이번에는 TensorRT를 적용한 모델을 C++에서 사용하는 방법에 대해서 이야기하고자 합니다. 이전에 포테닛에서는 qmake를 사용하였는데, 이번에는 gcc를 이용하여 진행할 예정입니다.
https://github.com/NVIDIA/Torch-TensorRT
우선 1편에서 위의 깃허브를 통해 TensorRT를 적용한 모델을 Torchscript를 통해서 저장이 가능하며, Torchscript으로 저장한 모델은 C++로 불러올 수 있다고 이야기드렸습니다. 이번 리뷰에서는 해당 부분에 대해서 진행할 예정입니다. (이번편에서도 동일하게 MLPD에 적용한 예시입니다.)
- C++ 파일을 생성할 폴더를 만듭니다. (ex. mkdir cpp_scr)
2. 해당 폴더에서 라이브러리를 모아둘 dep 폴더와 main.cpp , Makefile을 만듭니다.
3. 우선 dep 파일에는 tensorrt release 버전과 libtorch를 다운받아 압축을 해제합니다.

libtorch는 pytorch 공식 홈페이지에서 다운받을 수 있습니다. (저는 cxx11 ABI 로 다운받았습니다.)
torch_tensorrt는 ‘https://github.com/NVIDIA/Torch-TensorRT/releases’ 에서 받을 수 있습니다.
모두 다운받고 압축을 풀면 이제 main.cpp를 작성합니다.
#include <iostream>
#include <fstream>
#include <memory>
#include <sstream>
#include <vector>
#include "torch/script.h"
int main(){
std::string trt_ts_module_path = "/workspace/MLPD-torchscript/cpp_src/MLPD_trt_torchscript_module.ts";
torch::jit::Module trt_ts_mod;
try {
trt_ts_mod = torch::jit::load(trt_ts_module_path);
std::cout<<"Model Loaded"<<std::endl;
} catch (const c10::Error& e) {
std::cerr << "error loading the model from : " << trt_ts_module_path << std::endl;
return -1;
}
}
다음으로는 Makefile을 작성합니다.
CXX=g++
DEP_DIR=$(PWD)/deps
INCLUDE_DIRS=-I$(DEP_DIR)/libtorch/include -I$(DEP_DIR)/torch_tensorrt/include
LIB_DIRS=-L$(DEP_DIR)/torch_tensorrt/lib -L$(DEP_DIR)/libtorch/lib # -Wl,-rpath $(DEP_DIR)/tensorrt/lib -Wl,-rpath /usr/local/cuda-11.4/lib64
LIBS=-Wl,--no-as-needed -ltorchtrt_runtime -Wl,--as-needed -ltorch -ltorch_cuda -ltorch_cpu -ltorch_global_deps -lbackend_with_compiler -lc10 -lc10_cuda
SRCS=main.cpp
TARGET=trt_test
$(TARGET):
$(CXX) $(SRCS) $(INCLUDE_DIRS) $(LIB_DIRS) $(LIBS) -o $(TARGET)
clean:
$(RM) $(TARGET)이러한 Makefile이 있으므로 make를 통해서 실행하면 ‘trt_test’라는 object 파일(?)이 만들어집니다. (Makefile은 여러분들 docker 만들때처럼 그냥 명령어를 한번에 입력하게 쉽게 사용한다고 생각하시면 됩니다.)

만들어진 ‘trt_test’를 ‘./trt_test’로 실행하면 모델을 로드할 수 있습니다.
이제 해당 모델에 입력으로 들어갈 이미지를 불러오기위해서 Opencv를 다운로드 받아야합니다.
https://webnautes.tistory.com/1479?category=704653
해당사이트에서 Opencv를 설치하는 방법에 대해서 설명하고 있는데, NGC는 CuDNN, Cuda 모두 포함하는 컨테이너이므로 OpenCV 설치파트만 참고하시면 됩니다.

