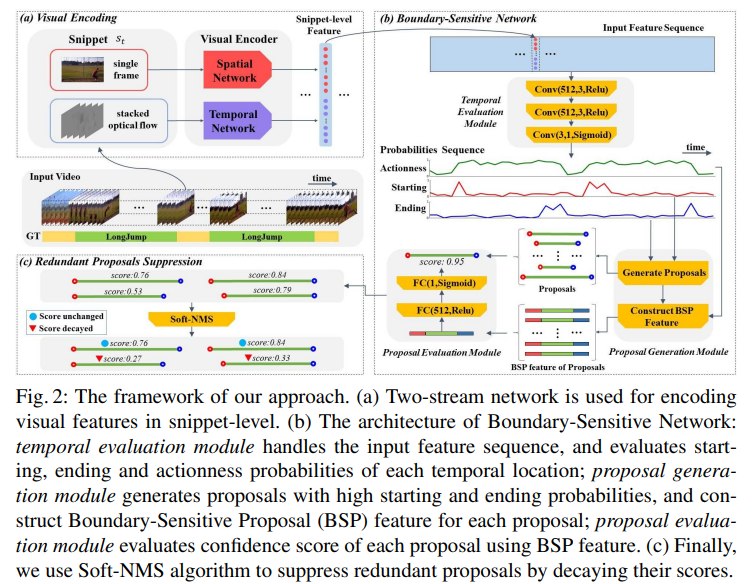
다시 돌아와서, two-stream features 를 뽑으려면 video X 로부터 S = \{s_n\}^{l_s}_{n=1} 이라는 snippets sequence 를 만들어야 합니다. 이때 l_s 는 snippets sequence 의 길이를 뜻합니다. snippet s_n = (x_{t_n} , o_{t_n}) 에서, x_{t_n} 는 비디오 X 의 t_n 번째 RGB 프레임을 뜻하고, o_{t_n} 는 center frame x_{t_n} 의 주변으로부터 추출된 stacked optical flow field 를 뜻합니다.
이때, computation cost 를 줄이기 위해, regular frame interval \sigma 로 snippets 를 추출합니다. 즉, 비디오 X가 l_v 개의 프레임을 가진다고 했으니까, l_s = l_v / \sigma 가 되는 것이죠!
s_n 이 주어졌을 때, spatioal 과 temporal network 둘 다의 top layer 의 output scores 를 concat 해서 encoded feature vector f_{t_n} = (f_{S, t_n}, f_{T, t_n}) 를 만듭니다. 이때, f_{S, t_n}, f_{T, t_n} 는 spatial network 와 spatial network 각각의 output scores 입니다.
l_s 길이의 sequence S snippets 가 주어졌을 때, feature sequence F = {f_{t_n}}^{l_s}_{n=1} 를 추출할 수 있습니다. 이 two-stream feature seqences 들이 BSN 의 input 으로 쓰입니다.
Boundary-Sensitive Network
precise 한 temporal boundaries 와 reliable 한 confidence scores 를 가진 high proposal quality 를 얻기 위해, “local to global” 이라는 방법을 사용하여 proposals 를 만들었습니다. BSN 에서, (1) locally 하게 candidate boundary locations 를 만들고, (2) 이 locations 를 proposals 로 combine 해서, (3) 각 proposal 를 proposal-level feature 에 대해 confidence score 를 evaluate 합니다. (1) ~ (3) 순서대로 모듈 순서대로 보면 되겠습니다.
Network architecture :
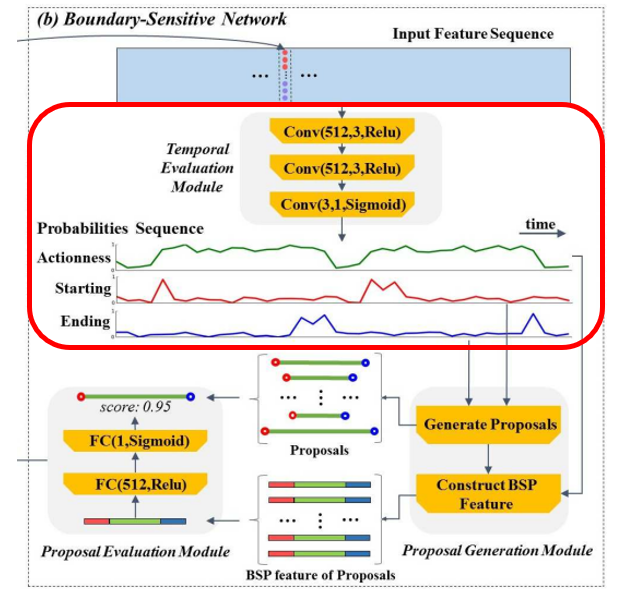
- Temporal evaluation module – (1)
- 3개의 layer 로 이루어진, temporal convolutional nerual network
- two-stream feature sequence 를 input 으로 받는다.
