이번에 리뷰할 논문은 NeurIPS2021에 게제된 HRFormer라는 논문입니다. 이름을 딱 보면 제가 앞전에 리뷰한 HRNet에서 CNN을 transformer로 바꾼 느낌이 살살 납니다. HRNet도 정말 충격적이고 좋다고 생각했는데 여기에 transformer까지 접목됐으니 매우 기대됐는데 역시나 성능도 뛰어나면서 동시에 가볍고 빠르기까지 합니다.
자세한 내용은 리뷰를 통해서 작성해보도록 하겠습니다.
Introduction
마치 옛날에 VGG, ResNet이 그랬던 것 처럼, Vision Transformer가 vision task에서 좋은 성능들을 보여주고 있습니다. 물론 ViT 자체는 네트워크의 구조적 한계로 classification을 하는데에만 적합하였으며 다양한 dense level prediction을 하는데에는 큰 무리가 있었습니다.
그러나 2021년도에 들어서 정말 다양한 Transformer backbone들이 제안되어왔는데, 가장 대표적으로 Swin, CSwin, Pyramid Vision Transformer 등이 존재합니다. 각각의 백본들의 공통점은 계층적 구조를 가짐으로써 high resolution의 이미지를 넣는다 하더라도 self-attention의 연산량을 줄일 수 있다는 점이 있으며 다양한 스케일을 다루다보니 scale 개념이 중요한 vision domain에서 더 좋은 결과를 보여줄 수 있었습니다.
하지만 이런 계층적 구조는 classification과 같은 image level prediction에서는 최적이지만 사실 segmentation과 같은 pixel-level prediction에서 살짝 아쉬운 결과를 보여줍니다. 그 이유는 입력 해상도와 동일한 output map을 만들기 위해서 추가적인 decoder module을 설계하여 연산을 수행하는데, 이 때 압축된 high-level feature map만으로는 디테일한 정보들을 표현하는 것은 거의 불가능합니다.
물론 Encoder feature의 정보를 decoder에 전달해주는 Long Skip Connection을 통해서 어느정도 디테일한 정보를 보완할 수 있도록 해주지만, 그럼에도 한계는 명확하게 존재했었죠.
이러한 관점에서, 네트워크의 구조를 계층적으로 적용하면서 동시에 low level의 feature map들도 병렬적으로 연산하여 디테일 정보를 손실없이 가져오면 되지 않을까? 라는 생각을 가진 백본이 있었는데 이는 바로 HRNet이었습니다.

보통 그림1과 같이 병렬적인 구조를 사용하지 않고 직렬적인 계층적 구조를 사용하는 이유는 고해상도의 feature map을 계속해서 연산하게 될 경우 너무 큰 연산량이 필요하여 속도가 느려질 것이다라는 가정이 있는데, HRNet은 이러한 편견을 깨트린 좋은 논문이라고 생각됩니다.
제가 이번에 리뷰할 HRFormer는 HRNet과 거의 동일한 구조를 가지고 있으며 차이점은 그림1에 파란색 부분이 컨볼루션 연산이 아닌 Transformer와 같이 Multi-Head Self-Attention(MHSA)과 MLP연산을 수행하는 것이죠.
그림2에서와 같이 MHSA 연산을 어떻게 수행하였는지, MLP는 연산은 어떻게 하는지에 대해서 해당 논문의 특별한 아이디어가 들어간 것을 제외하고는 크게 중요한 내용은 없습니다.

Method
먼저 HRFormer의 MHSA 연산에 대해서 알아봅시다. 일단 Feature map X \in R^{N\times D}은 K \times K 크기를 가지는 P개의 non-overlapping small window로 나뉘어질 수 있습니다 X \rightarrow \{X_{1}, X_{2}, ..., X_{P}\}.
이러한 윈도우들 내에서 아래와 같은 MHSA 연산이 이루어지게 됩니다.