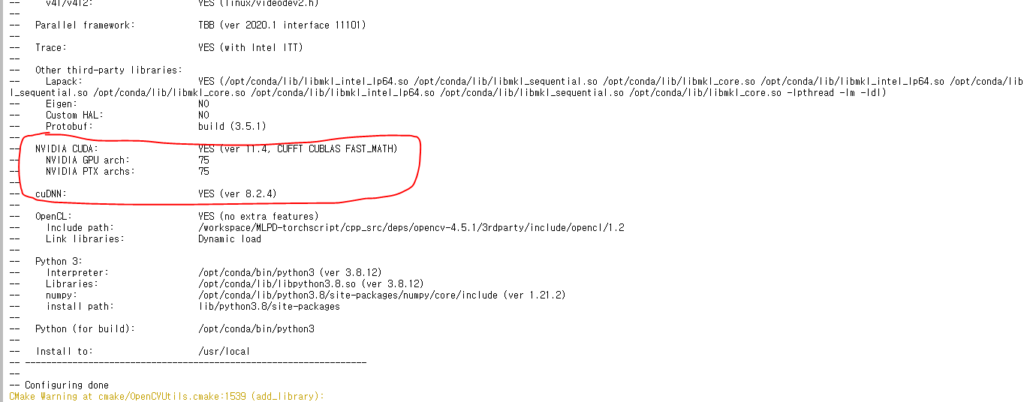
해당 부분부터 OpenCV를 설치할 수 있는데, NGC 컨테이너를 사용하는경우 CuDNN의 경로가 기존과 다르게 설정되어 있습니다. 따라서 make를 진행할때 실행하는 명령어를 다음과 같이 수정해주어야 합니다. 또한 기존 도커에 python3가 설치되어 있으므로 이를 유지하기위한 설정도 해줘야 합니다. [참고사이트]
cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D INSTALL_PYTHON_EXAMPLES=ON -D INSTALL_C_EXAMPLES=ON -D BUILD_DOCS=OFF -D BUILD_PERF_TESTS=OFF -D BUILD_TESTS=OFF -D BUILD_PACKAGE=OFF -D BUILD_EXAMPLES=OFF -D WITH_TBB=ON -D ENABLE_FAST_MATH=1 -D CUDA_FAST_MATH=1 -D CUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda -D WITH_CUDA=ON -D WITH_CUBLAS=ON -D WITH_CUFFT=ON -D WITH_NVCUVID=ON -D WITH_IPP=OFF -D WITH_V4L=ON -D WITH_1394=OFF -D WITH_GTK=ON -D WITH_QT=OFF -D WITH_OPENGL=ON -D WITH_EIGEN=ON -D WITH_FFMPEG=ON -D WITH_GSTREAMER=ON -D BUILD_JAVA=OFF -D BUILD_opencv_python3=ON -D BUILD_opencv_python2=OFF -D BUILD_NEW_PYTHON_SUPPORT=ON -D OPENCV_SKIP_PYTHON_LOADER=ON -D OPENCV_GENERATE_PKGCONFIG=ON -D OPENCV_ENABLE_NONFREE=ON -D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib-4.5.1/modules -D WITH_CUDNN=ON -D OPENCV_DNN_CUDA=ON -D CUDA_ARCH_BIN=7.5 -D CUDA_ARCH_PTX=7.5 -D CUDNN_LIBRARY=/usr/lib/x86_64-linux-gnu/libcudnn.so.8 -D CUDNN_INCLUDE_DIR=/usr/include -D PYTHON_EXECUTABLE=/opt/conda/bin/python3 -D PYTHON3_INCLUDE_DIR=/opt/conda/include/python3.8 -D PYTHON3_NUMPY_INCLUDE_DIRS=/opt/conda/lib/python3.8/site-packages/numpy/core/include -D PYTHON3_PACKAGES_PATH=/opt/conda/lib/python3.8/site-packages -D PYTHON3_LIBRARY=/opt/conda/lib/libpython3.8.so -D PYTHON_LIBRARIES=/opt/conda/lib/python3.8 .. 아래 cuDNN 설정 경로를 확인하시고, ARCH의 경우도 블로그에서 설명하듯 GPU에 맞게 설정해야합니다. 2080Ti의 경우 7.5이며 이는 예제와 동일합니다. 이렇게 빌드를 진행하면 다음과 같이 cuDNN에 Yes를 확인하시면 됩니다.
