이번 X-review에서 제가 소개해드릴 논문은 YOLOv4이며 해당 논문은 이전 김지원 연구원에 의해 리뷰된적이 있습니다. 좀 더 자세히 작성하는걸 목표로 할 것이고, 해당 x-review를 기반으로 아듀세미나에서도 튜토리얼급으로 발표할 예정입니다.
제가 해당 논문을 튜토리얼급으로 발표하게된 계기는 해당논문을 이해하면 object detection 분야에서 상당히 많은 것들을 이해할 수 있기 때문입니다.
먼저 해당 논문은 reference가 102개 입니다. 그만큼 광범위한 내용을 다루며, 엄청나게 많은 실험을 합니다.
본론으로 들어가서 해당논문에서 제안하는 YOLOv4 아키텍쳐의 궁극적인 목표는 누구나 다 object detection을 할수 있게 진입장벽을 낮추자 입니다. 다른말로 하자면, 싱글 GPU만으로도 충분히 working하고 compromising한 성능을 달성하는 것이 해당 저자의 목표이며 주요 contribution입니다.
먼저 해당 논문을 이해하기위해 잠깐 YOLOv1~v3를 리뷰하는 시간을 갖겠습니다.
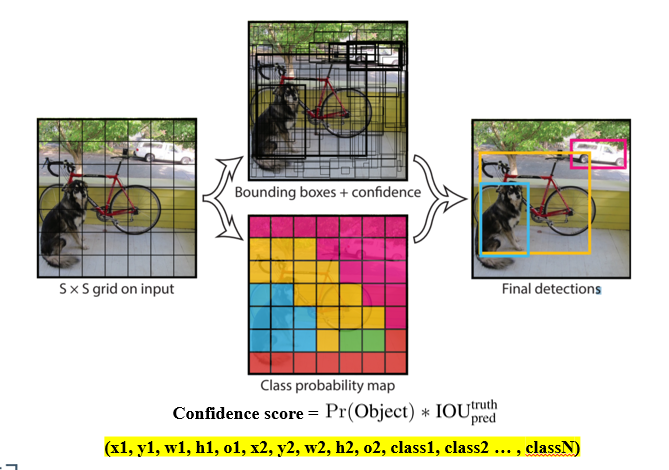
욜로 1에서는 위와같이 S x S 그리드맵을 구하고 각 그리드셀마다 bbox에 대한 정보와 object score, class score를 구하는데요.
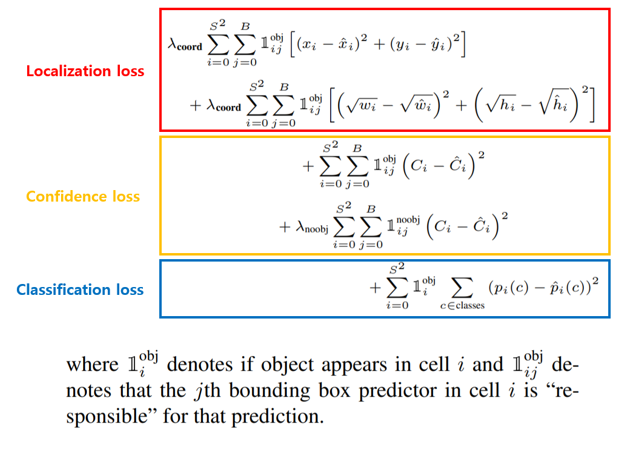
이 때 학습은 위와 같은 loss로 진행됩니다. 해당 식이 의미하는 바는 모든 그리드셀에 존재하는 bbox에 대해서 confidence loss 및 localization loss를 계산하고, 그리드셀에 대해서는 classification loss를 계산한다는 것 인데요, 더 자세한 수식적인 내용에 대한 설명은 제가 x-review에서 다룬적도 이전에 있으며, 이번 아듀때 더 자세하게 소개하겠습니다.
YOLOv2
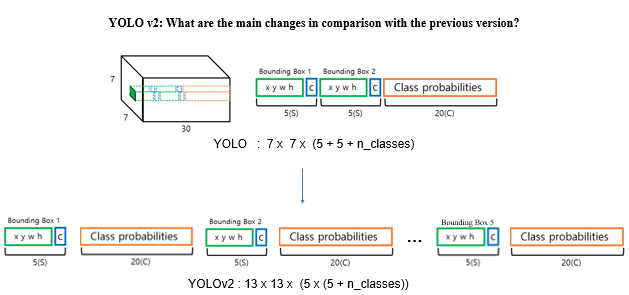
욜로 v1에서 좀 더 개선시켜 yolov2를 발표를 하였는데요. 해당 아키텍쳐에서는 anchor box각각마다 object score를 가진다는 점에서 v1과는 차이가 있습니다.