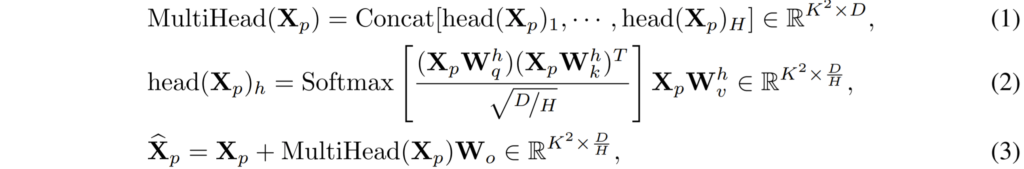
수식 3개가 한번에 나와서 당황스러우실 수 있지만, Transformer의 Multi-Head Self-Attention 연산을 아시는 분들이라면 매우 쉽게 이해하실 수 있을 것이라 판단됩니다.
수식2에 대해서 먼저 얘기 하면, head(X_{p})_{h}는 하나의 Self-Attention 연산을 나타낸 식입니다. X_{p} 는 window 내의 픽셀 벡터로 이해하시면 되고, W^{h}_{q}, W^{h}_{k}, W^{h}_{v} 는 각각 Query, Key, Value vector를 만드는 weight 값들을 의미합니다.( h의 경우 몇번째 Head를 의미하는지를 나타냅니다.)
아무튼 수식2를 통해 계산된 결과값을 모두 모은 것이 수식1에 해당하며 그렇게 모은 결과 값에 한번 더 projection layer를 통과시켜준 후 이전의 입력인 X_{p}와 residual 연산을 수행해주면 전반적인 transformer의 과정이 마치게 됩니다.
여기까지가 그림2-(a) 과정이고 그 다음으로는 그림2-(b) 과정을 진행하게 됩니다.
일반적인 Transformer는 MHSA 연산 이후에 Layer normalization을 거친 후 2개의 FC layer와 GELU로 구성된 MLP 연산을 수행하게 됩니다. 하지만 HRFormer는 그림2-(b)에서 볼 수 있다시피 1×1 convolution 연산과 3×3 depth-wise convolution 연산만으로 이루어져있습니다.
일반적으로 3×3 depth-wise 및 1×1 convolution 연산은 depthwise separable convolution 연산이라고 해서 3×3의 depth wise convolution과 1×1 convolution을 통해 연산량을 채널크기 만큼 줄임과 동시에 일반적인 3×3 컨볼루션 연산처럼 진행할 수 있다라는 장점을 가져 모바일 넷과 같은 가볍고 빠른 네트워크에서 사용된 방식입니다.
HRFormer 역시 빠른 inference 속도를 위해서 MLP 대신에 depthwise separable convolution 연산을 사용한 것 같아 보이기도 하는데 논문에서는 조금 더 놀라운 이야기를 합니다.
바로 이 3×3 depth-wise convolution 연산을 통해 locality를 강조하며 동시에 다른 window들과의 상호작용이 가능하다는 점입니다. locality는 뭐 1×1 컨볼루션 연산을 통해 세세한 부분을 보았다라고 이해하면 될 것 같지만 non-overlapping window들 간에 상호작용이 가능케 했다는 말은 사실 쉽게 이해하기는 어려웠습니다.
offset 연산을 통해 receptive field를 확장시킬 수 있는 deformable convolution도 아니고 그냥 채널별 컨볼루션 연산하는 depth-wise convolution이 어떻게 겹치지 않은 윈도우들간에 관계를 고려할 수 있는지에 대해 상식적으로 납득하기 어려웠습니다.
그나마 논문에서는 아래 그림과 같인 방식으로 윈도우들간에 상호작용을 할 수 있다는데… 처음에는 많이 당황스러웠습니다.
그림3대로라면 컨볼루션 연산이 결국 어떠한 윈도우에 경계면에서 수행될 때 한쪽 경계면과 다른쪽 경계면이 만나는 지점에서는 서로 섞여서 연산이 될 것이고, 중앙부분을 보면 4개의 영역 모두에서 값을 일부 가져와 연산을 수행하기는 합니다.