- 비디오의 각 temporal location 에 대한 probabilities 를 evaluate 한다.
(inside/outside, ground truth action instances 의 boundary 인지 아닌지) - -> starting, ending , actionness 에 대한 확률의 sequences 를 각각 만든다. (즉, 3개의 이진 분류기 필요)
- ———————————————————————————
- temporal convolutional layer 는 Conv(c_f, c_k, Act) 로 정의되는데, 괄호 안의 변수는 각각 filter 갯수, kernel size, actionvation function 을 뜻한다.
- 이 모듈은 Conv(512, 3, Relu) → Conv(512, 3, Relu) → Conv(3, 1, Sigmoid) 이고, stride 는 다 1이다.
- 마지막 layer 에서 c_f = 3 이고 Act = Sigmoid 잖아. 이게 classifer 로 사용이 되어서, satrting, end, actionness 에 대한 probability 를 각각 생성할 수 있는 것이다.
- 계산의 편의성을 위해, feature sequence 를 non-overlapped windows 로 나눈 것을, 해당 모듈의 input 으로 사용한다.
- Feature sequnce = F 라고 하면, 이 모듈은 세 개의 probability sequences,
P_S = \{p^s_{t_n}\}^{l_s}_{n=1}, P_E = \{p^e_{t_n}\}^{l_s}_{n=1}, P_A = \{p^a_{t_n}\}^{l_s}_{n=1} 를 생성한다.
이때 p^s_{t_n}, p^e_{t_n}, p^a_{t_n}, 는 각각 t_n 시간에서의 starting, ending, actionness 확률들이다.
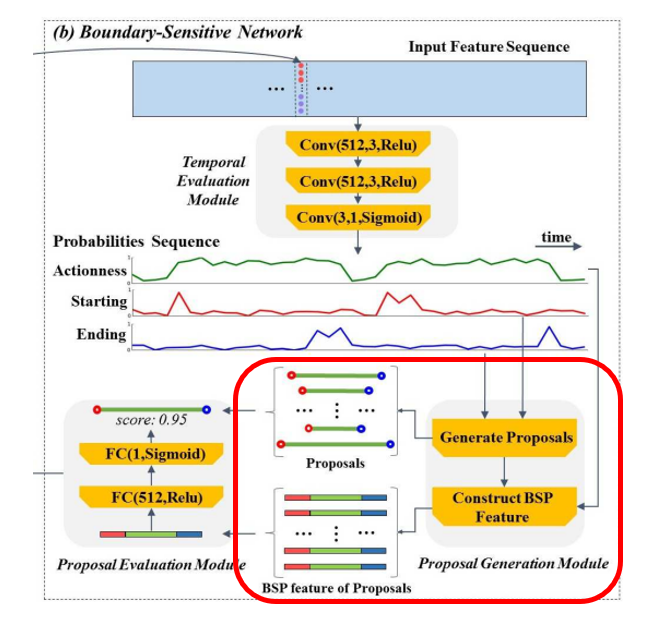
- Proposal generation module – (2)
- (2-1) starting 확률과 ending 확률이 높은 temporal locations 를 combine 해서 candidate proposals 로 만든다.
- (2-2) -> 각각의 candidate proposal 의 actioness 확률 sequence 를 기반으로 Boundary-Sensitive Proposal (BSP) feature 를 만든다.
- ———————————————————————————
- (2-1) P_S 에 대해, p^s_{t_n} 이 0.9 이상이거나, 주변에 비해 높은 peak 인 시간 t_n 을 찾아서 모두 기록한다.
- 이 위치 기록들을 그룹 지어서, candidate starting locations set 인 B_S = \{t_{s,i}\} 를 만든다. 이때 N_S 는 candidate starting locations 의 수이다.
- 같은 방식으로 B_E 와 P_E 를 만든다.
- 그 이후에, B_S 의 t_s 와 B_E 의 t_e 도 만든다.
- 이를 이용한 temporal region [t_s, t_e] 를 candidate proposal φ 라고 한다.
- 따라서, candidate proposals set 인 ψ_p = \{φ\}^{N_p}_{i = 1} 이다. 이때 N_p는 proposals 의 수이다.