loss는 공식적으로 원저자가 다루지는 않으며 추정한 loss를 일본인 누군가가 작성을 해둔게 google에 돌아다니는데요. iou loss가 추가된것을 볼 수 있으며 그 외의 내용은 YOLOV1과 비슷합니다.
그 밖에도 V2에서는 아래그림처럼 Subpixel에 대한 offset값을 sigmoid를 태워서 0~1사이로 고정합니다.
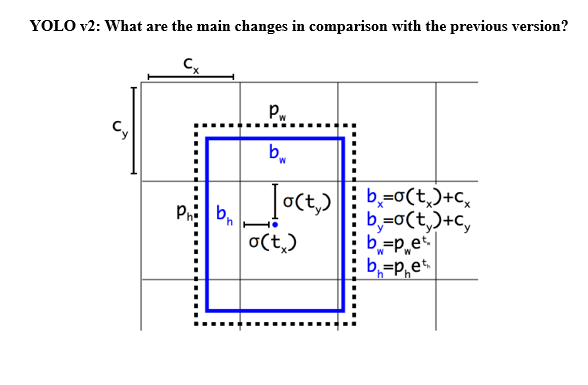
위의 수식에 대한 자세한 의미도 아듀에서 다루는걸로 하겠습니다.
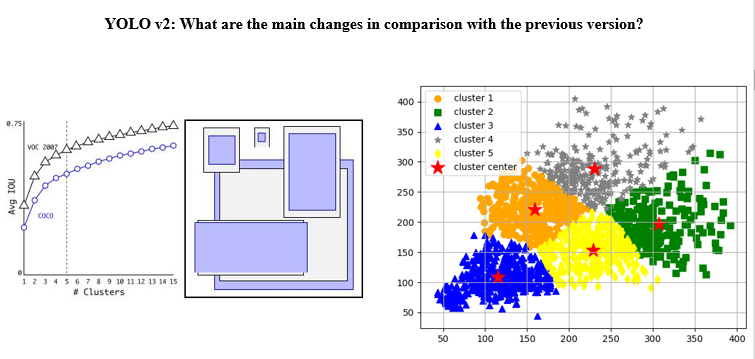
또한 v2부터는 k-means clustering을 통한 anchor box 선정이 이루어집니다. 좀 더 정확히는, 단순 w, h 뿐만이아닌 iou를 고려해서 anchor box를 구합니다.
YOLOv3
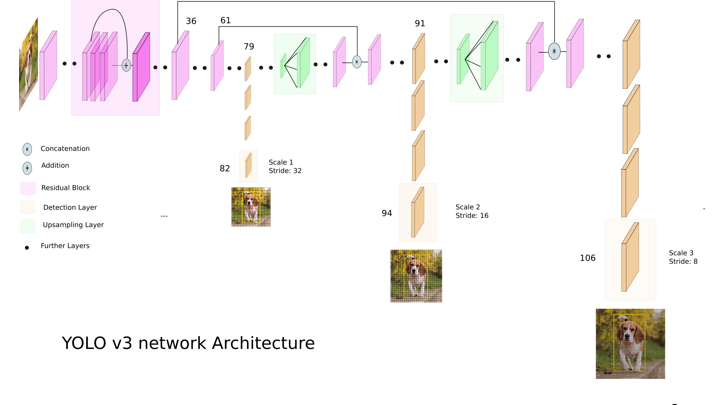
v2와 다르게 v3부터는 FPN구조를 사용합니다. 그리드맵의 해상도도 달라지고 3개의 그리드맵을 이용합니다.
여기까지 v1~v3까지 main 변화들을 중심으로 살펴보았습니다.
그럼 대망의 V4에 대해서 이야기해보겠습니다.
YOLOv4는 레퍼런스만 102개입니다. 그만큼 실험이 정말정말 다양한데 모든 실험에 대해 다 이해하면 object detection을 공부하는데 많은 도움이 된다고 생각합니다.
