(논문 마감 전 작성)논문 마감 전… 마지막 논문 리뷰가 인 것 같습니다. 하하 ㅎㅎ 그런 기념으로 이번에도 역시나self supervised monocular depth estimation 논문을 들고 왔습니다. 이 논문을 알게 된건 논문 작업을 하며 다른 방법론 정성적 결과나 뽑아보까 하면서 코드 있는 논문을 보기 위해 Paper with code를 들어갔는데 … 이게 뭐람 7일 전에 새로 나온 논문이 성능이 왤케 좋아 !?!?!??! 비상 비상!!!?!?~!?!?!! 느슨했던 논문 작업에 긴장감을 불어 넣는 논문의 등장이였습니다. 저희보다 성능이 좋으며.. 저희보다 모델이 가벼운 이 미친놈은 무엇이냐… 논문 쓰면 안되나….했습니다. 허허 이 논문 공개가 CVPR 제출 다음이라서 다행입니다… ㅋㅋ
(논문 마감 후 작성) 다행히 저희 방법론을 조물닥 조물닥해서 더욱 좋은 성능을 보여서 리뷰어가 말하더라도 성능을 좋다! 라고 말할 수 있게 됐습니다 ㅎ.
그럼 이 논문의 장점은 무엇이며 어떤점이 기존과 압도적인 성능을 나타내게 했는지 알아보도록 하겠습니다.
먼저 이 contribution을 정리 하자면 다음과 같습니다.
- 기존에 방법론들과 다르게 Semantic segmentation 에서 사용되고 있는 HRNet을 backbone으로 사용해서 모델이 semantic 정보를 강화해서 성능을 향상 시켰습니다.
- feature fusion 방식을 새롭게 제안하여 semantic 정보의 차이가 있는 encoder feature와 decoder feature의 gap을 줄여줄였습니다.
- KITTI에서 SOTA
1.DIFFNet
이 논문에서는 Monodepth estimation task에서 예측되는 Depth 에 Semantic 정보를 더욱 부여하기 위해서 HRNet을 기반으로 Depth network를 짰습니다. 이 HRNet 에 관한 설명을 신정민 연구원이 이 리뷰에서 잘 설명해뒀으니 참고하시면 될 것 같습니다.
row- 와 high- resolution 전부를 사용함으로써 디테일 정보와 semantic정보를 모두 사용할 수 있는 이 HRNet을 backbone 네트워크로 사용하니 ResNet을 사용할때보다 높은 성능 향상을 이뤘다고 합니다.
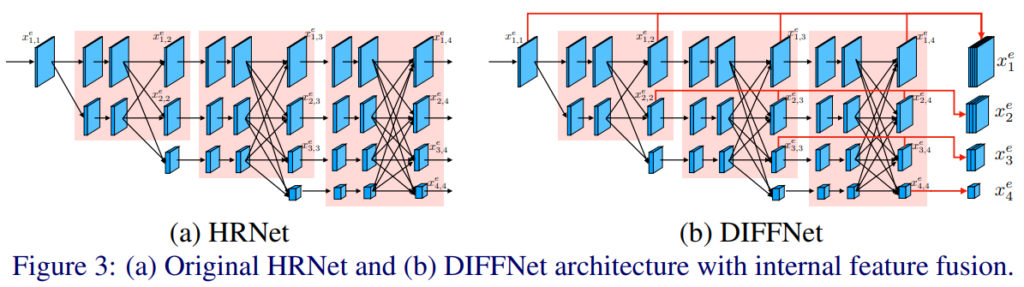
단순히 ResNet에서 HRNet으로만 변경해도 성능향상을 보여주는 이 네트워크의 장점을 더욱 살리기 위해서 저자는 위 그림-(b)처럼 새로운 네트워크를 설계했습니다. residual 하게 이전 feature를 최종적으로 활용함으로써 다양한 feature가 가지고 있는 semantic 정보를 decoder에 전달을 하며 이러한 과정은 추가적인 네트워크를 사용하는 것이 아니라서 network의 prameter가 증가하지 않는 이점이 있습니다.