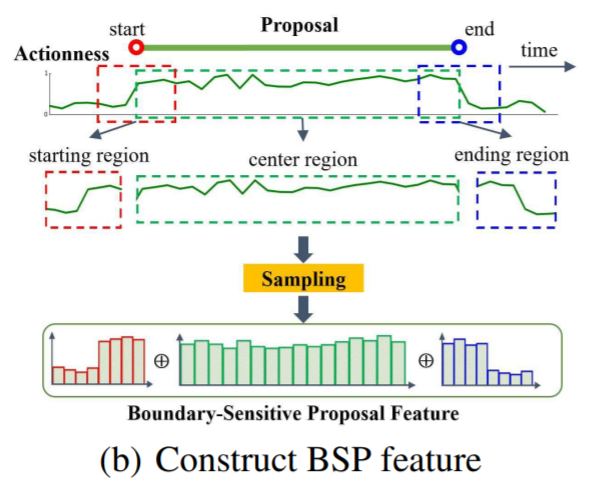
- (2-2) candidate proposal φ에 대해, ceter region 을 r_C = [t_s, t_e] 로 정의하고, starting region 을 r_S = [t_s - d/5, t_s + d/5] , ending region 을 r_E = [t_e - e/5, t_e + d/5] 로 정의한다.
- r_C 안의 actionness sequence P_A 를, 16 points 로 linear interpolatoin 적용해서 샘플링한걸 f^A_c 라고 한다.
- starting 하고 region 은 8 points 로 적용해서, 각각 f^A_s, f^A_e 라고 한다.
- 이 벡터들을 concat 하면, 우리가 원하는, φ의 BSP feature인 f_{BSP} = (f^A_s, f^A_c, f^A_e) 를 얻을 수 있다.
- 이 BSP feature 는 엄청 compact 하고, correspongding proposal 에 대한 풍부한 semantic한 정보를 포함하고 있다.
- 이로 인해, 우리는 proposal 을 φ= (t_s, t_e, f_{BSP}) 로 나타낼 수 있게 된다.
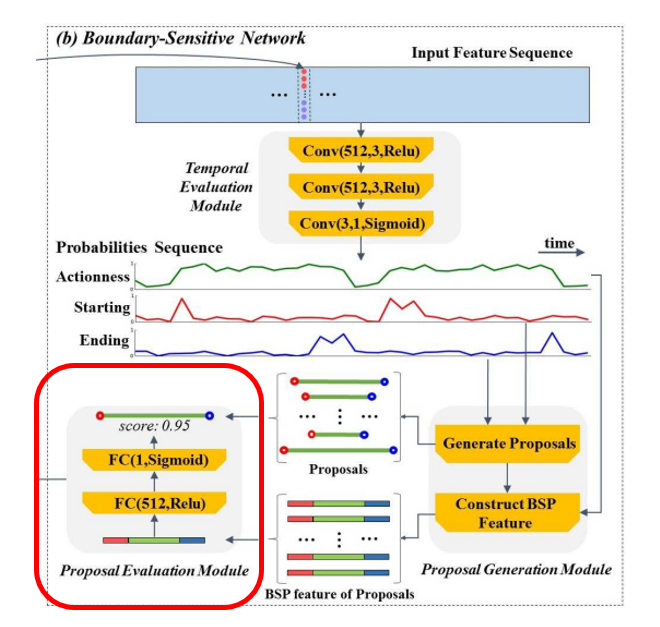
- Proposal evaluation module – (3)
- 하나의 hidden layer 를 가진 multi-layer perceptron model 이다.
- BSP feature 를 기반으로, 각 candidate proposal 의 confidence score 를 evaluate 한다.
- 각 proposal 의 confidence score 와 boundary probabilities 는 fused 돼서, retrieving 에 필요한 final confidence score 로 fuse 된다.
- ———————————————————————————
- 이때, hidden layer 는 512 units 을 가졌고, 이는 BSP feature 를 input 으로 받아서 , Relu activation 을 취한다.
- output layer 는 sigmoid activation 을 통해, confidence score 인 p_{conf} 를 내보내는데, 이 값은 candidate proposal 과 ground truth action instances 의 overlap extent 를 측정한 것이다.
- 따라서, 우리는 proposal 을 φ= (t_s, t_e, p_{conf}, p^s_{t_s}, p^e_{t_e}) 로 다시 나타낼 수 있게 된다. 이때 p^s_{t_s} 와 p^e_{t_e} 는 각각 t_s 와 t_e 에서의 starting, ending probabilities 를 뜻한다.
- 방금 표현한 값들이 fused 돼서 final score 를 만들게 된다.
Training
- temporal evaluation module : 비디오 features 로부터 local boundary 와 actionness probabilities 를 동시에 학습
- Proposal generation module : 1로부터 나온 probablities sequence 를 기반으로 proposals 와 BSP features 를 생성
- proposal evaluation module : proposals 의 confidence score 를 학습
(디테일은 생략하겠습니다! 논문을 참고해주세요)
Prediction and Post-processing
예측은 proposals set \psi_p = \phi_n = (t_s, t_e, p_{conf}, p^s_{t_s}, p^e_{t_e})\}^{N_p}_{n=1} 로 나옵니다.
final proposals set 을 찾으려면, 우선 (1) final confidence score 를 찾아야 하고, (2) 해당 score 를 기반으로 redundant 한 proposals 를 suppress 해줘야합니다.
