제가 이번에 리뷰할 논문은 instance segmentation에서 합성 데이터를 생성하고 학습에 사용하는 방식에 대한 논문입니다. IPIU 논문의 방향이 합성 데이터를 이용한 instance segmentation 성능 향상이라 해당 논문을 읽게 되었습니다.
본 논문은 instance segmentation 성능 향상을 위해 합성 이미지와 실제 이미지를 결합하는 간단한 방식을 제안한다. instance labeling의 일치를 위한 harmonizing instance labeling과 가치 없는 instance 제거 전처리 방식을 제안한다. 또한 dataset 혼합 기반의 학습 방식을 제안하여 도메인 간의 차이 극복을 보인다. fine-tuning 방식과 비교 연구를 통해 해당 방법론의 효과를 검증한다.
Data Alignment
Data set Harmonization

학습을 하기 전 합성 데이터 Synscapes와 실제 데이터 Cityscapes의 데이터 특성(클래스 및 인스턴스 정의)이 동일한지를 먼저 파악하였다. Synscapes의 경우 그림 2와 같이 인스턴스 정의에서 탈것 과 승차자를 구분하지 않는 것이 Cityscapes데이터와의 차이였다. 따라서 이런 mismatch를 해결하기 위해 원본 Synscapes의 라벨링에 semantic segmentation을 하여 승차자와 탈 것을 구분하였다.
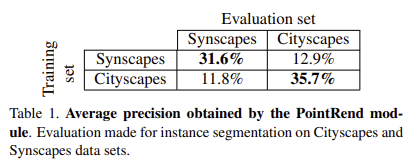
두 데이터셋의 주석이 일치할 경우 각각의 데이터셋을 이용하여 PointRend 네트워크에 학습시킨 후 test를 진행하였다. 그 결과 표 1의 성능을 얻을 수 있었고 이를 통해 두 데이터셋 간의 도메인 차이를 확인할 수 있다. 합성 이미지만을 이용한 학습은 실제 데이터에서 적절한 성능을 얻지 못하므로 합성 데이터와 실제 데이터를 적절히 사용하는 방식이 필요하다.
Methodology
1. Removing non-valuable synthetic instance
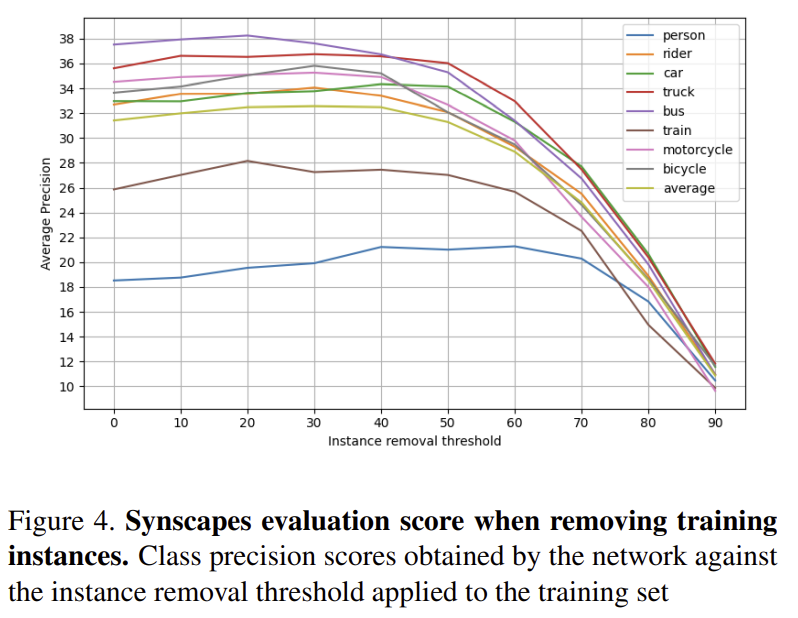
합성 데이터인 Synscapes 데이터는 영상 내의 instance 정보가 너무 많다. 적은 픽셀로 구성된 인스턴스도 학습에 사용되었을 때 가치가 있는지 의문이 들어 이미지 내의 instance 개수의 변화가 어떤 영향을 주는 지 실험을 하였다. 제거되는 instance는 클래스별로 픽셀의 수가 적은 것 부터 일정한 비율로 객체를 제거하였다. 그림3을 통해 임계값의 변화에 따라 제거되는 인스턴스의 예시를 확인할 수 있다. Synscapes 데이터는 Cityscapes 데이터와 동일하게 2975장(Cityscapes의 이미지 장수와 동일, 공정한 비교를 위해)으로 줄였고 임계값을 0~90% 까지 10% 단위로 증가시켜 10개의 버전으로 데이터셋을 만들었고 학습에 사용한 결과 그림 4와 같은 결과를 얻을 수 있었다. 클래스들의 추세는 대체로 유사하며 instnace의 개수가 조금 줄었을 때 성능이 약간 증가하는 것을 확인할 수 있다. ( ‘person’의 경우는 60%의 임계값을 적용했을 때 가장 성능이 높았다.) 이를 통해 약 40% instance들이 가치가 없다고 할 수 있고, 이러한 instance를 제거하기로 하였다.