확인이 됐다면 블로그대로 다음 단계로 넘어갑니다.

모든 과정이 마무리되면 위의 그림과 같이 끝납니다. 이제 설치됐는지 확인해봐야 하는데요.

해당 블로그에서는 아래와같이 확인하라고 하지만 저희는 앞서 만든 Make file에 이를 추가하여 사용할 예정입니다. 이를 위해서 $(pkg-config opencv4 –libs –cflags) 를 통해 경로를 확인합니다.

‘-I/usr/local/include/opencv4’ 라느걸 확인할 수 있으니, 이를 Makefile에 추가합니다.
CXX=g++
DEP_DIR=$(PWD)/deps
INCLUDE_DIRS=-I$(DEP_DIR)/libtorch/include -I$(DEP_DIR)/torch_tensorrt/include -I/usr/local/include/opencv4
LIB_DIRS=-L$(DEP_DIR)/torch_tensorrt/lib -L$(DEP_DIR)/libtorch/lib -L/usr/local/lib # -Wl,-rpath $(DEP_DIR)/tensorrt/lib -Wl,-rpath /usr/local/cuda-11.4/lib64
LIBS=-Wl,--no-as-needed -ltorchtrt_runtime -Wl,--as-needed -ltorch -ltorch_cuda -ltorch_cpu -ltorch_global_deps -lbackend_with_compiler -lc10 -lc10_cuda -lopencv_core -lopencv_imgcodecs -lopencv_highgui
SRCS=main.cpp
TARGET=trt_test
$(TARGET):
$(CXX) $(SRCS) $(INCLUDE_DIRS) $(LIB_DIRS) $(LIBS) -o $(TARGET)
clean:
$(RM) $(TARGET)INCLUDE_DIRS를 추가했으니, 이제 main.cpp도 수정하여 정상적으로 불러와지는지 확인합니다.
#include <iostream>
#include <fstream>
#include <memory>
#include <sstream>
#include <vector>
#include <opencv2/opencv.hpp>
#include <opencv2/core.hpp>
#include "torch/script.h"
int main(){
std::string trt_ts_module_path = "/workspace/MLPD-torchscript/cpp_src/MLPD_trt_torchscript_module.ts";
torch::jit::Module trt_ts_mod;
try {
trt_ts_mod = torch::jit::load(trt_ts_module_path);
std::cout<<"Model Loaded"<<std::endl;
} catch (const c10::Error& e) {
std::cerr << "error loading the model from : " << trt_ts_module_path << std::endl;
return -1;
}
cv::Mat original_img,img_T,img_R;
}
다음과 같이 수정하여 실행하면

정상적으로 실행되며 ‘cv::Mat’ 도 불러올 수 있음을 확인할 수 있습니다. 자 그럼 이제 해당 코드에서 main.cpp를 제대로 수정하여서 MLPD의 결과를 출력해보겠습니다.
