이번주에 논문리뷰를 진행하려고 하였는데, 생각보다 마음에 드는 논문을 찾는것도 힘드네요.. 따라서 지난주에 진행했떤 TensorRT에 대해서 설명드리는 글을 작성하고자 합니다.
참고자료 : https://developer.nvidia.com/tensorrt
TensorRT란?
많은 분들이 TensorRT를 들어보셨을거라고 생각합니다. 그래서 TensorRT는 정확히 무엇일까요? TensorRT는 여러분들이 열심히 개발한 딥러닝 모델을 실제 사용할 때, 모델의 추론속도를 극대화 할 수 있는 모델 최적화 엔진으로 GPU를 제작하는 NVIDIA에서 제공하는 하나의 툴이라고 생각하시면 됩니다. 그러면 TensorRT는 여러분들의 모델을 어떻게 최적화 할까요?
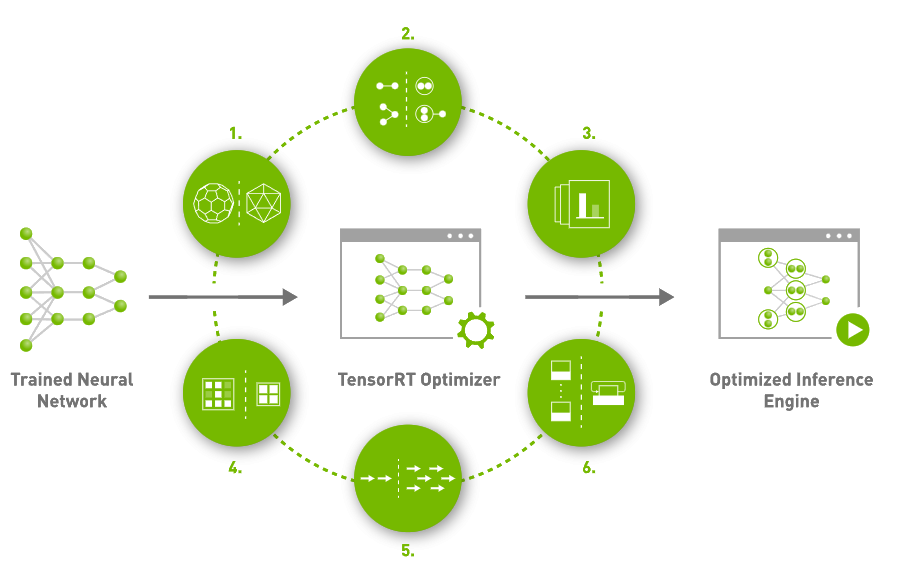
NVIDIA 공식 홈페이지에서 소개하고있는 TensorRT는 크게 6가지 특징을 이용하여 모델을 최적화한다고 설명하고 있습니다. 하나씩 살펴볼까요?
- Reduced Precision
해당방법은 많은 분들이 AMP를 통해서 경험했던 방법이라고 생각합니다. 말그대로 모델의 정확도는 유지하면서 모델의 정밀도를 기존 float32에서 float16 또는 int8로 줄이는 방식으로 모델을 최적화 합니다. 정밀도가 낮아질 수록 data의 크기 및 weight들의 bit수가 작아져서 더 빠르고 효율적인 연산이 가능하다고 합니다. - Graph Optimization
딥러닝 모델은 노드들이 연결된 형태로 Graph를 이루고 있는데, 이러한 Graph를 최적화하는 방식입니다. 중복되는 연산등을 동시에 처리하여 모델의 graph를 단순화하는데 이를 통해 model의 layer 갯수를 감소시킬 수 있다고 합니다. - Kernel Auto-Tuning
NVIDIA에서 제공하는 TensorRT인 만큼 GPU 및 CUDA 에 알맞은 형태로 최적화하는 방법입니다. - ~ 6. Dynamic Tensor Memory, Multi-Stream Execution, Time Fusion
위에 언급한 3가지 이외에도 다양한 방식으로 최적화를 진행하며, 각각에 대한 설명은 아래 사이트에서 잘 설명하고 있습니다.
https://developer.nvidia.com/tensorrt
https://blogs.nvidia.co.kr/2020/02/19/nvidia-tensor-rt/
자 그럼 이러한 TensorRT를 적용하면 어느정도 추론속도가 향상되는걸까요? NVIDIA 공식 블로그에서는 GPU와 각 Task에 TensorRT를 적용했을 때, 성능향상을 정리하고 있습니다. 하지만 이를 모두다 확인할 수는 없고, 우리 연구실에도 있는 V100에 대해서 성능을 살펴보면 아래와 같다고 합니다.