인스턴스 제거를 통해 1)약간의 정확도 향상, 2) 연상량 감소, 3) Cityscapes와 레이블이 더 유사해지는 효과를 얻을 수 있었다.

임계값이 0일 경우 각 class 별로 제거되는 instance가 없고(원본), 90%의 경우 클래스별로 가장 큰 10%의 instance만을 남기고 나머지의 주석은 모두 제거한다. 0%와 40%, 80%의 빨간 박스 부분을 확인해보면 0%에서는 차와 사람들 객체가 존재한다고 주석이 달려있고 40%는 차의 주석이 달려있다고 80%는 주석이 없다.
2. Data set mixing approach
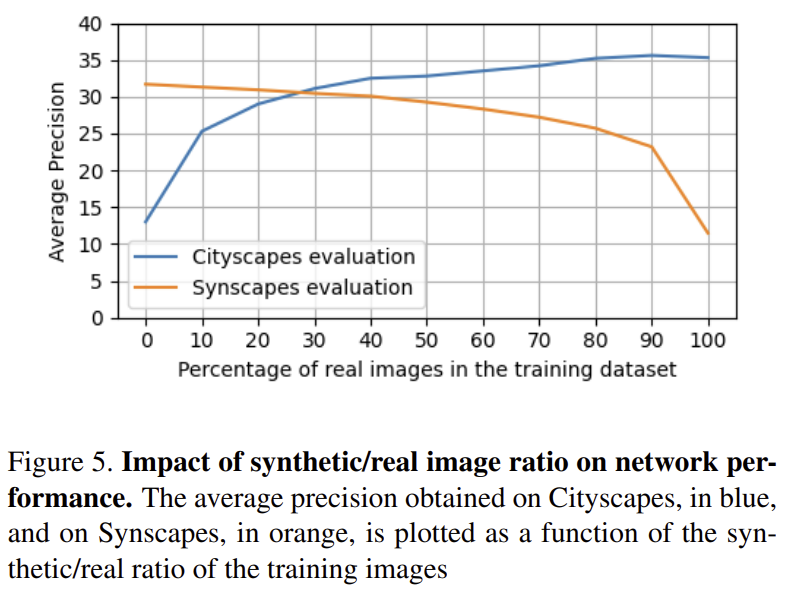
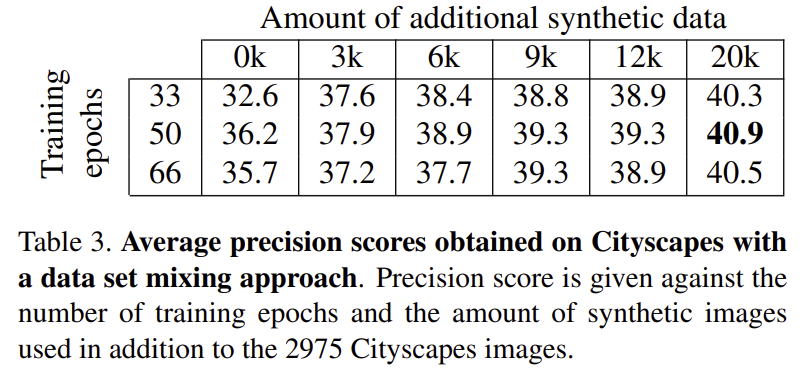
도메인간의 차이를 줄이기 위해 합성 데이터와 실제 데이터를 혼합하여 사용하였다. 학습시에는 실제와 합성 데이터를 구분하지 않지만 데이터를 적절히 혼합하기 위해 총 2975장(Cityscapes의 이미지 장수와 동일, 공정한 비교를 위해) 중 실제 데이터가 0~100%까지 10% 단위로 증가시켜 11개 버전의 데이터셋을 구성하였다. 이렇게 생성한 데이터셋을 이용하여 학습을 진행한 결과 그림 5와 같은 결과를 얻었다. 학습에 많이 사용되는 데이터에 대해 성능이 좋은 것을 확인할 수 있다. 0-10%의 경우 Cityscapes에서, 100-90%의 경우(Synscapes가 0-10%인 경우) Synscapes가 2배가랑 성능 차이가 있었다. 따라서 실제 이미지에 대해 정확도를 높이고자 한다면 합성 이미지보다 실제 이미지를 더 많이 사용하는 것이 바람직하므로 실제 데이터를 모두 사용하고 합성 데이터의 양을 조절해야 한다. 표 3을 통해 합성 데이터의 양 변화에 따른 성능을 확인할 수 있다.