#include <iostream>
#include <fstream>
#include <memory>
#include <sstream>
#include <vector>
#include <opencv2/opencv.hpp>
#include <opencv2/core.hpp>
#include "torch/script.h"
using namespace std;
using namespace cv;
using namespace torch::indexing;
torch::Tensor create_prior_boxes(){
map<string,float> fmap_dims[2];
fmap_dims[0]["conv4_3"]=80;
fmap_dims[0]["conv6"]=40;
fmap_dims[0]["conv7"]=20;
fmap_dims[0]["conv8"]=10;
fmap_dims[0]["conv9"]=10;
fmap_dims[0]["conv10"]=10;
fmap_dims[1]["conv4_3"]=64;
fmap_dims[1]["conv6"]=32;
fmap_dims[1]["conv7"]=16;
fmap_dims[1]["conv8"]=8;
fmap_dims[1]["conv9"]=8;
fmap_dims[1]["conv10"]=8;
map<string,float> scale_ratios[3];
scale_ratios[0]["conv4_3"]=1.;
scale_ratios[0]["conv6"]=1.;
scale_ratios[0]["conv7"]=1.;
scale_ratios[0]["conv8"]=1.;
scale_ratios[0]["conv9"]=1.;
scale_ratios[0]["conv10"]=1.;
scale_ratios[1]["conv4_3"]=(float)pow(2,1/3.);
scale_ratios[1]["conv6"]=(float)pow(2,1/3.);
scale_ratios[1]["conv7"]=(float)pow(2,1/3.);
scale_ratios[1]["conv8"]=(float)pow(2,1/3.);
scale_ratios[1]["conv9"]=(float)pow(2,1/3.);
scale_ratios[1]["conv10"]=(float)pow(2,1/3.);
scale_ratios[2]["conv4_3"]=(float)pow(2,2/3.);
scale_ratios[2]["conv6"]=(float)pow(2,2/3.);
scale_ratios[2]["conv7"]=(float)pow(2,2/3.);
scale_ratios[2]["conv8"]=(float)pow(2,2/3.);
scale_ratios[2]["conv9"]=(float)pow(2,2/3.);
scale_ratios[2]["conv10"]=(float)pow(2,2/3.);
map<string, float> aspect_ratios[2];
aspect_ratios[0]["conv4_3"]=(float)1/2;
aspect_ratios[0]["conv6"]=(float)1/2;
aspect_ratios[0]["conv7"]=(float)1/2;
aspect_ratios[0]["conv8"]=(float)1/2;
aspect_ratios[0]["conv9"]=(float)1/2;
aspect_ratios[0]["conv10"]=(float)1/2;
aspect_ratios[1]["conv4_3"]=1.;
aspect_ratios[1]["conv6"]=1.;
aspect_ratios[1]["conv7"]=1.;
aspect_ratios[1]["conv8"]=1.;
aspect_ratios[1]["conv9"]=1.;
aspect_ratios[1]["conv10"]=1.;
map<string, double> anchor_areas;
anchor_areas["conv4_3"]=40*40.;
anchor_areas["conv6"]=80*80.;
anchor_areas["conv7"]=160*160.;
anchor_areas["conv8"]=200*200.;
anchor_areas["conv9"]=280*280.;
anchor_areas["conv10"]=360*360.;
string fmaps[6]={"conv4_3", "conv6", "conv7", "conv8", "conv9", "conv10"};
double cx,cy;
double h,w,anchor_h,anchor_w;
string fmap_i;
torch::Tensor prior_boxs = torch::rand({41760,4});
int numbers=0;
for(int fmap =0 ; fmap<6;fmap++){
fmap_i=fmaps[fmap];
for(int i=0;i<fmap_dims[1][fmap_i];i++){
for(int j=0;j<fmap_dims[0][fmap_i];j++){
cx=(j+0.5)/fmap_dims[0][fmap_i];
cy=(i+0.5)/fmap_dims[1][fmap_i];
for(int s=0;s<1;s++){
for(int ar =0;ar<2;ar++){
h=sqrt(anchor_areas[fmap_i]/aspect_ratios[ar][fmap_i]);
w=aspect_ratios[ar][fmap_i]*h;
for( int sr =0;sr<3;sr++){
anchor_h=h*scale_ratios[sr][fmap_i]/512.;
anchor_w=w*scale_ratios[sr][fmap_i]/640.;
prior_boxs[numbers][0]=cx;
prior_boxs[numbers][1]=cy;
prior_boxs[numbers][2]=anchor_w;
prior_boxs[numbers][3]=anchor_h;
numbers++;
}
}
}
}
}
}
return prior_boxs;
}
torch::Tensor cxcy_to_xy(torch::Tensor cxcy){
return torch::cat({cxcy.slice(1,0,2) - (cxcy.slice(1,2) / 2),cxcy.slice(1,0,2) + (cxcy.slice(1,2) / 2)}, 1);
}
