이번 리뷰는 3D Pedestrian Localization ~ MonoLoco의 확장 연구에 해당합니다. 군중이나 물체에 의해 가려진 보행자의 신체 정보를 예측하는 네트워크를 추가하여 성능을 향상 시켰습니다. 해당 방법론에서 제안한 아이디어를 저도 동일하게 생각하고 추후 Potenit에 추가할 생각이였는데… 역시 세상은 넓네요…
Intro
보행자 감지 및 위치 추정은 보행자의 안전에 직결되기 때문에 매우 중요한 태스크에 해당합니다. 또한 높은 정확도와 빠른 추론 속도가 보장 되어야 합니다. 이러한 문제로 2D pedestrian detection 과 같은 연구들이 활발히 이뤄졌으나, 실질적인 관점에서 3차원 공간에서의 위치 추정이 더 활용도가 높지만 많은 연구가 이뤄지지 못했습니다. 이는 군중 속의 보행자의 형태나 자세가 다채로워 3차원 보행자 위치 추정을 하기에는 연구 진척도 측면에서나 성능 면에서 아직까지 부족하기 때문입니다.
이러한 한계에도 Monoloco와 같이 포즈 측면에서의 보행자 위치 추정으로 의미 있는 정확도와 빠른 추론 속도를 가진 방법론이 등장했습니다. 하지만 해당 방법론은 영상 속 보이는 보행자의 신체 정보(포즈 키포인트)를 이용하여 위치를 추정하기 때문에 아래의 그림과 같이 신체 일부가 가려진 경우, 저조한 성능을 보이는 문제가 있습니다.

저자는 3차원 보행자 위치 추정 알고리즘의 성능을 개선하기 위해 기존 Monoloco 방법론의 문제점에 집중합니다. 위에서 언급한 보행자 가려짐 문제를 해결하기 위해 새로운 네트워크를 통해 가려진 보행자의 신체 정보(포즈 키포인트)를 추정하기 위해 발의 위치를 추정하고 이를 통해 60% 개선된 3차원 보행자 위치 추정 알고리즘을 제안합니다.
Method
방법론은 매우 간단합니다. Monoloco의 방법론을 계승하되, 가려짐으로 손실된 신체 정보를 추정하는 네트워크 Missing body parts estimation을 제안합니다. 제안한 전체 구조는 아래와 같습니다.
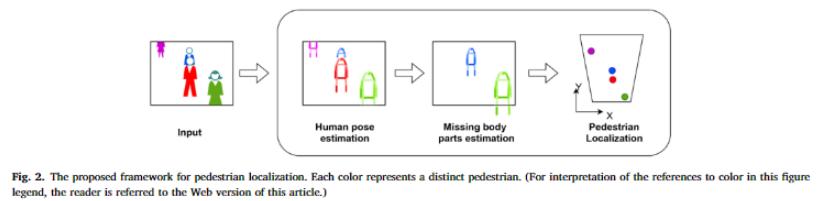
Human pose estimation. 저자는 Monoloco를 그대로 계승했습니다. 먼저 영상 속 보행자의 신체 정보를 추정하기 위해서 SOTA pose detector인 OpenPifPaf를 이용합니다. 최대 17개의 포즈 키포인트를 추정하며, 가려진 경우에는 이보다 적은 키포인트를 예측합니다. 또한 저자가 주장하길 보행자의 위치를 정확하게 추정하기 위해서는 발 위치를 위치 추정에 반드시 반영 해야 한다고 합니다. 가려짐이 발생한 경우, 카메라 각도 혹은 지면의 경사도에 따라 거리에 비해 키가 커 보이는 문제가 발생합니다. 그렇기에 발의 위치를 추정해야 한다고 주장합니다.
++ 포즈 기반의 위치 추정은 포즈의 스케일 뿐만이 아니라 위치도 큰 영향을 가집니다. 즉, 학습 데이터의 거리에 따른 분포도 ~ 지면을 기준으로 거리에 따른 스케일 변화를 학습합니다. 이러한 이유로 가려짐이 발생한 경우에는 노이즈로 작동할 가능성이 높습니다.
Estimating missing body parts. 해당 파트가 제안한 방법론에 속합니다. 아래의 그림과 같이 굉장히 간단하고 라이트한 네트워크로 구성됩니다. 먼저 Human pose estimation으로부터 추정된 보행자의 신체 정보를 보행자의 경계 상자의 왼쪽 상단 모서리를 이미지 좌표의 원점으로 이동하여 정규화를 진행합니다. 이후 가려짐으로 소실된 신체 정보를 예측하기 위해서 간단한 증강 기법을 이용합니다. 먼저 COCO 데이터 셋 속 가려짐이 발생한 키포인트(무릎 이하 정보가 소실된)를 가상으로 만들어 소실된 신체 정보를 복원할 수 있도록 학습을 진행합니다.