하지만 그렇다고 해서 이게 해당 영역에 극히 일부인 가장자리만을 보는 것이지 해당 영역의 전반적인 부분들을 서로 상호작용하고 하는 것이 아니다보니 이게 무슨 겹치지 않는 영역들간에 연산을 수행하는 것이지..? 라는 생각만 들게 되었습니다.
사실 Swin같은 경우에도 전체 feature map에 대해서 attention 연산을 수행하는 global 방식이 아닌 겹치지 않는 윈도우 내에서만 attention 연산을 수행하는 local 연산 방식을 취하고 있었고 이러한 local attention 연산의 단점을 최대한 극복하고자 window를 shift하여 새로운 영역에서 다시 local attention 연산을 수행토록 했었습니다.
이처럼 Swin은 윈도우 자체가 이동을 해서 다시 해당 영역 내에서 attention 연산을 수행하니 다양안 영역들간에 관계를 잘 볼 수 있다라는 이해가 한눈에 가지만, 이 3×3 컨볼루션 연산은 그냥 테두리 부분만 조금 본 것이 아닌가..? 라는 생각인 것이죠.
그래서 이부분에 대해서는 아직도 아리송하지만 한대찬 연구원과 얘기를 나눠본 끝에 내린 결론은 이 3×3 depth-wise convolution 연산을 통해 각각의 윈도우들 사이에서 주변 윈도우에 정보들을 조금씩 반영하였으며, 이렇게 반영된 가장자리 픽셀들이 다시 attention 연산을 통해 자신들이 속한 window 내에서 이리저리 중요도 스코어를 계산하다보니 결과적으로는 각 윈도우 내의 모든 정보들을 마주하게 된다 라는 것입니다.
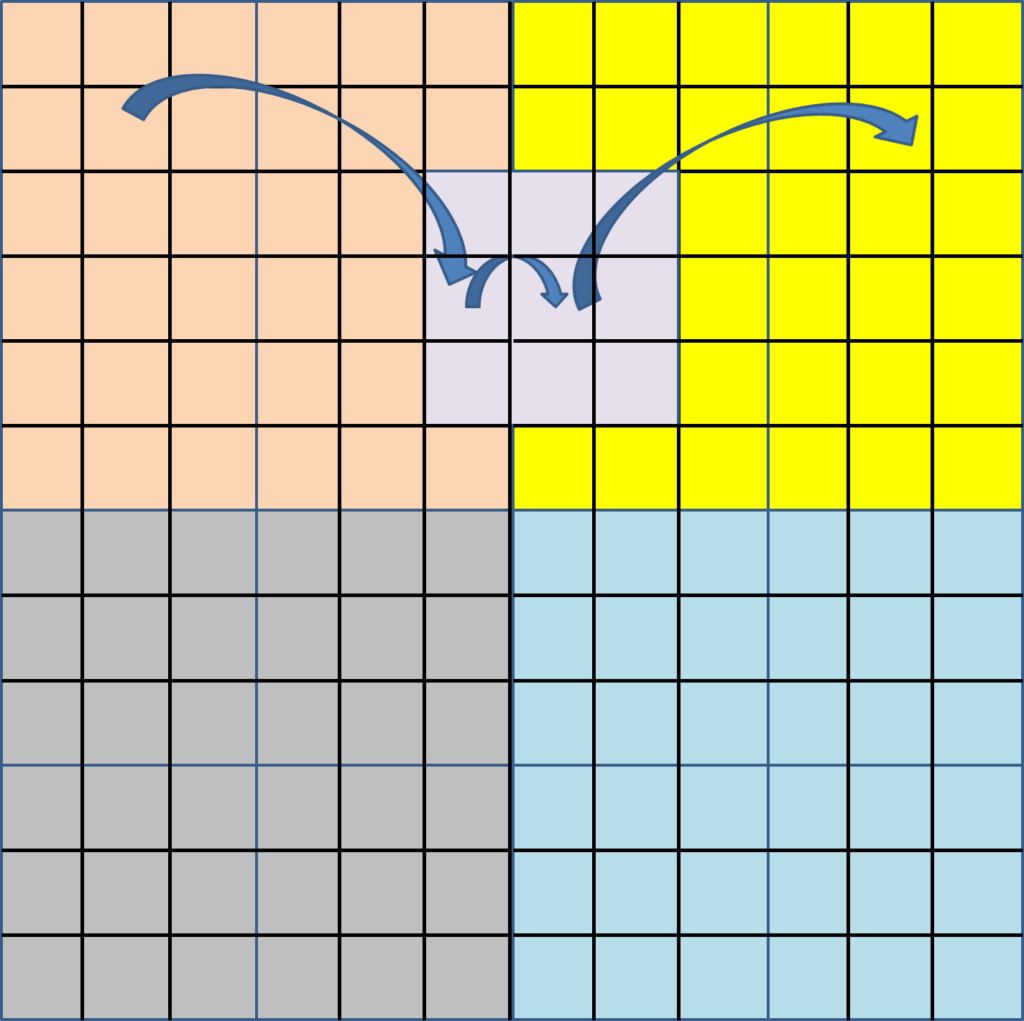
위에 내용을 그림으로 나타내면 그림4와 같이 3×3 컨볼루션(보라색)커널의 중앙부분 픽셀은 앞전에 attention 연산을 통해 노란색 window 내 모든 픽셀들과의 중요도가 반영되어 있는 상태일 것입니다. 마찬가지로 노란색 윈도우와 바로 경계를 맞닿은 살구색 영역들 역시 attention 연산 과정에서 살구색 모든 영역들과의 중요도 연산을 수행했었을 것입니다.