torch::Tensor gcxgcy_to_cxcy(torch::Tensor gcxgcy,torch::Tensor priors_cxcy){
torch::Tensor a,b,c;
a=torch::mul(gcxgcy.slice(1,0,2),priors_cxcy.slice(1,2))/10+priors_cxcy.slice(1,0,2);
b=torch::exp(gcxgcy.slice(1,2)/5)*priors_cxcy.slice(1,2);
return torch::cat({a,b},1);
}
torch::Tensor find_intersection(torch::Tensor set_1,torch::Tensor set_2){
torch::Tensor lower_bounds,upper_bounds,uml,intersection_dims;
lower_bounds=torch::max(set_1.slice(1,0,2).unsqueeze(1),set_2.slice(1,0,2).unsqueeze(0));
upper_bounds=torch::min(set_1.slice(1,2).unsqueeze(1),set_2.slice(1,2).unsqueeze(0));
uml= (upper_bounds-lower_bounds);
intersection_dims=uml.clamp(0);
return intersection_dims.slice(2,0,1)*intersection_dims.slice(2,1,2);
}
torch::Tensor find_overlap(torch::Tensor set_1,torch::Tensor set_2){
torch::Tensor intersection,areas_set_1,areas_set_2,union_;
intersection=find_intersection(set_1,set_2);
areas_set_1 = (set_1.slice(1,2,3) - set_1.slice(1,0,1)) * (set_1.slice(1,3,4)- set_1.slice(1,1,2)) ;
areas_set_2 = (set_2.slice(1,2,3) - set_2.slice(1,0,1)) * (set_2.slice(1,3,4)- set_2.slice(1,1,2)) ;
union_=areas_set_1.unsqueeze(1) + areas_set_2.unsqueeze(0) - intersection;
return intersection / union_;
}
// For Multiclass NMS
torch::Tensor detect_objects(torch::Tensor predicted_locs,torch::Tensor predicted_scores,torch::Tensor priors_xy,double min_score,double max_overlap,int top_k){
torch::Tensor out_boxes_total,out_scores_total;
torch::Tensor decode_loc,class_scores ,score_above_min_score;
int n_above_min_score;
int classnum = 2;
decode_loc=cxcy_to_xy(gcxgcy_to_cxcy(predicted_locs[0],priors_xy));
predicted_scores = predicted_scores.sigmoid();
// (RGB score + Thermal score) / 2 : mean score
predicted_scores.index_put_({Slice(),Slice(),1},(predicted_scores.index({Slice(),Slice(),1}) + predicted_scores.index({Slice(),Slice(),2}))/2);
predicted_scores = predicted_scores.index({Slice(),Slice(),Slice(None,2)});
// shape
// decode_loc : 41760,4
// predicted_score : 1,41760,2
for(int classname=1;classname<classnum;classname++)
{
class_scores=predicted_scores[0].slice(1,classname,classname+1);
score_above_min_score=class_scores>min_score;
n_above_min_score=score_above_min_score.sum().item<int>();
if(n_above_min_score==0)
{
torch::Tensor out=torch::zeros({1,5}).to(at::kCUDA);
out[0][2]=1.;
out[0][3]=1.;
if(classname==1)
{
out_boxes_total=out.slice(1,0,4);
out_scores_total=out.slice(1,4,5);
}
continue;
}
torch::Tensor suppress;
torch::Tensor out_boxes,out_scores;
auto order_t=std::get<1>(class_scores.sort(0,true));
auto class_sorted=class_scores.index_select(0,order_t.squeeze(-1));
torch::Tensor decode_loc_sorted=decode_loc.index_select(0,order_t.squeeze(-1));
class_sorted=class_sorted.slice(0,0,n_above_min_score);
decode_loc_sorted=decode_loc_sorted.slice(0,0,n_above_min_score);
auto overlap=find_overlap(decode_loc_sorted,decode_loc_sorted);
//NMS
suppress=torch::zeros((n_above_min_score)).to(at::kCUDA);
for(int box=0;box<decode_loc_sorted.size(0);box++){
if(suppress[box].item<int>()==1){
continue;
}
