이번 논문을 작업하면서 읽은 video retrieval과 관련된 논문입니다. Video Retireval에서도 Video level feature를 바탕으로 하는 방법론은 많지 않습니다. 해당 방법론은 frame level을 바탕으로 video level feature를 만들어 video retrieval을 수행하는 방법론입니다.
해당 논문의 핵심은 아래와 같습니다.
- Compact한 frame & video level feature
- Self attention mechanism을 이용해 feature의 long range temporal information 보장
- 느린 triplet loss를 대체할 contrastive learning
깊은 내용을 다루고 싶지만, 두번째 핵심 내용은 tranformer를 적용했고, 세번째 내용은 일반적으로 contrastive learning과 circle loss 자체도 다른 곳에서 제안한 내용이라 이 방법론을 어떻게 video retireval에 적용했는지에 대한 내용이 중심인 것 같았습니다. 그럼 본격적인 내용으로 바로 들어가겠습니다.
Feature Extraction
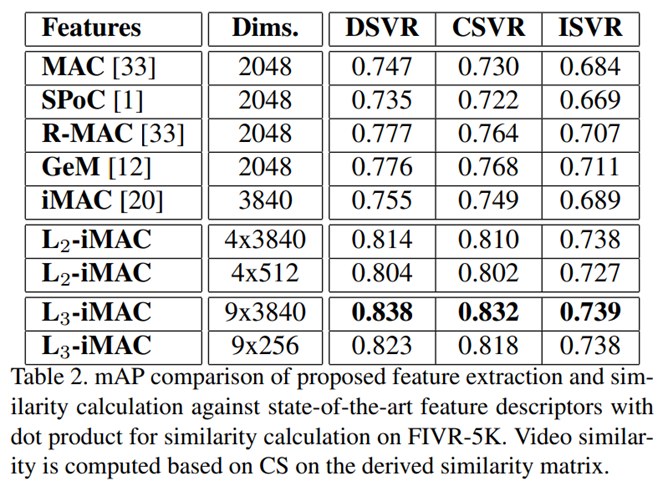
TCA에서는 feature extraction 방법론으로 iMAC과 수정된 L3-iMAC(여기서는 L3-iRMAC)을 사용합니다. 이 2가지를 선택하게 된 이유는 ViSiL의 실험 결과를 참고했다고 합니다. 위의 표가 ViSiL에서 실험한 각 방법론에 따른 성능 차이를 비교한 표입니다. 이 표를 보면 R-MAC과 L3-iMAC의 성능이 우수한 것을 확인할 수 있습니다. 하지만, L3-imac을 그대로 사용할 경우 당연히 compact하다고 말하기는 어렵기 때문에 기존의 R-MAC의 방법론을 따라 계층적으로 구성된 L3-iMAC의 output인 3×3 feature map을 더해 하나의 feature map으로 만들어서 사용합니다. 그리고 해당 방법론을 L3-iRMAC이라고 부르고 사용합니다. 이렇게 사용하는 이유는 spatial information의 보존과 낮은 차원에서 오는 compact 사이의 trade-off를 고려했다고 합니다. 최종적으로 이렇게 추출된 feature는 PCA와 L2 norm이 적용됩니다.
Temporal Context Aggregation
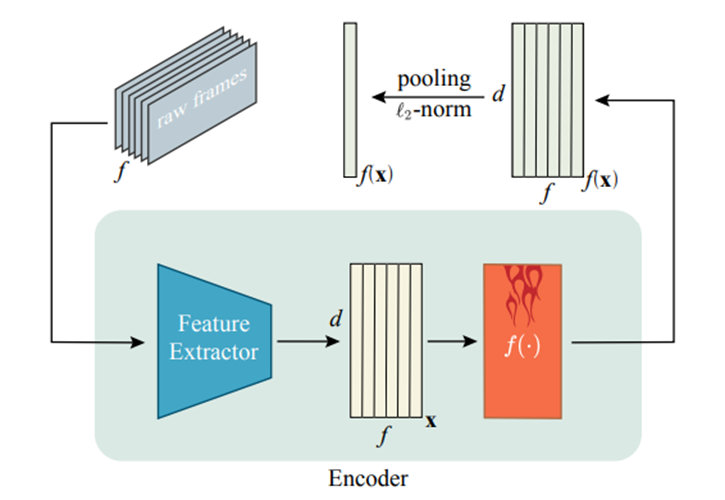
위 그림은 논문에서 feature encoding 파이프라인을 도식화한 그림인데요. 앞 문단에서 설명한 것과 같이 feature를 뽑고, encoder라는 것을 사용합니다. Transformer의 encoder 구조를 사용하는데요, Q는 Query, K는 Key, V는 Value입니다.