3. Comparison study
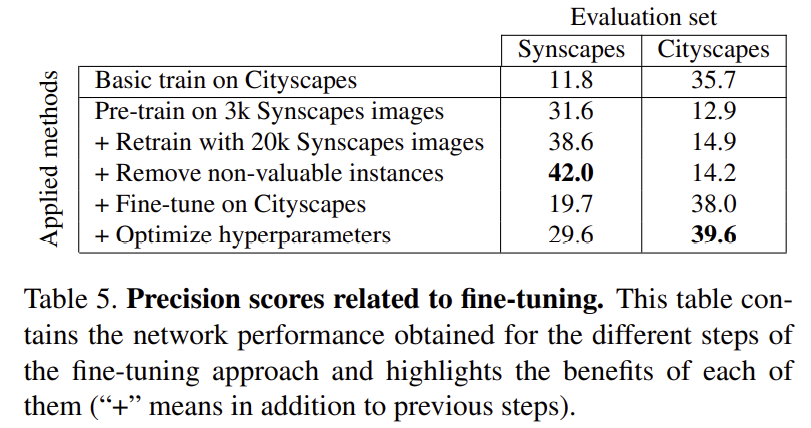
실제 데이터와 합성 데이터를 혼합하는 방식과 fine-tuning 방식을 비교한 섹션이다. 합성 데이터로 사전학습된 모델을 실제 데이터를 이용하여 fine-tuning하면 실제 데이터를 이용한 학습과 비교했을 때 35.7 ->38.0%로 정확도가 향상된다. 그리고 하이퍼 파라미터를 최적화하여 Cityscapes에서 39.6%의 정확도를 달성하였다. 따라서 논문에서 제안한 데이터 혼합 방식을 이용했을 때 보다 좋은 성능(40.6%)을 가지는 것을 확인할 수 있다.
해당 논문의 경우 제안한 방식이 크게 참신하지는 않지만 각각의 method가 (실험적) 근거를 가지고 있고, 각각에 대해서도 다양하게 실험을 진행하였습니다. 제가 작성하는 논문도 본 논문의 흐름을 적용해보면 좋을 것 같습니다.
가치없는 instance를 제거한다는 의미에 대해서 조금 헷갈리네요.
일반적으로 segmentation은 GT 자체가 부족하니 더 보충해도 모자를 것 같은데, 있는 instance를 제거한다는 것은 어떻게 이해하면 될까요? 해당 GT의 존재 자체가 학습에 부정적인 영향을 주니 버리자는 의미로 이해하면 되나요?
Synscapes 데이터는 실제 데이터가 아니라 생성된 데이터로 Figure3의 좌상단 (맨 처음)이미지를 보시면 주석이 많은 것을 확인하실 수 있습니다. 인스턴스의 대부분이 가려져도 해당하는 픽셀들을 특정 클래스로 보고 심지어는 이러한 인스턴스들이 아주 멀리에 있어 아주 일부의 픽셀만 남더라도 주석이 달려있습니다. 이러한 데이터의 특성상 모든 인스턴스를 이용하는 것이 좋을지에 대한 의문으로 instance를 픽셀 순으로 정렬하여 일정 비율 제거하는 실험을 하였고 그 결과 어느정도 데이터를 제거하는 것이 좋다는 결론을 내렸다고 생각하시면 될 것 같습니다.