2. Attention based Depth Decoder
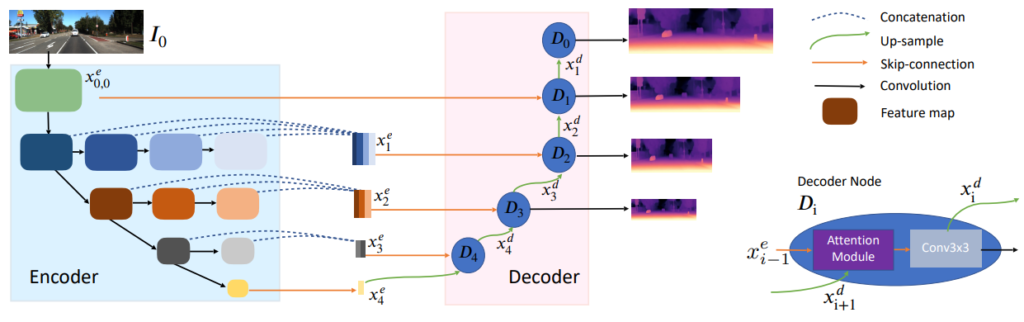
이 논문에서는 위에서 설명한 DIFF를 백본으로 사용하고 각 resolusion의 feature를 합치기 위한 새로운 decoder를 제안합니다. 위 그림에 보이는 Decoder Node의 attention module 이용해 decoder feature 와 skipconnection을 통해 받아온 encoder feature을 더욱 잘 융합하며 feature로써의 성능을 강화시켰습니다. attention module의 식은 아래와 같습니다.
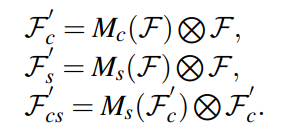
총 세가지의 attention 방식을 사용해보았고 그중 가장 괜찮았던 channel attention 을 최종 attention 방식으로 사용했다고 합니다.
Result
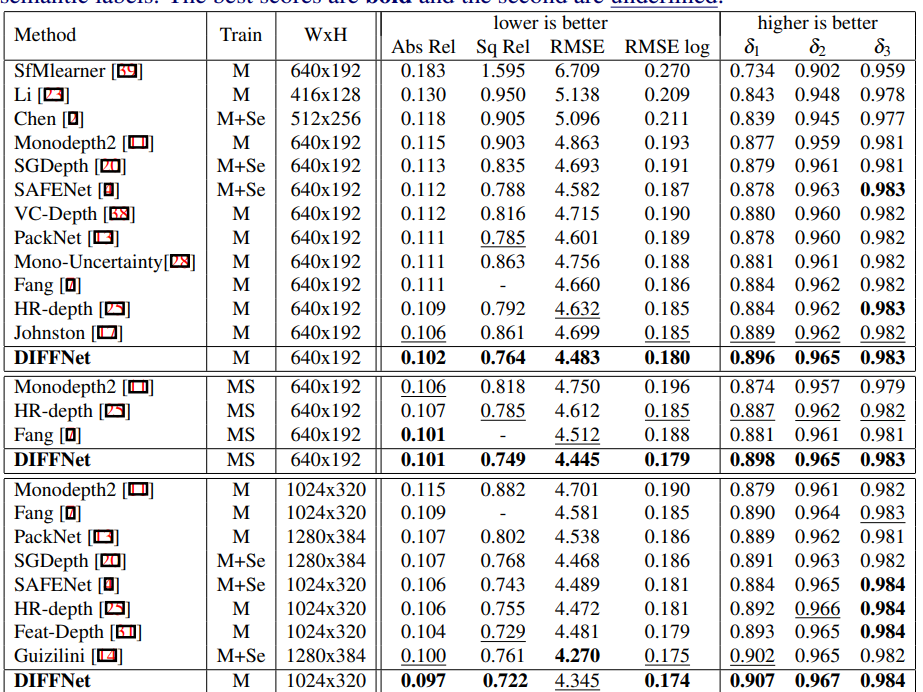
사실 방법론 자체는 굉장히 간단하고 제안하는 것 또한 그렇게 뛰어나다고 생각이 들지는 않지만, 성능이 어마무시합니다. 기존 방법론들을 다 씹어먹어버리는 성능이죠( 물론 저희 방법론이 더욱 좋은 성능을 보이긴 합니다.)