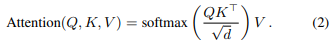
이 인코더가 바로 이 논문에서 말하는 self-attention mechanism입니다. 해당 방법론을 적용하면, encoding된 feature가 동일한 shape를 유지하면서 각각의 frame-level descriptor에서 긴 범위의 contextual information가 합쳐질 수 있다고 합니다. 이렇게 transformer를 태운 값이 frame level descriptor이고, video level descriptor는 frame level descriptor를 시간 축에 따라 평균을 취해주면 compact하게 나온다고 합니다.
실제 TCA에서는 이를 frame_mask라는 값과 곱하는데요. 비디오의 길이가 모두 다르기 때문에, 같은 길이로 맞춰주는 작업이 필요하기 때문에 실제 영상의 길이 만큼은 1, 아닌 부분은 0으로 된 frame_mask라는 배열과 곱해서 최종적으로 feature를 만들어줍니다.
Contrastive Learning
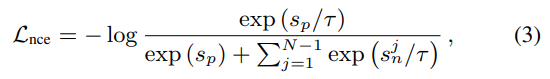
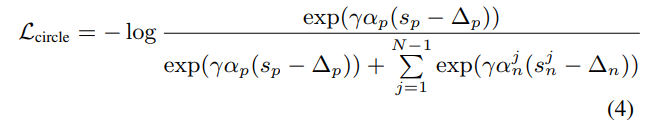
Loss는 NCE loss와 Circle loss를 비교해서 설명하고, 수식의 S_p는 anchor video와 positive video의 유사도, S_n은 anchor video와 negative video간의 유사도를 말합니다. 두가지 모두 논문 저자가 ViSiL에서 사용하는 triplet loss가 느리다고 말하여 이를 대체하기 위해 제안하는 방법론입니다. 가장 큰 차이점은 triplet loss에서는 anchor, positive, negative를 사용하지만, TCA에서 쓰는 두 loss는 Anchor, Positive를 쓰는 것은 동일하지만, Negative examples로 많은 negative 비디오들을 한번에 사용합니다. 최종적으로는 Circle loss를 사용했다고 합니다.
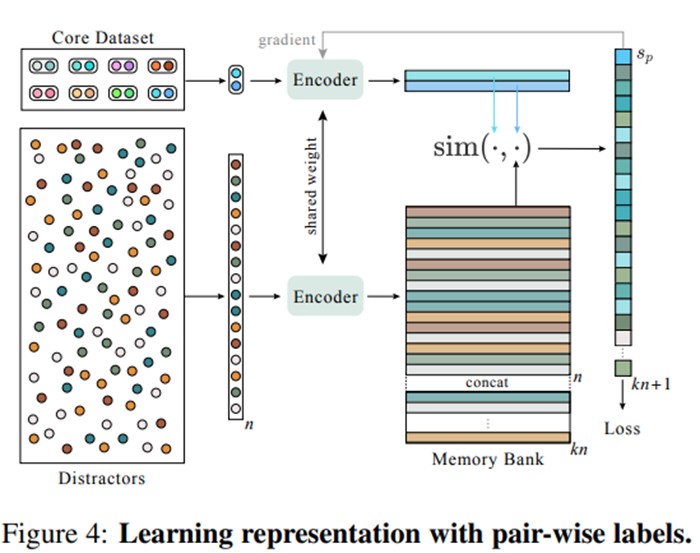
위에서 loss에 대해 설명 했을 때 negative 비디오들을 사용한다고 설명했는데요. 그럼 negative 비디오를 골라야 하는데, 고르는 방법은 따로 존재하지는 않습니다. TCA에서는 memory bank에 배치마다 n개씩 랜덤으로 선택해 배치합니다. 이런 구조를 통해 우리가 ViSiL의 triplet loss를 쓰기 위해 해야 했던 것처럼 최적의 negative 쌍을 계산할 필요 없이 효율적으로 학습이 가능했다고 합니다.
One step Further on the Gradients
이 파트는 이런 방식이 학습에 문제가 없다는 것을 증명하기 위한 파트입니다. TCA에서는 랜덤으로 negative 비디오를 선택해 사용하는데, 이 구조가 문제가 없을지에 대한 수학적인 내용이었습니다.