torch::Tensor what=overlap[box]>max_overlap;
what=what.to(at::kFloat);
auto maxes=torch::max(suppress,what.squeeze(1));
suppress=maxes;
suppress[box]=0;
}
suppress=1-suppress;
// in python out_boxes=decode_loc_sorted[suppress]
auto indexing=torch::nonzero(suppress);
out_boxes=decode_loc_sorted.index_select(0,indexing.squeeze(-1));
out_scores=class_sorted.index_select(0,indexing.squeeze(-1));
if(classname==1){
out_boxes_total=out_boxes;
out_scores_total=out_scores;
}
else{
out_boxes_total=torch::cat({out_boxes_total,out_boxes},0);
out_scores_total=torch::cat({out_scores_total,out_scores},0);
}
}
return torch::cat({out_boxes_total,out_scores_total},1);
}
// string split
vector<string> split(string str, char delimiter) {
vector<string> internal;
stringstream ss(str);
string temp;
while (getline(ss, temp, delimiter)) {
internal.push_back(temp);
}
return internal;
}
at::Tensor Normalize(at::Tensor img,int what){
at::Tensor normimg,tensor_img_R_R,tensor_img_R_G,tensor_img_R_B;
if(what==0){
normimg=img.div_(255.).sub_(0.1598).div_(0.0813);
}
else{
tensor_img_R_R=img.slice(1,0,1);
tensor_img_R_G=img.slice(1,1,2);
tensor_img_R_B=img.slice(1,2,3);
tensor_img_R_R=tensor_img_R_R.div_(255.).sub_(0.3465).div_(0.2358);
tensor_img_R_G=tensor_img_R_G.div_(255.).sub_(0.3219).div_(0.2265);
tensor_img_R_B=tensor_img_R_B.div_(255.).sub_(0.2842).div_(0.2274);
normimg=torch::cat({tensor_img_R_R,tensor_img_R_G,tensor_img_R_B},1);
}
return normimg;
}
int main(){
c10::InferenceMode guard;
std::ifstream file2("/raid/datasets/kaist-rgbt/imageSets/test-all-20.txt");
std::string str;
std::string imgname_T,imgname_R;
std::string trt_ts_module_path = "/workspace/MLPD-torchscript/cpp_src/MLPD_trt_torchscript_module.ts";
torch::jit::Module trt_ts_mod;
try {
trt_ts_mod = torch::jit::load(trt_ts_module_path);
std::cout<<"Model Loaded"<<std::endl;
} catch (const c10::Error& e) {
std::cerr << "error loading the model from : " << trt_ts_module_path << std::endl;
return -1;
}
// warmup
std::vector<torch::jit::IValue> trt_inputs;
trt_inputs.push_back(at::randint(-5, 5, {1, 3, 512, 640}, {at::kCUDA}).to(torch::kHalf));
trt_inputs.push_back(at::randint(-5, 5, {1, 1, 512, 640}, {at::kCUDA}).to(torch::kHalf));
trt_ts_mod.forward(trt_inputs);
// define
int i = 1;
int width = 640;
int height = 512;
at::Tensor tensor_img_T;
at::Tensor tensor_img_R;
std::vector<int64_t> dimsR{1,512,640,3};
std::vector<int64_t> dimsT{1,1,512,640};
cv::Mat original_img,img_T,img_R, img_T_G;
string eval_path="/workspace/MLPD-torchscript/cpp_src/eval.txt";
ofstream writefile(eval_path.data());
torch::Tensor priors_xy,after_nms,detect_loc,detect_score;
auto original_dims = torch::tensor({width,height,width,height}).unsqueeze(0).to(at::kFloat).to(at::kCUDA);
priors_xy=create_prior_boxes();
priors_xy=priors_xy.to(at::kCUDA);
while (std::getline(file2, str))
{
vector<string> line_vector = split(str, '/');
imgname_T="/raid/datasets/kaist-rgbt/images/"+line_vector[0]+"/"+line_vector[1]+"/lwir/"+line_vector[2].substr(0,6)+".jpg";
