이번 리뷰는 paper with code 기준 SOTA를 달성한 방법론에 대해 이야기하고자 합니다. 해당 방법론은 MVTec 데이터 셋에서 99.4/98.5 (Image/Pixel-level AUCROC)를 달성하여 거의 saturation 한 상태로 보여집니다. 또한 다른 모델에 비해 lightweight model를 제안함으로써, 2~10배의 inference speed를 보여 실용적인 측면에서 매우 뛰어난 성능을 보여줍니다.
++ 해당 논문은 11월 6일에 arxive에 등록된 논문입니다… 읽다보니 loss와 구현 방법에 대한 정보가 부분 부족한 상태였습니다. 처음에는 제가 잘못 읽어서 그런거라고 생각하고 여러번 다시 읽어봤으나, 없는 걸로 보아 아직 완성된 논문이 아닌 걸로 보입니다… 이는 추후 논문이 완성된다면 꼭 업데이트 하도록 하겠습니다.
+++ 22.3.15 update. 이전 연구(differNet, cflow-ad)에서 subnet을 conv로 변경한 것 외엔 달라진 점이 없어 설명이 적은 것으로 판단됨. 논문을 이해하려면 이전 연구 + 생성 모델 기반 Flow(RealNVP, GLOW…)를 봐야 이해 가능함.
+++ 22.3.15 update. 논문대로 구현하고자 모델을 작성했으나, Pixel-level AUROC는 원복이 안됨. 추가적인 연산이 있었을거라고 판단됨.
Intro
이상 검출은 큰 분류로 Recontruction method와 Representation method 두 가지로 크게 나눠집니다. Recontruction method는 GAN이나 Auto-encoder와 같은 생성 모델을 통해 정상적인 데이터로 영상을 복원시키고, 입력 영상간의 차이로 이상을 검출하는 방법에 해당합니다. 하지만 이는 학습 데이터에 포함되지 않는 형상을 가진 데이터에서는 정상적인 형태를 제대로 생성하지 못해 저조한 성능을 보이는 한계가 존재합니다. Representation method는 feature extractor로부터 차별성을 가진 feature를 임베딩하여 정상 케이스와 비정상 케이스에 대한 차이를 극대화하는 방법을 사용합니다. 좀 더 구체적으로 설명하자면, 정상 케이스에 대한 특징을 추출하고 이에 대한 특징 공간(정상 케이스에 대한 특징 정보들의 분포) 미세하게 만드는 것을 학습 목표로 합니다. 가우시안 분포로 근사화하여 정상 케이스에 대한 분산과 평균값을 추정하거나, kNN을 이용하여 정상 케이스에 대한 memory bank를 이용하는 방법이 있습니다. 근래의 비지도 학습 기반의 이상 검출 연구들은 정상과 비정상에 대한 정보가 필요한 recontruction method 한계로 인해 대부분 representation method를 이용한 연구가 주를 이루고 있습니다. 해당 방법 또한 representation method를 이용하여 이상 검출을 수행합니다.
앞서 설명한 바와 같이 대부분의 비지도 학습 기반의 이상 검출은 representation method를 이용합니다. 위와 같은 방법론은 distribution estimation module, feature extraction module 두 가지 요소로 구성됩니다. Feature extraction module은 우리가 흔하게 아는 CNN을 이용하는 방법에 해당합니다. 딥러닝을 이용한 최근 연구에서는 흔하게 CNN을 이용하여 feature를 추출하여 사용하며, 최근 연구에서는 ViT를 이용한 방법들이 등장하기 시작했습니다. 해당 연구에서는 plug-in-module 형태로 모델을 제안하여, 어떤 CNN과 ViT 상관 없이 구성할 수 있도록 하여 실용성을 강화하였습니다.
Distribution estimation module은 대부분 가우시안 분포로 근사하여 데이터의 분산과 평균과로 추정하는 방법 혹은 정상 케이스의 데이터로부터 kNN을 이용한 클러스터링에 의해 생성된 특징 정보를 이용하는 방법을 이용하였습니다. 최근에 몇몇 연구 중 normalizing flow를 이용하여 정상 케이스에 대한 분포를 추정하기 시작했습니다. 해당 연구에서는 normalizing flow를 기반으로 구성된 module를 제안합니다.