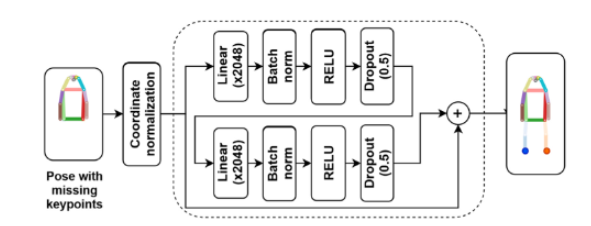
모델은 아래의 수식 1로 설계된 손실 함수로 학습이 진행됩니다. J^nf는 신체 정보(무릎 밑)가 일부 소실된 가상의 키포인트이며, J^f는 신체 정보(무릎 밑)가 존재하는 키포인트에 해당합니다.

Location estimation on the ground plane. 이후 homography transformation을 이용하여 추정된 보행자의 발 정보를 토대로 위치를 추정합니다.
++ monoloco에서는 키포인트를 위치를 추정하는 모델에 태워 보행자 3차원 위치를 추정합니다. 근데 저자는 발의 신체만 추정하고 호모그래피 변환만 이용하여 3차원 위치를 추정합니다. 성능으로는 개선된 모습을 보여주기는 하지만, 직접적으로 위치 추정 모델을 사용했을 때, 성능이 오를 것 같은데 하지 않는 이유를 밝히지 않아 의문점이 듭니다.
Experiment
실험에서는 기존에서도 사용되어진 KITTI, COCO 데이터 셋과 Southern Cross Station(SCS)를 이용하여 평가합니다. SCS는 지하철 역에서 촬영된 데이터 셋이며, 저자가 직접 위치 정보에 대한 주석 처리를 하여 실험에 사용했다고 합니다. 총 5,218 장이지만, 사람이 많이 존재하는 610장의 데이터를 선별하여 사용했습니다.
+ SCS는 공개된 데이터 셋이 아니며, 보안 상 공개가 어렵다고 합니다. 또한 깊이 정보를 어떻게 생성했는지 공개를 하지 않아… 좀 모호한 부분이 있습니다.
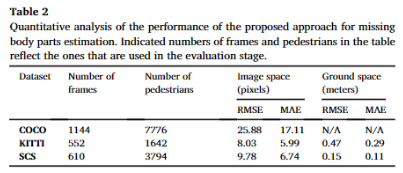
먼저 위에서 언급한 세 가지 데이터 셋에서의 정량적 평가입니다. 실험적 결과 KITTI에서는 47/27cm, SCS 15/11cm의 오차를 보여 소실된 파트를 예측하는 모델의 효율성을 보이고자 합니다. (COCO에서는 보행자의 3차원 위치 정보가 주어지지 않아 N/A로 표시됩니다.)
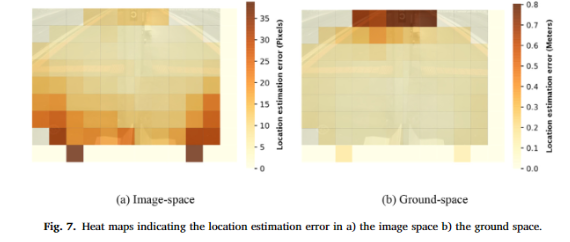
또한 Image-space와 Ground-space(real-world~3차원)에서의 Error map을 시각화한 Fig 7을 볼 수 있습니다. Image-Space에서는 가까운 거리일 경우 높은 에러가 발생합니다. 이는 영상 내에서 가까운 위치 일 수록 세밀한 픽셀을 가지며 truncation이 발생하여 보행자의 신체 정보가 소실이 크게 발생하기 때문입니다. 하지만 Ground-space에서는 오히려 가까운 곳에서는 적은 에러를 보이고 먼 곳에 위치한 상황에서 에러률이 높게 발생합니다. 이는 해당 네트워크가 손실된 신체 정보를 복원하였기에 가까운 위치에서 에러가 줄고, 영상을 통한 깊이 추정의 한계(픽셀 단위를 가진 영상의 한계)로 에러가 발생하는 먼 곳에서만 에러가 높게 발생하는 것을 볼 수 있습니다.
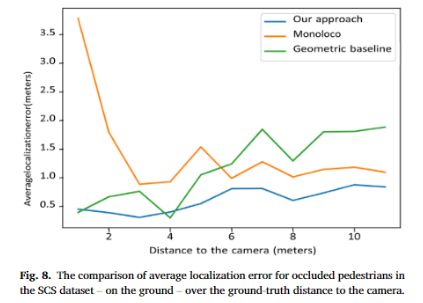
저자는 Fig 8를 통해 베이스라인인 Monoloco와 Geometric baseline과 성능 비교를 수행합니다. Geometric baseline은 open pifpaf로부터 추정된 bbox의 하단 중심으로 추정한 위치에 해당합니다. 성능을 비교 했을 때, 제안한 모델이 가까운 곳에서는 monoloco보다 매우 높은 성능을 보이고, 가까운 거리 이외에도 우수한 성능을 보여주고 있습니다.