imgname_R="/raid/datasets/kaist-rgbt/images/"+line_vector[0]+"/"+line_vector[1]+"/visible/"+line_vector[2].substr(0,6)+".jpg";
//load
img_T=cv::imread(imgname_T,cv::IMREAD_UNCHANGED);
cv::cvtColor(img_T, img_T, COLOR_BGR2GRAY);
//img_T=cv::imread(imgname_T);
img_R=cv::imread(imgname_R);
original_img=img_R.clone();
if(img_T.empty())
{
std::cout << "Thermal Empty" << std::endl;
}
if(img_R.empty())
{
std::cout << "RGB Empty" << std::endl;
}
// Image Processing
////////////////////Thermal
cv::resize(img_T,img_T,cv::Size(640,512));
tensor_img_T = torch::from_blob(img_T.data,dimsT,at::kByte);
tensor_img_T = tensor_img_T.to(at::kFloat);
tensor_img_T = Normalize(tensor_img_T,0);
////////////////////////
///////////////////RGB
cv::resize(img_R,img_R,cv::Size(640,512));
cv::cvtColor(img_R,img_R,cv::COLOR_BGR2RGB);
tensor_img_R = torch::from_blob(img_R.data,dimsR,at::kByte);
tensor_img_R = tensor_img_R.permute({0,3,1,2});
tensor_img_R = tensor_img_R.to(at::kFloat);
tensor_img_R = Normalize(tensor_img_R,1);
//////////////////////
tensor_img_R=tensor_img_R.to(at::kCUDA).to(torch::kHalf);
tensor_img_T=tensor_img_T.to(at::kCUDA).to(torch::kHalf);
std::vector<torch::jit::IValue> trt_inputs;
trt_inputs.push_back(tensor_img_R);
trt_inputs.push_back(tensor_img_T);
double infer_t = (double)cv::getTickCount();
auto trt_results_ivalues = trt_ts_mod.forward(trt_inputs).toTuple();
infer_t = ((double)cv::getTickCount() - infer_t)/cv::getTickFrequency();
auto predicted_locs=trt_results_ivalues->elements()[0].toTensor();
auto predicted_scores=trt_results_ivalues->elements()[1].toTensor();
// NMS
double nms_t = (double)cv::getTickCount();
after_nms = detect_objects(predicted_locs,predicted_scores,priors_xy,0.1,0.425,200);
nms_t = ((double)cv::getTickCount() - nms_t)/cv::getTickFrequency();
after_nms=after_nms.to(at::kCUDA);
detect_score=after_nms.slice(1,4,5);
detect_loc=after_nms.slice(1,0,4);
detect_loc=detect_loc*original_dims;
for(int box_num=0;box_num<detect_loc.size(0);box_num++)
{
cv::Rect point;
float x1=detect_loc[box_num][0].item<float>();
float y1=detect_loc[box_num][1].item<float>();
float x2=detect_loc[box_num][2].item<float>();
float y2=detect_loc[box_num][3].item<float>();
float object_width = x2-x1;
float object_height = y2-y1;
float score = detect_score[box_num].item<float>();
if(score >= 0.1)
{
if(writefile.is_open()){
writefile<< i<<","<<x1<<","<<y1<<","<<object_width<<","<<object_height<<","<<score<<"\n";
}
}
point.x=x1;
point.y=y1;
point.height=object_height;
point.width=object_width;
cv::rectangle(original_img,point,(255,0,255));
}
std::stringstream savename;
savename << "/workspace/MLPD-torchscript/cpp_src/vis/" << std::setw(10) << std::setfill('0') << i << ".png";
std::string savepath = savename.str();
std::cout << savepath << std::endl;
cv::imwrite(savepath,original_img);
std::cout <<"ID : "<< i << " / 2252" << std::endl;
std::cout << "lnfer Time :" << infer_t << std::endl;
std::cout << "NMS Time : " << nms_t << std::endl;
i++;
}
writefile.close();
printf("Done");
return 0;
}다음과 같이 MLPD 코드를 작성할 수 있습니다. 해당 코드를 실행하여 평가하면 성능이 원복됨을 확인할 수 있습니다.
