

이번 리뷰할 논문은 다크데이터 과제에서 베이스가 되었던 논문입니다. 제목은 “Learning Loss for Active Learning”으로, 제목에서 알 수 있듯이 Active Learning를 다룬 논문입니다. 많은 연구실 분들이 Supervised Learning, Unsupervised Learning, Semi-supervised Learning, 그리고 Self-supervised Learning에 대해서는 잘 아시겠지만 Active Learning에 대해서는 생소하실 것 같아 해당 논문을 리뷰하게 되었습니다.
Active Learning이란 Unsupervised, Semi-Supervised 등등과 같이, 데이터의 높은 annotation cost를 줄이고자 나타난 task 입니다. 앞서 언급한 task들을 모두 포함하는 인공지능 분야에서는 주로 학습 데이터를 통해 딥러닝 모델을 학습시키고, 이러한 모델로 문제를 해결하고자 합니다. 풀고자 하는 task들이 복잡해져감에 따라 딥러닝 모델도 깊고 복잡하게 설계되어갔으며, 이같은 흐름에서 학습 데이터의 양을 늘려주는 것이 딥러닝 모델의 좋은 성능을 내고자 하는 방법 중 하나로 알려져왔습니다. 그러나 이 방식을 위해서는 수많은 데이터와 그만큼의 label이 필요하였고 이는 많은 cost를 요구했기에, label 없이 효율적으로 학습하고자 하는 기류와 함께 Active Learning이 등장하였습니다.
Active Learning의 주요한 컨셉은 수많은 Unlabeled 데이터 중 어떤 데이터를 먼저 학습에 사용할 지 정하는 것입니다. 어떤 데이터를 먼저 학습에 사용하면 모델의 성능을 높일 수 있는지 알 수만 있다면, 그에 해당하는 데이터에 우선 순위를 높여 annotation을 진행할 수 있습니다. 또한, 모든 Unlabeled 데이터를 annotation 하지 않아도 원하는 성능까지 모델을 학습시키는 것에 성공하여 효율성을 가져갈 수도 있습니다.
이러한 Active Learning을 다루기 위해 오늘 리뷰하고자 하는 논문의 방법론이 제안되었으며, 꽤나 심플하지만 근거있게 설계된 방법론으로 다음 단락에서부터 리뷰를 하도록 하겠습니다. 그리고 서론이 평소 제가 쓰던 글보다 길게 작성된 감이 없지 않아 있는데, 오늘 리뷰하고자하는 방법론이 간단하여 뒤쪽 내용은 많지 않으니 참고해서 읽어주시면 감사드리겠습니다.
1. Method
본 논문은 Active Learning과 관련하여 크게 두 가지 contribution을 보입니다. 먼저, 1) 제안된 Loss prediction module과 함께 Active Learning의 학습 방식이 어떤 task에도 적용가능하도록 설계하였으며, 2) Classification, Object Detection, Human Pose Estimation과 같은 분야의 방법론에 제안된 방식을 적용한 실험을 보였습니다. 이번 단락에서는 첫번째 contribution에서 언급한 내용에 대해 설명하고자 합니다.
1.1 Overview
우선 Active Learning 실험의 세팅 먼저 설명드리고자 합니다. Active Learning의 본래 목적인 어떤 데이터를 학습 데이터로 사용할지를 충족시키기 위해 N개의 Unlabeled pool에서부터 시작합니다. 그리고 학습할 모델로는 Fig 2의 (a)와 같이 원하는 task의 모델 \theta_{target}과 Loss prediction module \theta_{loss}가 있습니다.
이때, annotation cost를 줄이기 위해 Unlabeled pool에서 K개의 데이터를 랜덤으로 선택하여 Labeled dataset L_{K}^{0}을 생성합니다. 현실 시나리오에서 이는 랜덤으로 선택된 K개의 데이터에 annotation하는 과정을 의미합니다. 이렇게 Labeled dataset L_{K}^{0}으로 두 모델을 학습하여 \theta_{target}^{0}과 \theta_{loss}^{0}를 얻어내며, 그 중 학습된 \theta_{loss}^{0}으로 나머지 (N-K) 개의 Unlabeled pool을 평가합니다. 평가 후 얻어낸 값은 각 Unlabeled pool 내의 데이터에 대해 만약 label이 있었다면 산출되었을 loss를 의미하며, 이 값이 높으면 모델이 어려워하는 데이터임을 의미하기 때문에 이 값을 uncertainty라고 부릅니다. (N-K) 개의 Unlabeled pool에 대한 uncertainty를 모두 측정한 후, 이 수치가 높을수록 모델에게 부족한 영역으로 학습이 필요한 데이터로 판단되어지기 때문에 내림차순으로 (N-K) 중 K개를 선택하여 Labeled dataset에 추가해 L_{2K}^{1}를 생성합니다. 이후 Fig 2의 (b)처럼 두 모델을 Labeled dataset으로 학습하고, 남은 Unlabeled pool에 대해 uncertainty를 측정해 Labeled dataset을 보강하는 과정을 반복하여 Active Learning 과정이 진행됩니다.
1.2 Loss Prediction Module
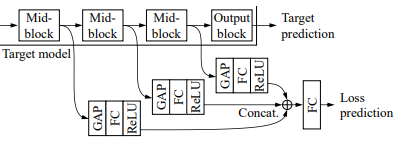
이번 단락에서는 Unlabeled pool에서 uncertainty를 계산하기 위한 Loss prediction module에 대해 설명드리고자 합니다.