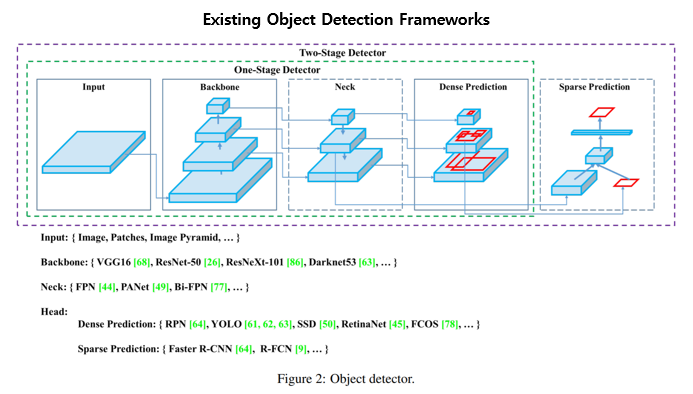
먼저 해당논문에서는 기존 존재하는 object detection 프레임워크를 위와같이 나누어서 보았습니다.

그리고 해당 부분들에 대한 현존하는 방법론들을 소개합니다. 그러한 방법론들의 조합중에서 어떠한 detector가 최적의 detector인지를 찾는게 일단 해당 논문의 실험 목표이며 다양한 실험을 통해 해당 논문에서는 아래와 같은 구조로 구성된 최종 아키텍쳐를 발표합니다.
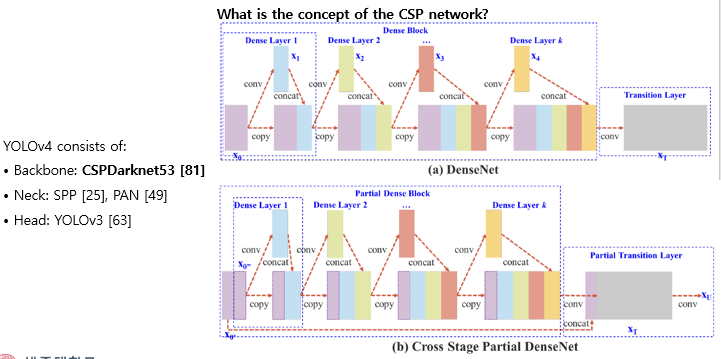
먼저 제안된 아키텍쳐는 CSP 백본을 사용합니다. CSP 백본에서는 gradient연산이 중복되는 이슈를 다룹니다. 위와같이 계속 복사되는 부분의 일부만을 사용함으로써 computation time은 줄이고, 성능은 오히려 올랐다고 리포팅합니다. V4에서는 이러한 CSP구조의 darknet을 백본으로 사용합니다.
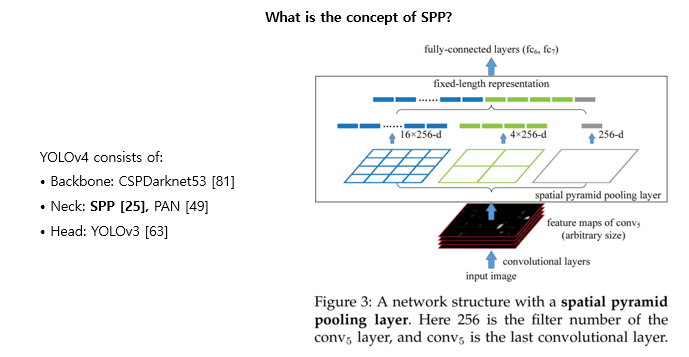
다음으로는 SPP입니다. SPP는 CNN 피쳐를 pooling을 통해 위의 그림처럼 fixed length의 1D vector로 만들어줍니다. 해당 방법은 2015년에 Kaiming He에 의해 제안되었으며, 비슷한 원리로 CNN에도 SPP를 적용할 수 있습니다. 해당 V4에서는 이러한 CNN기반의 SPP 모듈을 사용합니다.
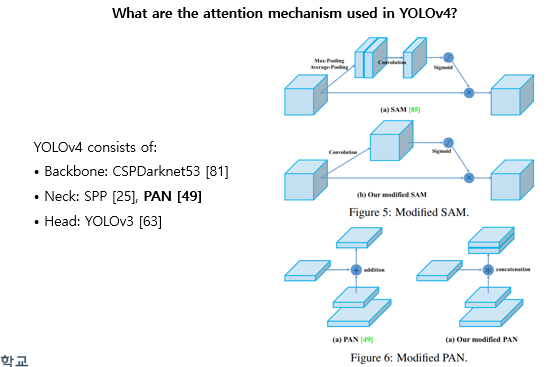
또한 v4에서는 위의 그림처럼 atttention module을 일부 변경하여 사용합니다. 요새 attention 모듈을 많이 보았는데 사실 뭐가 정답인진 모르겠으나, 해당 논문에서는 기존 SAM attention을 channel-wise attention에서 point-wise attention으로 바꾸어서 사용합니다. PAN에서는 기존 element-wise summation 에서 concatenate로 바꾸어서 사용합니다.