- (1) : p_f = p_{conf} * p^s_{t_s} * p^e_{t_e}
- (2) : Soft-NMS 알고리즘 사용
Experiments
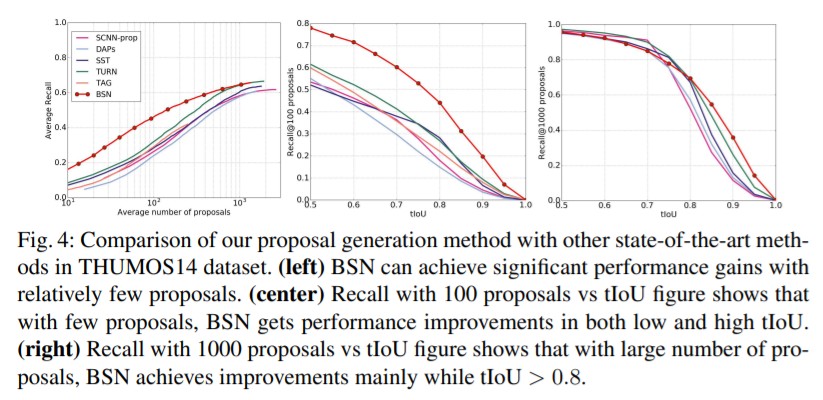
이 결과를 보면, proposals 의 수가 적을 수록 성능 향상이 많이 됐습니다. 이는 상대적으로 적은 수의 proposals 를 사용하는 게 좋다는, 앞서 언급한 조건과 적합합니다.
또한 여러 테이블들을 보면 Activitiy-net / AR@AN, AUC 으로 했을 때 proposal generation methods 중에 sota 이고, THUMOS14 , AR@AN 으로 했을 때 대체적으로 sota 입니다.
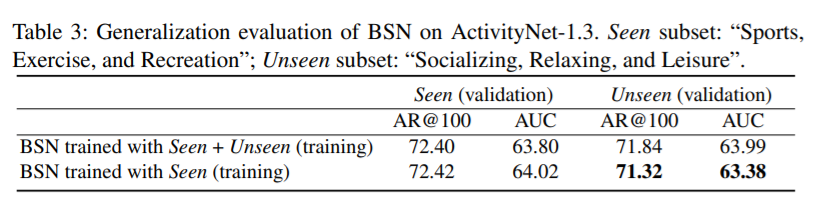
그 외에도 Generalization evaluation 을 위해 seen/unseen subject 에 대해서도 했는데, 성능이 크게 변화하지 않았습니다. 이는 BSN 이 unseen actions 에서도 잘 한다, generalizability 를 갖고 있음을 알 수 있었습니다.
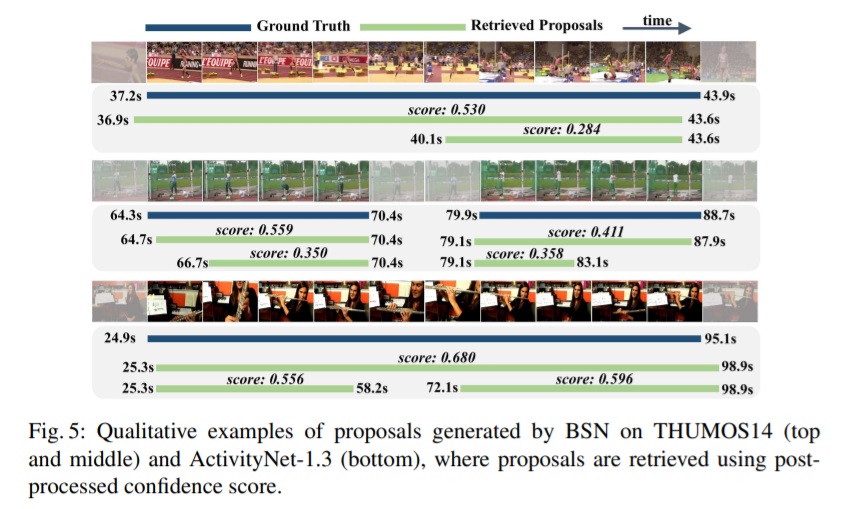
요약
- temporal action proposal generation 하는 Boundary-Sensitive Network (BSN)
- 높은 boundary probabilities 를 가진 locations 를 합치는 방식으로 인해
- flexible 한 duration 과 precise 한 boundaries 를 가진 proposals 를 만들 수 있다!
논문 링크
BSN: Boundary Sensitive Network for Temporal Action Proposal Generation