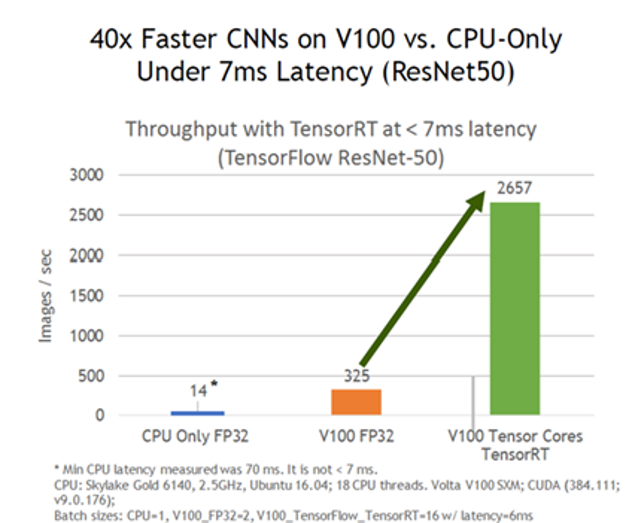
동일한 V100 으로 모델을 추론하였을때 기존 V100 FP32는 1초에 325장을 추론했다면, TensorRT 적용시 1초에 2657장을 추론하는 약 8배 이상의 속도 향상을 나타냈다고 NVIDIA는 이야기하고 있습니다. 따라서 이러한 TensorRT는 실제 딥러닝 기반 모델을 서비스화하는 곳이라면 반드시 사용해야하는 필수적 도구가 되어가고 있습니다.
이렇게 소개를 하다보니 NVIDIA에서 홍보자료를 만드는것 같은데, 다시 연구실 리뷰로 돌아와서 이러한 TensorRT는 저희 연구실에서 진행하는 여러 과제에서도 유용할 것 같아 이번 리뷰를 작성하게 되었습니다. (특히 비디오팀의 경우 더 도움이 되지 않을까 생각합니다.)
그렇다면 이러한 TensorRT는 어떻게 사용할 수 있을까요? 저희 연구실의 모든 인원이 Pytorch에 우호적이므로 Pytorch를 기준으로 설명드리겠습니다. Pytorch로 짜여진 모델을 직접 onnx를 거쳐서 TensorRT로 변경하는 방법도 있지만 친절한 NVIDIA에서는 Pytorch 모델을 한번에 TensorRT로 변환하는 코드를 공개하고 있습니다. 이번에 제가 TensorRT를 변환하는데 사용했던 repo는 아래 2곳 입니다.
- https://github.com/NVIDIA/Torch-TensorRT
- https://github.com/NVIDIA-AI-IOT/torch2trt
먼저 이름에서 알 수 있듯, 두 repo모두 NVIDIA에서 지원하고 있기 때문에 이슈에 대해서 무관심하진 않습니다. (그렇다고 빠르게 답하지도 않습니다.) 첫번째 repo의 경우 Torch 코드를 TensorRT로 변환하며 여기서 특징은 Torch에서 제공하는 Torchscript과도 호환된다는 점 입니다. Torchscript을 처음들어보셨을 수도 있는데, Torchscript은 python기반의 pytorch 모델을 C++에서도 사용할 수 있도록 변환하는 방법이며, 자세한 내용은 공식 doc를 확인하기 바랍니다. 그리고 두번째 repo는 NVIDIA에 ‘AI-IOT’가 붙어있습니다. 이를 통해서 유추할 수 있을지 모르겠지만, NVIDIA에서 판매하는 엣지디바이스, 즉 Jetson-Nano, Jetson-Xavier 등에서 사용할 수 있으며 (물론 첫번째 repo도 사용가능합니다.) 파이썬 기반으로 tensorRT를 사용할때 더욱 사용하는 사이트라고 생각하시면됩니다. 두 사이트 모두 NVIDIA에서 관리하기 때문에 친절하게 설명되어 있어 크게 어렵지 않지만 그래도 하나씩 살펴보겠습니다. 아 참고로 두 repo모두 도커이미지를 제공하고 있어 환경구축이 매우매우 쉽습니다. 회사에서도 도커를 많이 사용한다는데 연구원 분들도 연구실에서 도커와 좀더 친해지시길 바랍니다.