그 다음에 이제 컨볼루션 연산을 통해 살구색 영역의 모든 픽셀들과 중요도 연산을 해본 3개의 픽셀들이 노란색 영역으로 반영이 됩니다. 이렇게 반영된 픽셀들은 다시 attention 연산을 통해 노란색 영역들 전체로 정보가 전달을 주고 받겠죠.
이러한 과정을 통해서 local attention 연산의 단점을 해결하여 global receptive field를 가지고자 했구나…라고 이해를 했습니다만 해당 방식은 기존의 직접적인 방식과 비교하였을 때 너무 간접적이고 이것만으로 global receptive field를 가질 수 있는가에 대한 의문이 있었습니다.
하지만 저자도 이를 의식했는지 Swin의 Shifted window scheme 방식과 자신들의 3×3 depth-wise convolution을 HRFormer와 Swin transformer 모두에게 따로따로 적용하는 ablation study를 통해 자신들의 방식이 오히려 Swin의 shifted window scheme 보다 훨씬 더 우월하다는 점을 보입니다.(아니 이게 되네..)
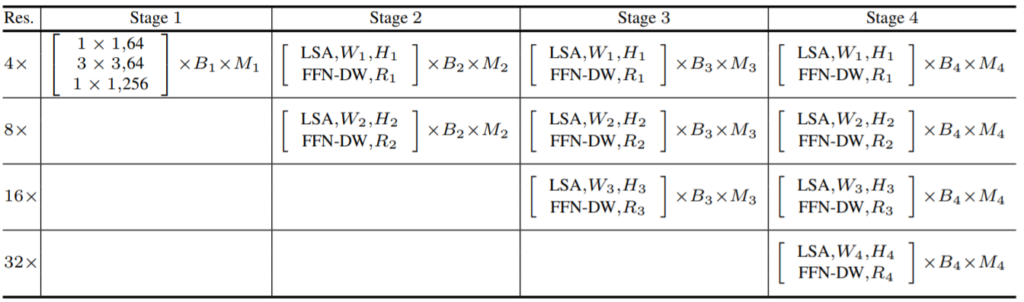
아무튼 이러한 과정을 통해 Transformer block에서 수행되는 연산에 대해서 알아보았고 결과적으로 HRFormer는 위의 연산 과정을 거치는 Transformer Block들로 구성된 모듈들로 구성된 스테이지로 구성되어 있습니다. Block \in Module \in Stage 라고 볼 수 있죠.(그림1 다시 참조)
각각의 스테이지가 몇개의 모듈과 블록으로 구성되어 있는지는 다음 표와 같습니다.