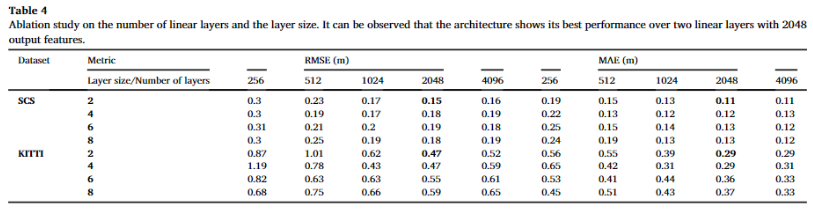
추가로 제안한 모델의 layer 수와 크기에 따른 성능 비교를 수행하였으며, 저자는 2계층과 2048 dim에서 가장 좋은 성능을 보였다고 합니다.
=====================================================
해당 논문을 읽으면서 많은 의문점이 들었습니다. 가장 큰 의구심이 든 부분은 성능을 비교하는 부분입니다. 저자는 자신의 모델이 키포인트와 깊이 추정에 대한 학습을 수행하지 않았기에 monoloco 또한 학습하지 않고 평가에서 사용하지 않은 nuscene에서 학습한 모델을 사용하였다고 합니다. 또한 데이터 셋 중 가려짐이 존재하는 부분만 선별하여 평가에 사용했습니다. 제안한 방법론의 강점을 잘 보이는 것도 중요하지만, 공평한 비교가 제대로 수행되지 않은 것 같아 아쉬움이 남았습니다.
또한 가려짐에 대한 보강을 석사 진학 후, 공부한 anomaly detection ~ 불확실성을 이용하여 예측하는 것도 괜찮을 것 같다는 생각이 들기도 합니다.
간단한 방법들이지만 키포인트로 거리를 추론한다는 것에서 계속 관련된 논문들이 나오고 있는것 같습니다. 본 논문에서는 occlusion이 발생하는 키포인트에 대해 보완하는 방법을 제안하고 있지만 결정적으로 키포인트가 추출된 대상에 대해서만 객체인식이 진행된다는 한계가 존재할 것 같습니다. 평가지표는 검출된 객체들에 대해서만 평가를 진행하는지, 아니면 키포인트가 검출되지 않은 보행자에 대한 평가지표도 함께 논문에서 나타내는지 궁금하여 질문드립니다.
객체 인식에 실패한 케이스에 대한 성능 지표에 질문해주셨습니다.
질문의 초점이 객체 검출이냐, 위치 인식이냐에 따라 답변이 달라져 두 관점에서 답변을 달아두록하겠습니다.
– 객체 검출 성능이 궁금하신거라면 해당 방법론류들은 키포인트 검출 능력에 집중하지 않으며, 어떤 키포인트 모델을 사용하냐에 따라 달라집니다. 즉, 객체 검출 성능 = 베이스로 사용하는 키포인트 모델 성능입니다.
– 위치 인식 성능이 궁금하신거라면, 검출되지 않은 보행자는 False 케이스가 되며, 리뷰의 방법론이 사용하는 메트릭(RMSE, MAE) 특성상 반영되지 않습니다. 그리고 아쉽게도 이외의 추가 실험은 진행되지 않았습니다. 저도 해당 부분이 아쉬운 부분이라고 생각합니다. 해당 방법론의 베이스(Monoloco)에서 사용되는 메트릭(ALE)인 경우는 못찾는 경우를 고려하는데, 이에 대한 실험은 왜 진행하지 않았는지 의구심이 듭니다.
안녕하세요 태주님! 좋은 리뷰 감사합니다.
현재 연구에서 제안하신 방법론을 읽고 많은 아이디어와 영감을 얻을 수 있었습니다.
특히 가려진 보행자의 키포인트를 복원하는 Missing Body Parts Estimation 네트워크가 매우 흥미로웠고, 실제로 제가 고민하던 부분과도 연결되어 있었습니다.
한 가지 추가적으로 여쭤보고 싶은 점이 있는데요. 현재 연구에서는 보행자의 포즈 추정을 위해 OpenPifPaf를 사용하고 계신데 최근 YOLOf와 같은 YOLO 기반 포즈 추정 모델들이 빠른 속도와 우수한 성능을 보이고 있습니다. 만약 OpenPifPaf 대신 YOLOf를 사용하여 보행자 인식 및 포즈 추정을 진행한다면, 제안하신 Missing Body Parts Estimation 네트워크와 결합했을 때 성능 측면에서 어떤 장단점이 있을지 의견을 여쭤보고 싶습니다.
감사합니다.