(해당 글에서는 이번에 연구실에서 제출한 MLPD에 TensorRT를 적용하였습니다.)
- Torch-TensorRT
앞서 설명드린것처럼 ‘Torch-TensorRT’ repo의 코드는 torch script를 이용하여 C++로도 확장이 가능하다는 장점이 있습니다.
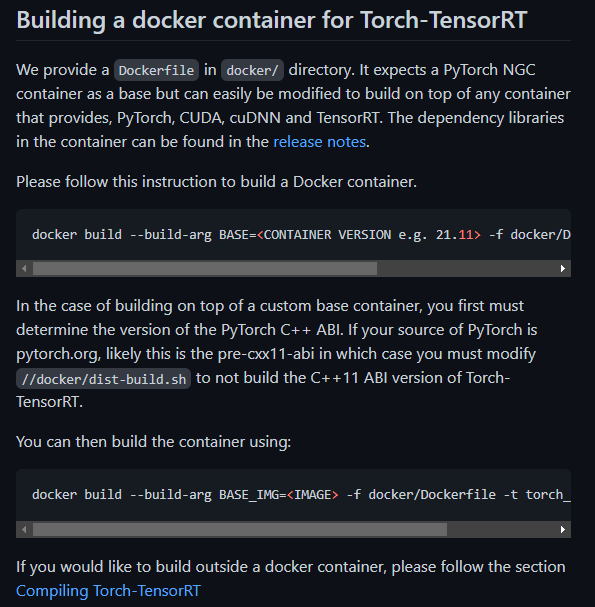
여러분들이 만든 이미지를 이용하여 빌드할 수 있고 아니면 NVIDIA에서 제공하는 도커에서 빌드할 수 있습니다. 특별한 환경설정이 필요한게 아니라면 NVIDIA에서 제공하는 도커 이미지를 이용하여 빌드하시면 환경오류 없이 바로 사용이 가능합니다. MLPD도 torch 버전에 따른 이슈도 없기 때문에 저는 NVIDIA에서 제공하는 이미지를 이용하여 빌드하고, 컨테이너를 만들었습니다. 사실 컨테이너를 다 만들었다면 더이상 할 게 없습니다. 설명대로 Pytorch 모델을 변환하면 되는데요..
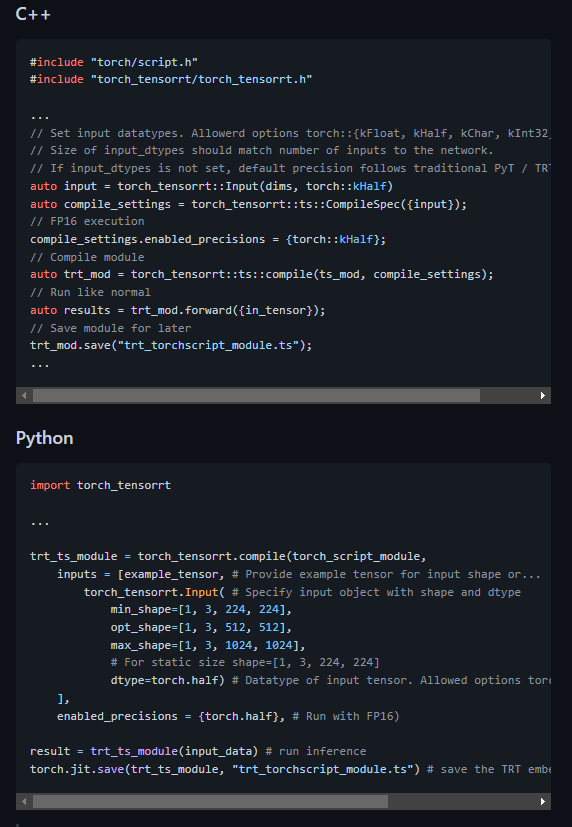
README에서는 변환 방법을 위와 같이 설명하고 있고, MLPD의 경우 멀티스펙트럴 입력을 받기 때문에 위의 예제를 이용하여 아래와 같이 변환하면 됩니다.