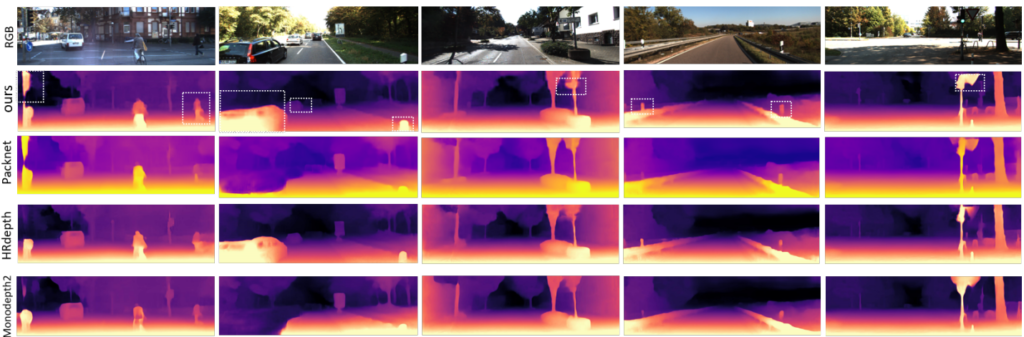
정성적 결과 또한 깔끔합니다. 다양한 resolution을 다뤄서 엣지또한 잘 따고 물체를 잘 표현합니다.
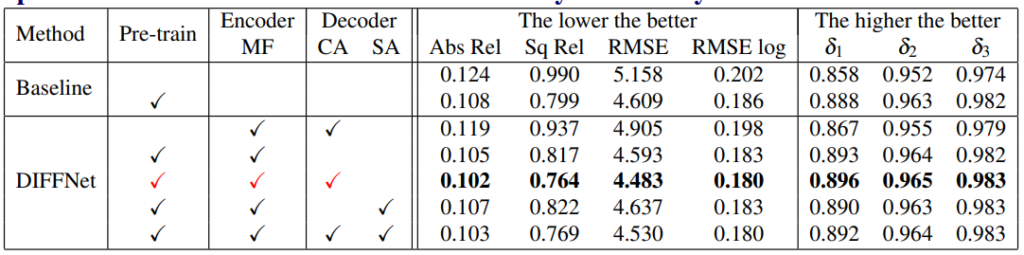
제일 궁금했던 ablation study 결과 입니다. 확실히 단순히 HRNet을 사용만했을 뿐인데 0.108 이면 좋은 성능을 보이는 것 같습니다. DIFFNet 쪽 실험에서 DIFF+pretrained only가 궁금한테 없네요 단순히 DIFF로 변경했을때의 성능이 궁금했는데. 보면 attention 방식이 spatial attention을 사용할 경우 cnn에서는 성능 저하가 있는 것 같습니다.
말씀하신것처럼 간단하지만 백본을 변경하는게 때로는 효과적임을 보여주는 논문이네요. 그럼에도 개선하여 최종 억셉까지 될 수 있었던것 같습니다. 궁금한점은 이번에 제출하신 CVPR 논문도 Paper with code에 올리실건가요?
안올리지 않을까 싶습니다
리뷰가 상당히 간단해보이는만큼 해당 논문 자체의 내용도 큰 내용이 없긴 했죠ㅋㅋ..
저희 논문은 해당 논문과 달리 내용이 풍부하게 보였으면 하네요