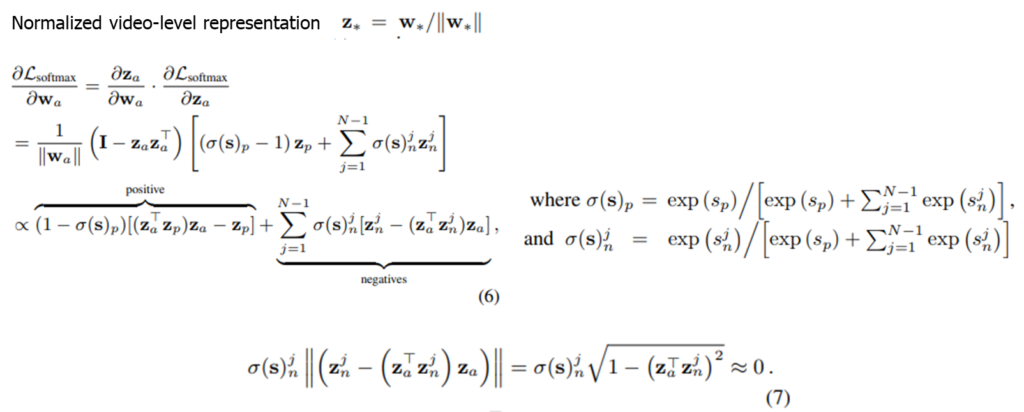
정규화된 videl level representation이 Z_* = W_* / ||W_*||라고 할 때, 위의 수식을 보면 positive와 negative의 loss를 구하는 과정이 풀이되어있습니다. 논문 저자는 L2 norm과 softmax based loss의 결합이 hard negative mining 작업을 자동으로 수행한다고 합니다. 이는 easy negative 로 골라진 negative sample들이 정규화되고 softmax를 취해주는 과정을 거치면서 앵커와의 유사도가 -1에 가까워지기 때문이라고 합니다.
Experiments
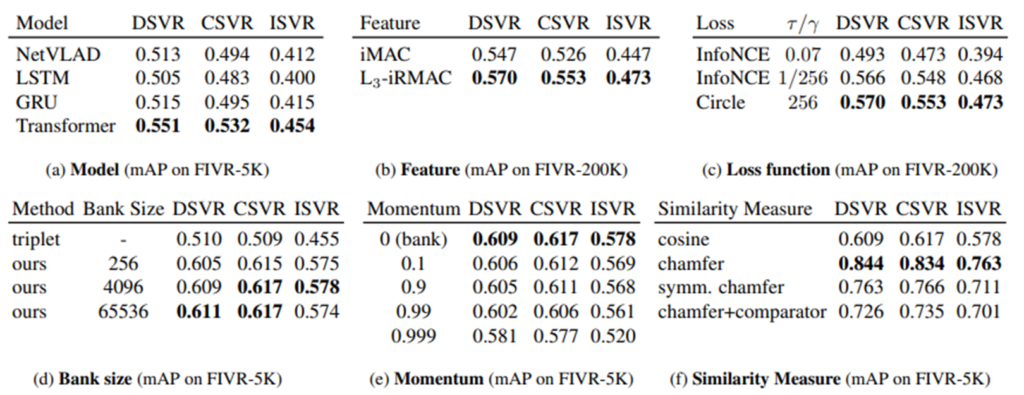
중점적으로 볼 부분은 실제로 memory bank가 triplet에 비해 괜찮은 방법론인가에 대한 실험도 저자가 수행했습니다. 실제로 triplet보다 성능이 잘 나온 부분을 볼 수 있습니다. 이 부분대로라면 속도와 성능 모두 빠르다는 내용이 됩니다.
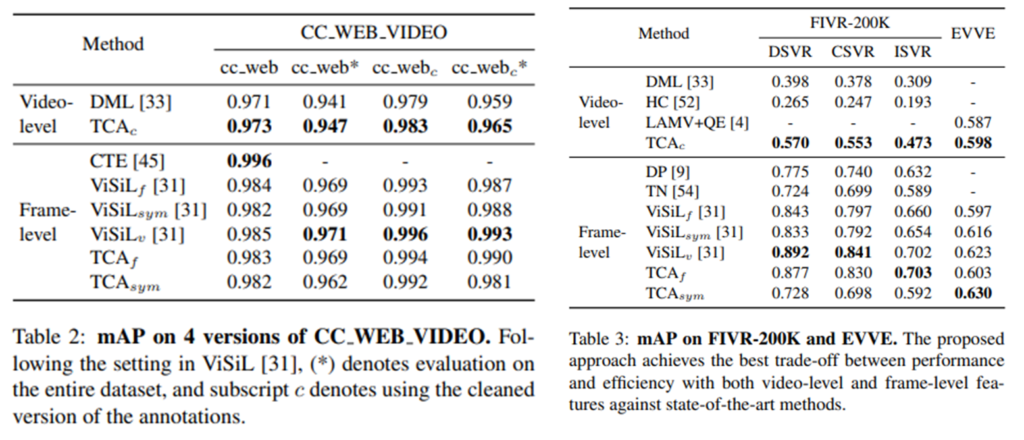
최종적으로 CC_WEB_VIDEO와 FIVR-200K에서의 실험 결과는 위와 같습니다. ViSiL과 성능이 비슷한 수준이긴 하지만, 기존의 Video-level방법론과 성능이 차이가 꽤 나는 점. 그리고 속도가 매우 빠르다는 점을 감안하면 놀라운 성능입니다.

마지막으로 이 그림은 TCA에서 self attention mechanism이 어떻게 동작하는지 정성적인 결과를 나타내는 그림입니다. 실제로 비디오에서 중심 사건(화재, 폭발, 사고)등에 집중하는 모습을 확인할 수 있었습니다.