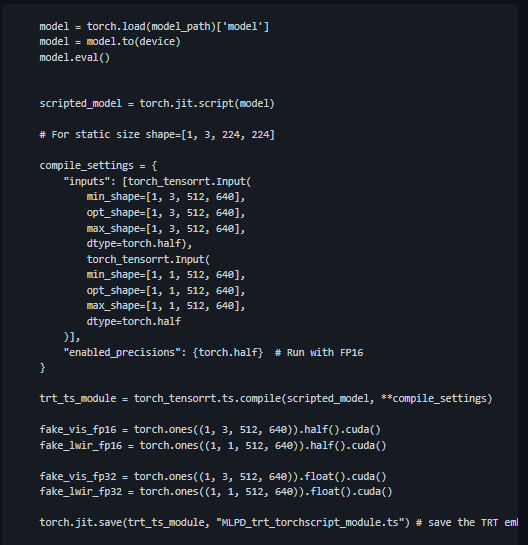
보시는 것처럼 간단히 변환이 가능하며 마지막에 torch.jit.save를 이용하여 모델을 저장하였습니다. 저장된 모델은 libtorch를 이용하여 C++에서도 사용이 가능합니다. 이렇게 되면 속도는 얼마나 빨라질까요? 단일 이미지 기준 모델 추론 속도는 약 10배정도 빨라지는 것을 확인하였고, 성능도 원복됨을 확인할 수 있었습니다.
2. torch2trt
1번과 매우 유사합니다. 해당 repo에서는 desktop에서 jetson에서 2가지 docker에 대해서 설명하고 있는데요. 자신이 사용할 환경에 맞춰 도커 이미지를 Pull해서 빌드하시면 됩니다.
Desktop : https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
Jetson : https://ngc.nvidia.com/catalog/containers/nvidia:l4t-pytorch
자신의 환경에 맞게 이미지를 Pull하셨다면 모두가 아는것처럼 컨테이너를 만들고 해당 repo를 클론하여 설치하면 됩니다. 설치방식은 크게 2가지로 나뉘며 without plugins, with plugins 입니다. 여기서 plugins는 좀 더 많은 operation을 지원한다는데, MLPD에서는 without plugins로도 충분합니다.
근데 여기서 정말 중요한건 아직까지 해당 repo를 사용할때 잡히지 않은 문제가 모델을 추론하고 나온 결과 값에 list 에러가 난다는 점인데요. [관련 이슈] (제가 지난번에 연구원님들께 디버깅을 요청했던 코드 기억하시나요..?) 이슈에서도 해당 내용이 다뤄지고 있으나 아직까지 해결은 되지 않고 있는 것 같습니다. 대신 임시방편으로 해결방법을 찾을 수 있었는데정리하자면 torch2trt/converters/__init__.py에 존재하는 getitem을 주석처리하고 설치하시면 됩니다. [관련이슈] 설치를 마치면 이제 사용할 수 있으며, 사용은 README에서 설명한 것처럼 진행하시면 됩니다.
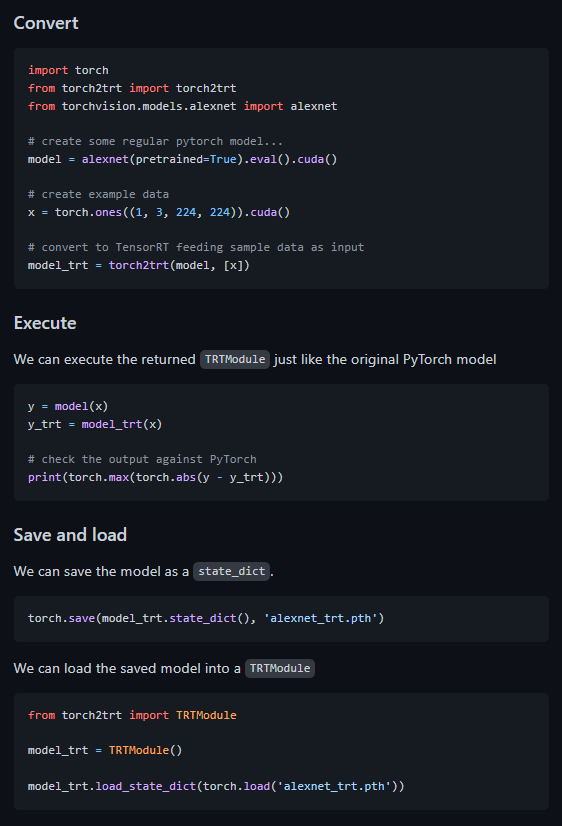
물론 해당 컨버팅도 저는 MLPD 즉 멀티스펙트럴 입력을 사용하기 때문에 아래와 같이 코드를 변경하여 사용하였습니다.