Loss prediction module은 특정 task에 대한 uncertainty를 정의하여 engineering cost를 줄이는 것에 목적을 둡니다. 이때문에 target task와 함께 학습되도록 설계 되었습니다. 뿐만 아니라, 이미 여러 target task들은 매우 큰 모델을 방법론으로 두고 있기에 computational cost를 줄이고자 target 모델보다 작은 크기로 설계되었습니다. 이를 고려하여 설계된 Loss prediction module은 Fig 3과 같으며, target 모델의 intermediate feature들을 Global Average Pooling을 통해 차원을 맞추고, 다른 hyperplane으로 projection시켜 생성된 vector들로부터 loss를 예측합니다.
1.3 Learning Loss
이번 단락에서는 앞서 언급한 Loss prediction module의 학습 방식에 대해 설명드리고자 합니다.
학습을 위한 Loss는 target loss L_{target}과 loss prediction module loss L_{loss}로 구성됩니다. 이때, loss prediction module loss는 간단하게 예측된 loss l'과 target 모델의 loss l 간의 MSE로 설계될 수 있습니다. 그러나, 이 방식은 예측된 loss가 target 모델 loss scale에만 초점을 맞추어 학습이 되기에 정확한 loss 값을 예측하기 어렵게 만들며, 저자가 실험해보았을 때도 좋은 성능을 나타내지 못했다고 합니다. 이러한 문제점을 해결하기 위해 저자는 mini-batch에서 loss prediction module loss를 설계하여, 예측된 loss가 target 모델 loss의 scale을 무시하도록 만들었습니다.
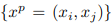
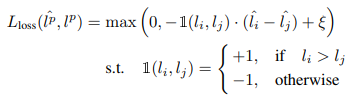
Loss prediction module loss는 먼저 mini-batch B개 내에서 B/2개의 쌍을 생성합니다. 생성된 쌍은 식 (1)과 같이 위첨자 p로 표시됩니다. 그리고 예측된 loss l' 와 target 모델 loss l에 대해 만들어진 쌍을 입력으로 두고 식(2)와 같은 loss 구조로 설계됩니다. 이러한 구조를 통해 쌍으로 묶인 두 target 모델 loss 간의 scale 차이가 일정 margin 이하일 때만 Loss prediction module을 학습하게 되었습니다.
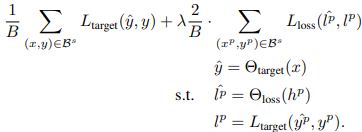
이와 같이 mini-batch 단위로 설계된 Loss prediction module을 포함한 전체 loss는 식 (3)과 같이 설계 됩니다. 여기서 y는 target task의 label, \hat{y}는 target 모델의 예측 값, h는 target 모델의 intermediate feature를 의미합니다.
2. Experiments
2.1 Image Classification
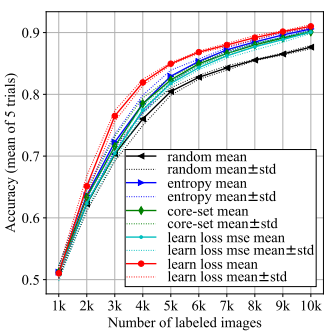
Fig 4는 target task를 Image Classification으로 두고 제안된 Active Learning 방식을 적용하여 학습데이터를 선정했을 때(red)와 랜덤으로 선정했을 때(black)의 성능 비교 그래프 입니다. 또한 다른 Active Learning 방식 중 entropy 기반 방법론 (blue)와 core-set 기반 방법론(green)과의 비교도 포함되어 있습니다. 실험은 CIFAR-10에서 진행되었으며, 최초에는 training dataset 50000장을 모두 unlabeled pool로 두고 K는 1000으로 두어 총 10번의 데이터 선택 과정을 거쳤습니다. Target 모델은 ResNet-18로 고정되었으며, 초기 랜덤성을 감안하여 5회 평균으로 최종 성능을 판단하였을 때 제안된 방식이 다른 방법론에 비해 확실히 모든 iteration에서 좋은 성능을 보여주었습니다.
이외에도 Object Detection과 Pose Estimation에 대한 성능 그래프가 논문에 존재하오니, 해당 task에 관심이 가시는 분들은 논문에서 확인부탁드립니다.
3. Reference
[1] https://arxiv.org/pdf/1905.03677.pdf
리뷰 잘 읽었습니다.
결국 이 방법론을 요약하자면 N개의 데이터 중 K개 만큼을 annotation을 하여 모델을 학습시킨 뒤, N-K에 대해 평가하여 이 때 loss가 높은 데이터 셋들을 정렬하여 다시 일부를 새로 어노테이션 한 다음 추가한다고 이해하면 되는건가요?
그리고 uncertainty를 학습하기 위한 loss로 일정 margin 이하인 값들만 사용하는 이유는 무엇인가요? 이 방식을 이용하면 왜 target loss의 스케일을 쫓아가지 않고 유의미하게 학습을 할 수 있을까요?
맞습니다. loss를 예측한 뒤, loss가 높은 데이터 들을 uncertainty가 높다고 가정하고 해당 데이터의 어노테이션을 추가합니다.
두 loss pair 간의 scale 차이가 일정 margin이하 일 때만 사용하는 이유는 두 loss의 차이가 일정 margin 이상이라면 결과적으로 학습시키고자하는 최종 loss 내에 scale 차이로부터 기인되는 비중이 커지게 되고, 이에 따라 Loss prediction module이 scale 요소에 fitting 되기 때문입니다. 고로, 일정 margin이하일 때로만 제한을 둔다면, scale 요소에 대한 비중은 줄어들고 그외의 요소들(미니배치당 분산 등등)의 비중이 높아져 scale 요소에 fitting 되는 현상을 막을 수 있습니다.