Experiments
다음은 실험파트인데, HRNet과 달리 Object Detection을 제외하고 Classification 결과를 추가해 Human Pose Estimation, Semantic Segmentation, Classification 결과를 리포팅하였습니다.
이번 x-review에서는 Semantic Segmentation과 Classification 결과에 대해서만 리포팅하도록 하겠습니다. Human pose estimation 결과도 보고싶으신 분들은 직접 논문을 참조해주시면 좋을 듯 합니다.
Semantic Segmentation
먼저 segmentation으로는 Cityscape와 Pascal-Context, CoCO-Stuff dataset에 대해서 평가를 진행하였습니다.
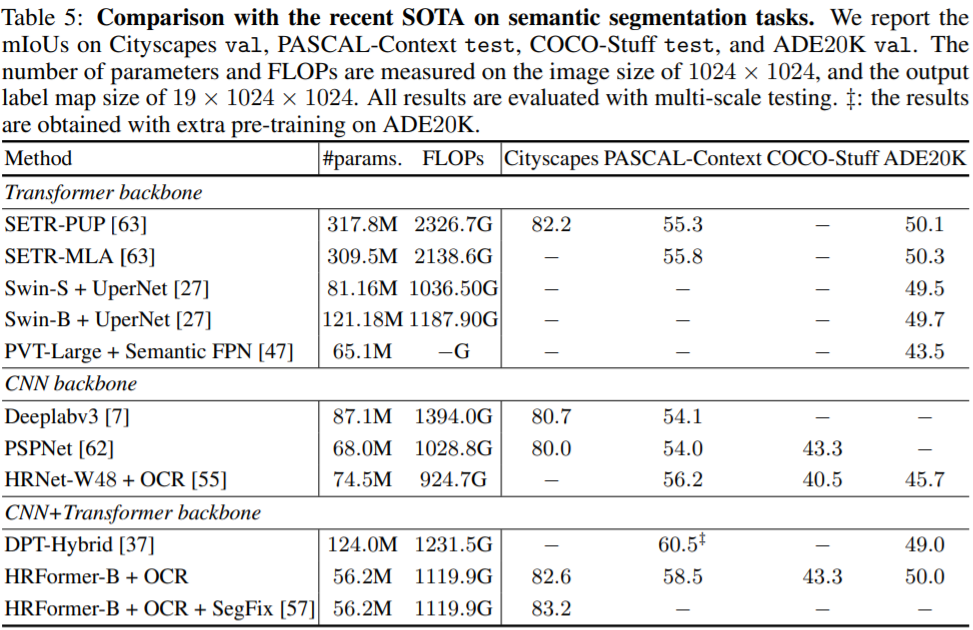
Transformer 기반의 방법론들과 CNN 방법론들 그리고 HRFormer를 비교하는 모습입니다. HRFormer에 경우 CNN+Transformer backbone으로 표현되어있는데, 아마 HRFormer가 1st stage에서는 단순한 컨볼루션 레이어 3~4개로 구성되어있기 때문에 그런게 아닐까 싶습니다. (Transformer 방법론들은 그냥 바로 컨볼루션 레이어 하나만으로 image를 패치로 쪼개는 작업을 수행하기 때문이죠)
아무튼 HRFormer의 경우 크기가 Base임에도 불구하고 Swin-S보다 파라미터 수가 약 30%가량 작으면서 ADE20K에서 조금 더 좋은 성능을 보여주고 있습니다. 구조적인 특징은 거의 동일한 HRNet과 비교하였을 때도 역시 파라미터수가 20% 가량 더 적은 반면에 정확도는 모든 데이터셋에서 큰 폭으로 이기는 모습을 보여줍니다.
이를 통해 Dense-level prediction에서 Transformer의 장점은 어마어마하다라는 것을 다시 한번 볼 수 있었네요.

Classification
다음은 ImageNet에 대한 성능 결과입니다.