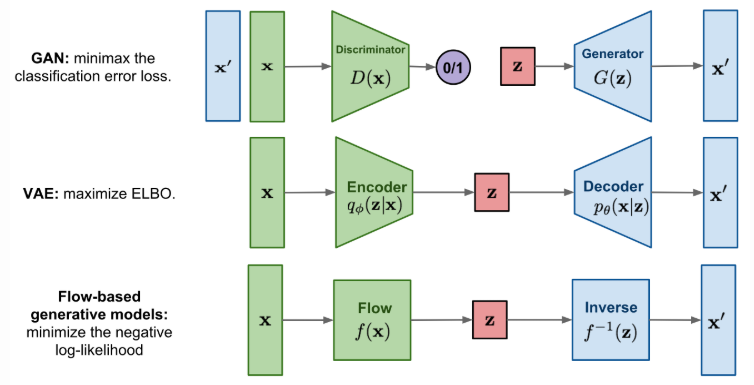
++ 해당 논문을 이해하기 위해서는 normalizing flow에 대한 이해가 필요합니다. normalizing flow는 복잡한 분포를 가진 정보들을 근사하기 위한 방법으로 제안된 방법입니다. 즉, 생성 모델로써 제안된 방법에 해당합니다. 우리가 흔하게 아는 생성 모델로 GAN과 VAE가 있습니다. GAN은 생성자와 구별자로 구성되며, 생성자는 구별자를 잘 속일 수 있도록 학습이 되며, 구별자는 원본 데이터와 생성 데이터를 잘 구별하도록 학습이 됩니다. 즉, 구별자의 분류 능력을 통해 학습이 됩니다. VAE는 데이터를 latent feature로 압축하는 encoder와 복원하는 decoder로 구성됩니다. 간단한 구조로 구성된 VAE는 라벨이 필요없이 학습을 한다는 특징이 있습니다. 라벨 대신 데이터로부터 분산과 평균 값을 추정하여 이를 원본 데이터와 근사하도록 학습(ELBO를 이용)을 진행함으로써, latent feature의 feature space를 점점 표현력이 강해지는 방향으로 근사화하는 방법을 이용합니다. 이에 반해 normalizing flow는 보다 직관적인 방법을 이용합니다. 가역성을 가진 함수를 이용하여 가능도가 극대화되도록 학습이 진행하고, 가역성을 가진 함수이기에 이에 대한 역함수를 이용하여 latent feature(함수로부터 추정된 정보)를 원본 데이터로 잘 복원할 수 있다는 가정을 이용합니다.
Method
++ 아직 미완성 논문으로 이후 꼭 업데이트 하도록 하겠습니다.
비지도 학습 기반의 이상 검출은 대부분 one-classification 혹은 out-of-distribution detection으로 정의됩니다. 이러한 방법론들의 학습 단계에서는 오직 학습 데이터만을 이용하여 학습이 진행되며 feature extraction을 이용하여 구분력 강한 feature vector를 임베딩하여 사용하여 정상 데이터에 대한 분포를 구성합니다. 평가 단계에서는 입력된 특징 정보와 분포 간의 거리 정보를 이용하여 anomaly score로 사용합니다. 제안된 방법론은 전반적으로 앞서 설명한 방법과 동일한 단계를 수행합니다. 또한 제안된 방법론에서는 특정 backborn network(feature extractor)으로부터 high-dimensional visual feature를 standard normal distribution으로 투영하기 위해서 FastFlow module을 이용합니다.
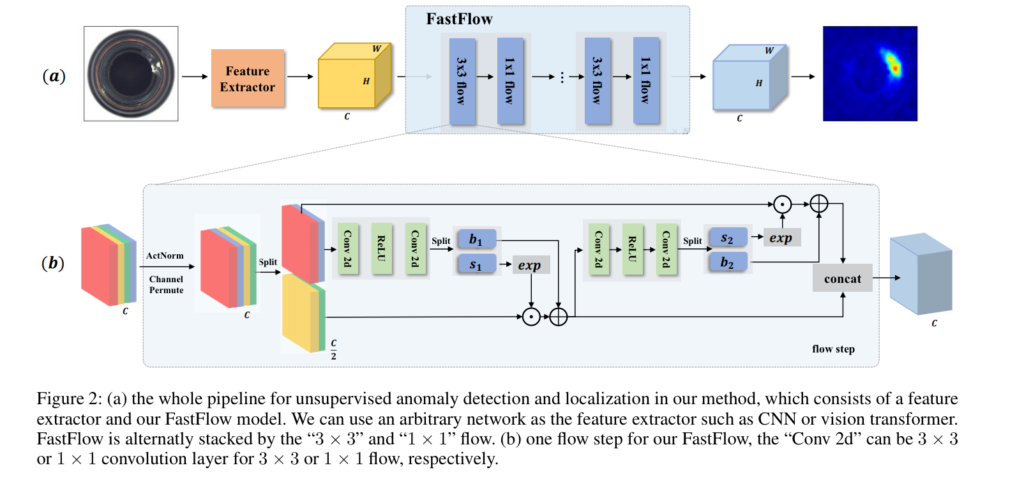
Feature Extractor. 해당 방법론에서는 먼저 ResNet과 ViT를 이용하여 특징을 추출합니다. 두 방법론은 영상으로부터 특징을 추출하는 탁월한 방법으로 알려져 있습니다. ResNet은 마지막 층에서의 1~3 block을 이용하였으며, ViT는 전체 영역과 지역 영역에 대한 관계 능력이 뛰어나기 때문에 특정 하나의 layer로부터 추정된 정보만 사용하여 FastFlow model에 전달합니다.