Head는 V3 버전과 동일하게 FPN구조를 그대로 사용합니다.
이 밖에도… YOLOv4가 좋은 논문임을 보이는건 이제부터 시작입니다.
해당 논문에서는 기존에 존재하는 object detection에 사용되는 technical한 부분들을 위와같이 정의합니다. 즉, freebies, specials로 나누어서 설명하는데 각각의 차이점은 freebie는 computation time의 증가 없이 성능에 영향을 줄 수 있는 방법론들이고, specials는 computation time에도 영향을 주어서 trade-off관계를 잘 생각해봐야 하는 방법론들입니다.
해당 논문에서는 위와같이 새로운 wording을 정의하여 그룹핑하여 그에 맞게 실험하였습니다.

예를들어 위의 표처럼 실험을 하여서 많은 경우의수를 고려하였습니다. 참고로 여기서 Mosaic은 해당 논문에서 제안하는 방법론으로 4개의 이미지에서 패치를 뽑아내서 1개의 이미지를 합성해내는 augmentation 기법입니다. 해당 augmentation 기법을 활용함으로써 occlusion에 좀 더 강인하게 모델을 학습시킬수 있었다고 합니다.
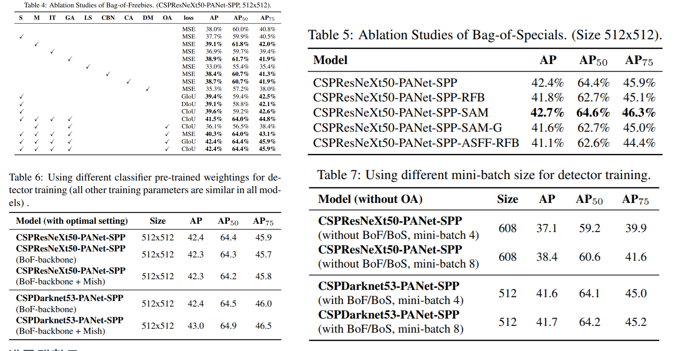
비슷한 맥락에서의 실험들인데 좀 특이한것은 바로 Table 7입니다. 해당 테이블에서는 일반적인 상식과 다르게 YOLOV4에서 제안하는 방법들을 조합하여 모델을 설계하면 Batch size의 크기가 성능에영향을 거의 안 미친다고 말하고 있습니다. 이러한 이유로 single GPU에서도 충분히 모델을 학습및 추론할 수 있고, object detection을 좀더 general하게 만들었다는 점에서 contribution을 가집니다. 사실 제가 느끼기로는 저자는 애초에 처음부터 batch size에 영향을 안타는 모델을 설계하고자 목표했던걸로 생각되진 않습니다. 아마도 수많은 실험을 반복적으로 하였고, 이후에 의미부여를 하지 않았을까요? 그래도 어찌보면 batch size를 올렸는데도 성능상승이 없었다고 낙담하는게 아니라 의미부여를 잘했다고 생각합니다. 이처럼 연구는 selling하는 스킬도 많이 중요한거 같습니다.
리뷰 감사합니다.
Yolo 모델이 그리드 단위로 작동하는 것 같은데 혹시 그리드를 구하는 과정이 어떻게 되나요? 그림상으로는 픽셀값이 아닌듯 하여 여쭈어 봅니다.
최종적인 output 피쳐를 grid map이라고 합니다. 예를들어 욜로 v1에서는 coco 데이터셋 기준으로 7x7x(8+1+80) 이 최종적인 피쳐맵으로 나옵니다. 이때 해당 피쳐맵을 7×7 그리드맵이라고 하며, 각각 한개의 그리드셀은 (8+1+80)의 채널정보를 가지고 있습니다. 여기서 채널정보에는 2개의 bbox에대한 x1,y1,w1,h1,x2,y2,w2,h2 값과 object score, class probability 80개를 포함합니다.