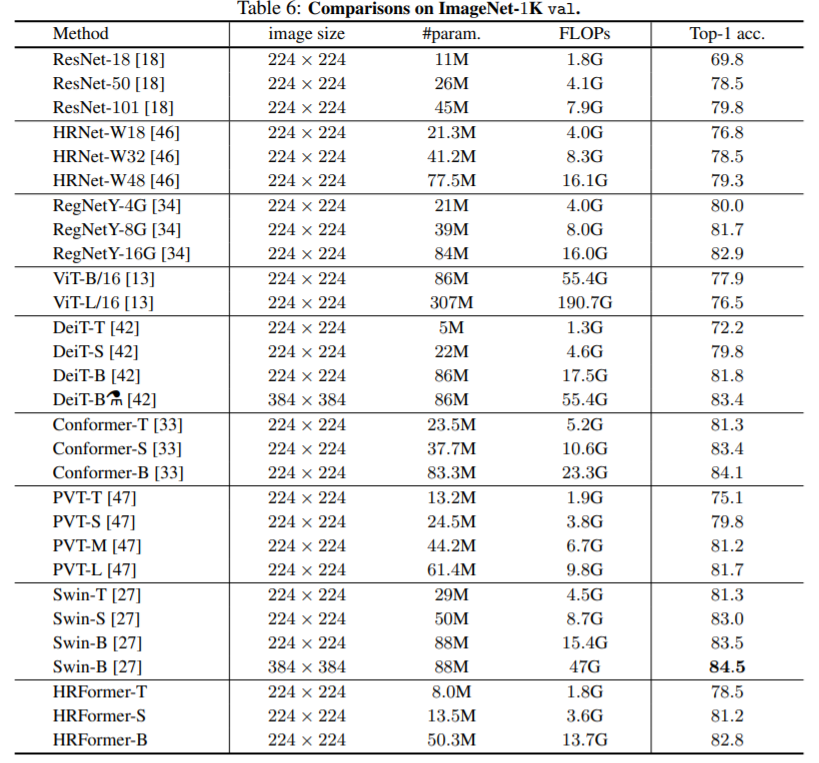
여기서 정말 인상깊었던 점은 HRFormer-T는 ResNet과 비교하였을 때 모델 크기도 가볍고 속도 역시 동일함에도 불구하고 성능은 약 8.7%로 큰 차이를 낸다는 점입니다. 이러한 성능은 기존의 Transformer 방법론들과 비교하여도 충분히 경쟁력 있으면서 동시에 훨씬 빠른 속도와 가벼운 모델을 크기를 가졌다는 점이죠.
속도와 성능 이 trade-off 관계를 정말 잘 해결했다고 볼 수 있겠네요.
Ablation study
다음은 Ablation study입니다. 가장 궁금한 점이 그래서 3×3 depth-wise convolution을 통해서 local attention의 문제를 해결할 수 있는 것이 맞나? 일텐데 해당 컨볼루션 연산을 통해 global receptive field를 확보함과 동시에 추가적인 성능 향상에도 도움을 주었다는 결과를 볼 수 있습니다.
