오랜만에 Style Transfer 관련 논문을 가져왔습니다. ICCV2021에 게제된 논문으로 논문 제목을 딱 보면 style transfer에서 가장 잘 알려진 방법론인 Adaptive Instance Normalization에 Attention Mechanism을 적절힌 섞은 논문으로 파악됩니다.
Introduction
기존의 Style Transfer 방법론들 중 초기에는 style feature와 content feature로 나누어 추출한 뒤 이를 잘 융합하여 변환을 수행하였습니다. 하지만 해당 방법들은 어떠한 feature distribution에 대하여 고려하지 않았기 때문에 결과가 그리 좋지는 않았습니다.
그러다가 AdaIn이라는 논문이 제안되었는데, 해당 방법론은 그 당시에 매우 창의적인 논문 중 하나였습니다. Feature map의 style은 평균과 표준편차로 나타낼 수 있기에 컨텐츠 feature map의 평균과 표준편차를 제거해준 후 style의 평균과 표준편차로 뒤덮어주면 스타일이 변환된다는 것이죠.
이러한 AdaIn이 좋은 성능을 보여줌에 따라 지금까지의 방법론들은 global statistic에 대한 정보들을 스타일로 보고 이를 normalized content feature에 잘 적용해주었습니다. 이 방법들은 매우 효과적이었지만, global statistic에만 적용한 나머지 local feature statistic을 고려하지 못하였기 때문에 위에 방법론들은 local distortion들이 발생하기 쉬웠습니다.
위 문제를 해결하고자 저자는 Adaptive Attention Normalization(AdaAttN)이라는 새로운 attention & normalization module을 제안함으로써 더 능동적으로 per-point basis에 대한 normalization을 수행하였다고 합니다.
특히 spatial attention score는 컨텐츠와 스타일 feature map의 shallow와 deep feature 모두에서 학습이 되며 이를 통해 per-point weighted statistic들이 스타일 feature point를 모든 스타일 feature points의 attention-weighted output의 분산으로 간주함으로써 계산된다고 하네요.(이게 무슨 말이지.. 영어 문장 자체가 너무 길고 복잡해서 해석이 안되네요.)
마지막으로 content feature는 계산된 per-point weighted style feature statistic들과 동일한 local feature statistic으로 증명하기 위해서 normalized가 되었다고 합니다.
흠… 지금까지 내용만 봐서는 이해하기 조금 어려운 듯 합니다만 요약하자면 기존의 방법론들은 global statistic에만 초점을 두고 설계된 반면 우리의 방법론은 제안하는 모듈을 통해 local statistic도 보다 효과적으로 학습하여 local detail을 잘 살려보겠다.. 라는 느낌으로 보면 될 것 같습니다.
Method
Overall Framework – 먼저 제안하는 방법론의 전체 구조에 대해서 알아봅시다.
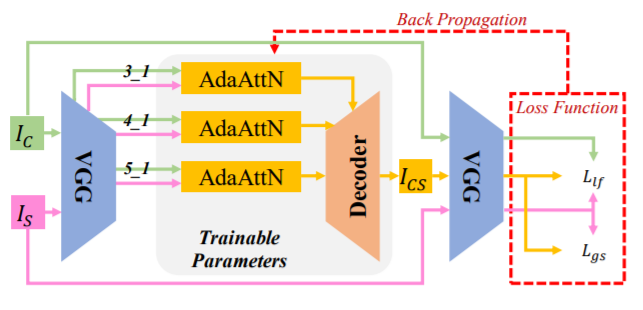
Style Transfer의 아주 전형적인 모형입니다. Content Image와 Style Image를 각각 ImageNet으로 pretrained된 모델에 태워서 추출한 후 두 feature 정보를 적절히 융합시켜서 디코더를 통과하면 Style이 변환된 가짜 영상이 생성되는 것이죠.
그리고 이렇게 생성된 가짜 영상을 다시 ImageNet으로 pretrained된 모델에 태워서 Content와 style feature를 얻은 뒤, 원래의 Content image와 style image의 정보들과 비교하는 방식으로 학습이 진행됩니다.
논문에서는 VGG19을 사용했다고 하며 multi level feature를 각각 ReLU-3_1, ReLU-4_1, ReLU-5_1 레이어에서 가져왔다고 합니다.
Adaptive Attention Normalization
본격적인 설명에 들어가기 앞서, 저자는 기존의 arbitrary style transfer 모델에 대하여 설명합니다.