위와 같이 코드는 단순하지만 속도개선은 확실히 이뤄지는 것을 확인할 수 있습니다.
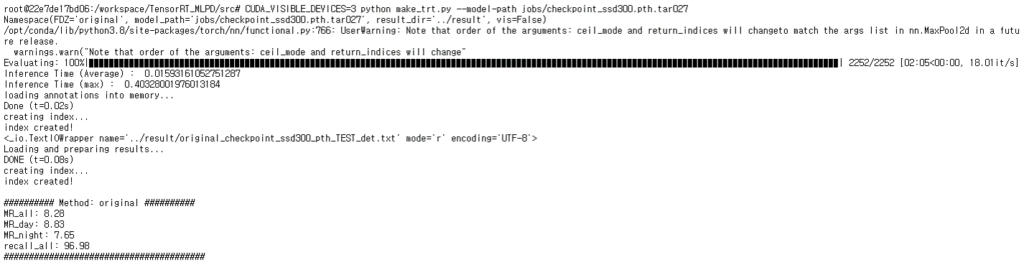
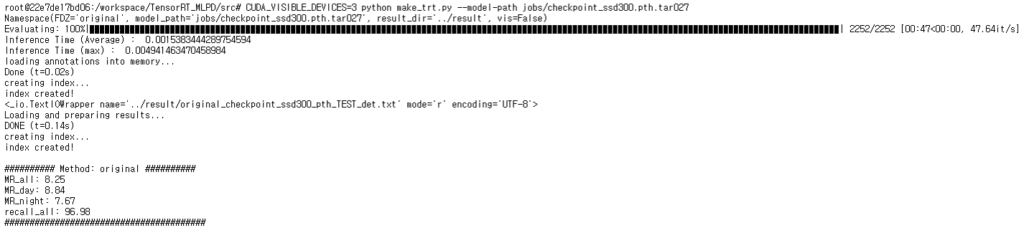
위의 그림처럼 KAIST 벤치마크 데이터셋 2252장을 처리하는데 속도가 2분 5초였던게 47초로 단축됨과 동시에 모델의 입출력에서 측정한 추론속도는 0.015에서 0.0015로 10배정도 빨라지는 것을 확인할 수 있습니다.
본 리뷰의 결론은 다른 분들이 논문리뷰를 하는 것이 새로운 논문에 대한 정보 및 아이디어를 다른 연구원들에게 전달하듯, 본 리뷰에서는 TensorRT를 사용하는 방법에 대해서 연구원들에게 알리고 비디오 과제와 같이 서비스가 필요한 과제에서도 TensorRT를 적용하는 것이 좋다는 것을 알려주기위해 작성하였습니다.
과거 포테닛 과재 진행시 tensorRT 도입을 못했던 이유가 뭘까요?
엔비디아 지원이 더욱 좋아진건가요?
제가 지난번 포테닛과제에서 TensorRT를 담당하지 않아 정확한 기술적인 이슈까지는 파악할 수 없지만 제 기억으로는 Adative Fusion을 진행할 때 사용하던 Correlation Module이 tensorRT에서 지원하지 않아서 그런것 같습니다.
모델의 정밀도를 줄이게 되면 성능에 영향을 끼치지는 않나요?
그리고 Object Detection이 아닌 다른 task에서 TensorRT를 활용해 성능 및 추론 속도면에서 이득을 본게 있다면 알려주시면 감사드리겠습니다.
실질적으로 모든 wieght의 값이 32비트를 할당하고 있지 않습니다. 따라서 16비트로 정밀도를 줄인다고 성능영향은 크지 않으며 미비합니다.
다른 task에서도 활용되고 있으며 해당 부분은 본문에서 안내하고 있는 사이트에서 확인하실 수 있습니다.
https://developer.nvidia.com/deep-learning-performance-training-inference#dl-inference