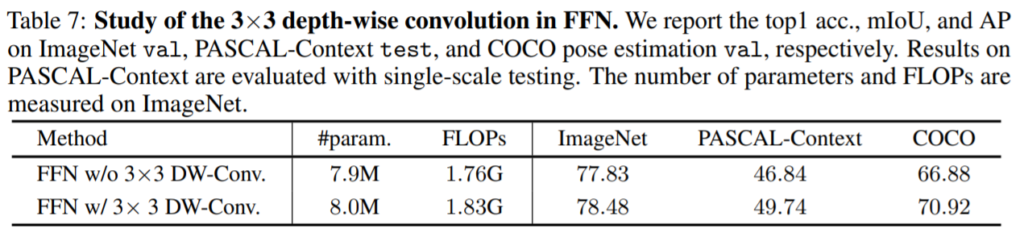
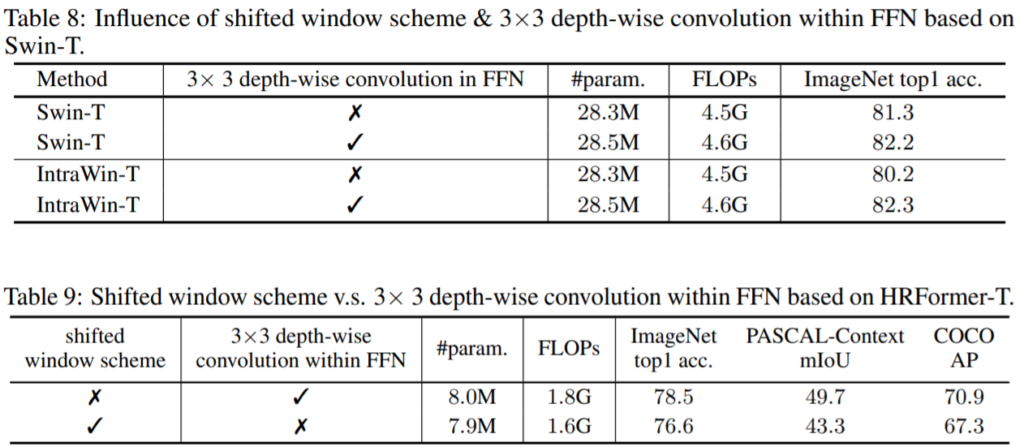
위에 표들은 차례대로 MLP연산에서 3×3 컨볼루션 연산을 사용하였을 때 각 테스크별로 성능의 향상도, Swin과 IntraWin transformer에게 3×3 depth-wise convolution을 추가로 적용하였을 때, 마지막으로 HRFormer에게 Shifted window scheme과 3×3 depth-wise convolution을 따로 적용하였을 때 결과입니다.
먼저 depth-wise convolution을 적용한 것만으로 COCO와 Pascal-Context 등 semantic segmentation에서 매우 큰 성능 향상을 볼 수 있었습니다. 이는 Classification보다 더욱 global receptive field가 필수적인 Dense-level prediction에서 3×3 depth-wise convolution이 겹치지않는 window들 간에 상호작용을 도와준다고 볼 수 있을 듯 합니다.
추가로 테이블 9을 통해 Shifted window scheme보다 자신들의 depth-wise convolution이 훨씬 더 좋은 결과를 보여줌으로써 우수한 방식이다라는 것을 강조하고 있네요.
결론
HRNet을 봤을 때도 그랬지만 HRFormer는 HRNet만큼 참신했던 논문으로 보입니다. 사실 HRNet 구조 자체가 너무나 충격적이어서 HRFormer는 그저 HRNet 구조에 stage 과정을 transformer로 붙인 것 밖에 없지 않나? 싶은 생각이 들었지만, 이 3×3 depth-wise convolution 연산이 너무나도 놀라웠네요.
제 생각에는 지금 Transformer 자체가 feature map 전체에 대한 global attention 연산을 수행하는 것이 아닌, 일정한 겹치지 않는 윈도우 영역 내에서 attention 연산을 수행하는 것이 대세인 듯 합니다. 이때 발생할 수 있는 local receptive field를 어떻게 잘 해결할 것인지를 위해 Swin처럼 window를 shift한다던지 등 대부분은 attention 연산을 수행하는 영역 자체를 움직이려는 방향으로 연구가 진행되었습니다.
하지만 HRFormer는 윈도우를 이동하는 것이 아닌, 단순한 컨볼루션 연산을 통해 이웃 픽셀들이 조금이라도 넘어가기만 하면 된다는 방식을 통해 모델의 복잡한 구조와 처리 과정을 생략하고 단순화시켰다는 것에 혁신적이다라는 생각이 들었습니다. Dense-level prediction과 관련된 분야를 연구하실 분들이라면 한번쯤은 HRNet과 더불어 HRFormer도 읽어보셨으면 좋겠다 라는 생각이 드네요.
성능이 진짜 압도적인 것 같습니다. HRNet이 대단해서 이런 결과를 볼 수 있었다라는 생각이 드네요. 정말 그 Depth wise convolution이 저희가 생각한 이유로 넣었을지가 궁금하긴하네요