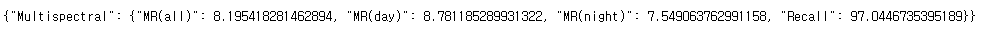
멀티스펙트럴 적용을 위한 팁 – 1채널 열화상 이미지를 파이썬 PIL처럼 동일한 값으로 불러오려면 ?
1)
img_T=cv::imread(imgname_T,cv::IMREAD_GRAYSCALE );
2)
img_T=cv::imread(imgname_T,cv::IMREAD_UNCHANGED);
cv::cvtColor(img_T, img_T, COLOR_BGR2GRAY);
첫번째 방식으로 하면 실질적으로 PIL과 값이 달라집니다. 따라서 2번 방식으로 진행하는게 좋습니다.
| Metirc | Normal | AMP | TensorRT_fp32 | TensorRT_fp16 | Torchscript_fp16 (w/ TRT) – python | Torchscript_fp16 (w/ TRT) – C++ |
| Miss-rate | 8.28 | -0.04 | 0.00 | -0.03 | -0.06 | -0.06 |
| Infer time(Avg.) | 9.8 ms | 25.8 ms | 1.0 ms | 1.5 ms | 2.7 ms | 1.4 ms |
| Infer time(Max) | 42 ms | 59 ms | 7.6 ms | 8.2 ms | 25.3 ms | 27.3 ms |
| NMS time(Avg.) | 38 ms | 5 ms | 35 ms | 12 ms | 11 ms | 10 ms |
| NMS time(Max.) | 73 ms | 34 ms | 62 ms | 50 ms | 41 ms | 19 ms |
| FPS (w/ NMS) | 20.28 fps | 29.63 fps | 24.22 fps | 66.23 fps | 62.5 fps | 28.8 fps |
2080Ti 에서 실험을 진행한 결과는 위의 표와 같습니다. C++로 진행할 경우 fps가 떨어지는데요.. 이는 아마도 이미지를 로드하는데 생기는 문제라고 생각됩니다. 파이썬의 경우 데이터로더에 workers를 이용하지만 opencv에서는 그냥 사용하다보니 속도차이가 있는게 아닐까 생각되는데, 그래도 원인을 찾아봐야할 것 같습니다.
질문1. “다음과 같이 MLPD 코드를 작성할 수 있습니다.” 라고 쓰신 곳 위에 코드는 python 코드를 저렇게 포팅시켜주는 툴이 존재하는건가요?
질문2. Tensor RT를 적용하면 학습속도에도 영향을 주나요? 영향을 준다면 GPU자원이 한정되었을때 좀 더 효율적으로 사용할 수 있다고 이해하면 될까요?
1. 모델은 torchscript로 포팅하며 나머지는 C++로 짜셔야 합니다. 툴은 없습니다.
2. 해당 부분은 첫번째 글을 보시면 도움이 될 것 같네요 학습보다은 추론속도 관점에서 최적화이며 말씀하신건 AMP를 사용하시면 됩니다.