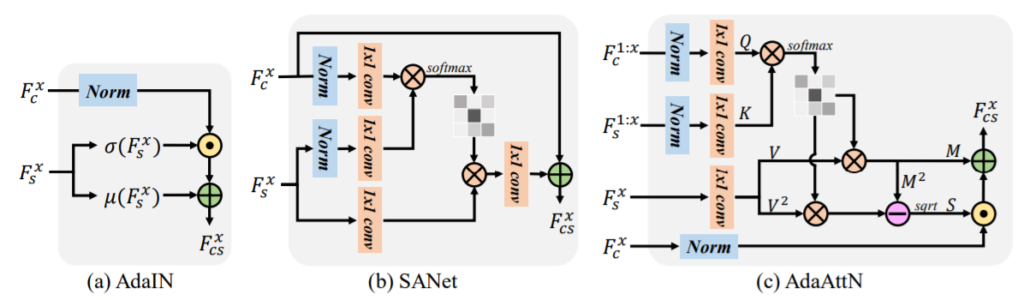
먼저 그림2-(a)는 위에서도 제가 언급한 Style Transfer에서 처음 통계학적인 관점으로 스타일을 적용했던 AdaIN의 구조입니다. 보시다시피 Content Feature map을 normalization을 통해 style을 제거시킨 후, Style Feature map의 평균과 표준편차를 활용해 새로운 Style을 입힌 임베딩 feature F_{cs}를 생성한 모습입니다. 이 방식은 전체적인 스타일 분포를 잘 반영하지만, 로컬에 대한 스타일은 제대로 반영하지 못하는 아쉬움이 존재합니다.
이러한 문제를 해결하기 위해 SANet이라는 방법론이 제안됐었나 봅니다. SANet은 style과 content map으로부터 attention map을 계산한 다음, 어텐션 맵이 결합된 style feature를 content feature에 반영함으로써 local stylization을 수행하였습니다. 하지만 저자는 SANet가 local feautre distribution의 alignment와 loww-level matching이 부족하다는 단점이 있다고 지적합니다.
위의 두 방법론들을 더 보완하고자 저자는 Adaptive Attention Normalization 모듈이라는 것을 제안하였습니다. 그림2-(c)를 보면 조금 복잡해보이기는 한데, 크게 3가지로 동작한다고 보시면 될 것 같습니다.
먼저 1) Shallow~deep layer에 대한 컨텐츠와 스타일 feature들의 attention map을 계산한 후 2) style feautre의 weighted 평균과 표준편차 map을 계산한 다음 3) per-point feature distribution alignment를 수행하고자 adaptive하게 content feature 정규화하는 과정을 거칩니다.
보다 자세한 내용 및 수식은 추후에 보충하도록 하겠습니다.
Experiments
Style Transfer는 아무래도 정량적 결과 측정이 어렵다보니 정성적 결과부터 보겠습니다.

제안하는 방법론이 타 방법론과 비교하였을 때 컨텐츠가 지역적으로 잘 살면서 동시에 스타일도 잘 표현한 모습이라고 주장하고 있습니다. 4번째 열에 AdaIN을 보시면 확실히 Global distribution에 대해서만 동작하기에 content가 손실된 부분들이 제법 보이며 스타일 역시 전반적인 느낌만을 표현하고 있습니다만 AdaAttN의 경우는 세부적으로 스타일이 적용되려고 하는 경향성이 보입니다.
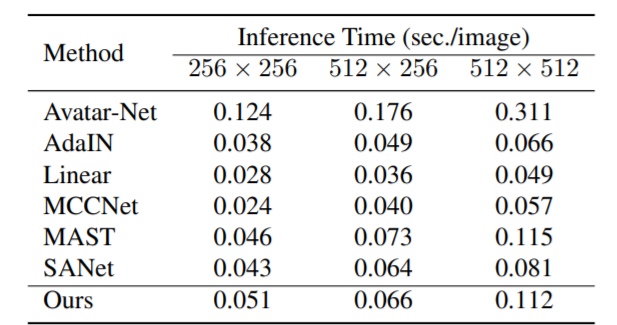
위에 테이블은 모델의 inference 속도인데, 그림2에서 보았던 것처럼 모듈이 막 복잡하게 보였지만 속도 측면에서는 큰 증가가 없다고 합니다.
per-point feature distribution alignment 를 수행하는 부분이 그림2의 (c)에서 어디에 해당하는건가요..? 그리고 논문에서 이야기하는 per-point feature에서의 per-point는 우리가 아는 픽셀레벨인가요..? 아니면 그보다 좀 더 큰 의미의 local level feature인가요..?