FastFlow model. 해당 모듈에서는 flow를 컨셉을 이용하여 구현한 Glow(Dinh, et.al 2014) 기반으로 구성됩니다. 먼저 입력된 특징을 ActNorm을 통해 특징 수준에서 affine 변환을 수행합니다. 그후 Affine coupling layer를 수행합니다. Affine couling layer의 수식은 아래와 같습니다.(가역 함수들은 행렬식이 0이 되면 안된다는 조건이 있습니다. 이러한 제한 조건을 맞추기 위해서 Glow엣는 Jacobian matrix 쉽게 계산하기 위한 아래의 수식 구조의 레이어를 이용합니다. 자세한 내용이 궁금하신 분들은 해당 링크를 참고하시기 바랍니다.)
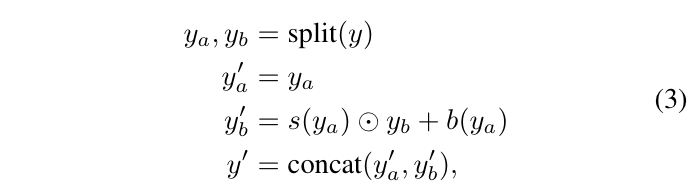
수식 3에서 s(), b()는 subnet으로 fig 2와 같이 Conv-ReLU-Conv로 구성됩니다. 수식 3에서 3번째 수식을 보면 입력 feature y로 부터 split된 y_a, y_b 중 y_b를 y_a에 따라 affine을 수행하는 모습을 볼 수 있습니다. 이를 통해 특징 정보를 변형시키고, fig 2에서 볼 수 있듯이 반대로 y_a를 y_b에 따라 affine을 수행합니다. 기존의 방식들은 한 방향의 차원만을 이동시켰다면, 해당 방법론에서는 두 방향의 차원 모두 affine을 수행함으로써, 보다 강인한 변환을 꾀합니다. 해당 모듈은 여러개의 블록으로 구성됩니다.
손실함수에 대한 정확한 정보는 없지만, flow 기반의 딥러닝을 조사해본 결과. 대부분 NLL loss를 이용하는 것으로 보아 해당 논문도 동일한 손실함수를 사용했을 것으로 추정됩니다.
+ 현재 그림과 설명이 매칭이 안된 형태로 작성되어져 있으며, 손실함수에 대한 설명이 없습니다. 이후 완성된 논문이 업데이트 된다면, 리뷰를 업데이트 하도록 하겠습니다.
++ 해당 방법론은 특징 공간을 standard distribution으로 옮기는 것을 주 목적으로 설계된 것으로 보입니다. 모든 설계가 학습 가능한 파라미터로 구성된 affine 변환으로 구성하여 정상 정보에 대해 학습시, 정상 데이터에 대한 space를 standard distribution로 변화하도록 학습됩니다. 이후 투영된 정보가 원점가 멀어질 수 록 비정상 데이터로 판별하는 방법을 사용하는 것으로 보입니다.
Experiment
실험에는 MvTec과 CIFAR-10, BTAD에서 평가가 이뤄졌습니다. MVTec은 이전에서 설명한 바와 같이 산업 환경에서의 이상 검출 데이터 셋이며, 이미지 레벨과 픽셀 레벨에서의 이상 검출을 수행합니다. BTAD 또한 산업 환경에서의 이상 검출 데이터 셋이며, 2,540 장의 영상으로 구성되어져 있습니다. 픽셀 레벨 이상 검출에 특화된 데이터 셋입니다. CIFAR-10은 out-of-distiribution detection task에서 흔히 사용됩니다. 다른 클래스가 입력될 경우를 이상으로 구분하며, One vs Other 형태로 테스트가 구성됩니다.
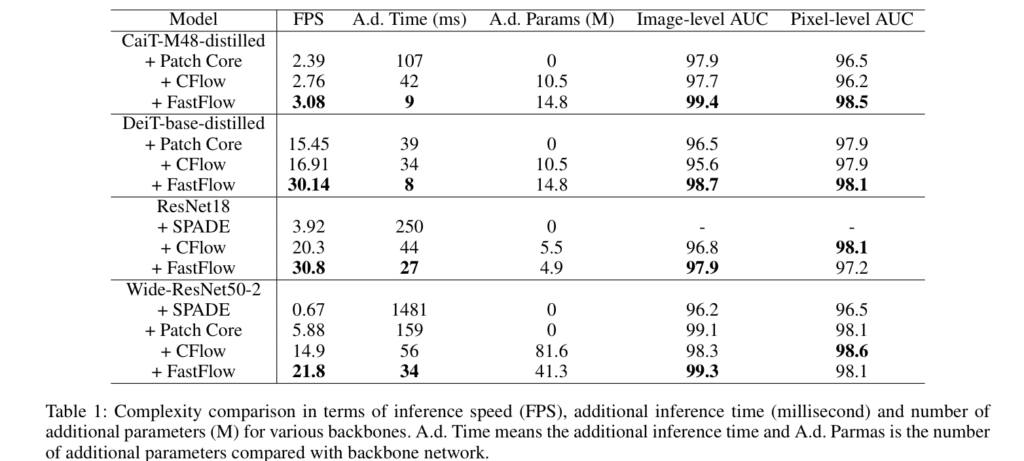
먼저 table 1은 MVTec에서의 실험 결과 입니다. ResNet과 ViT 부류의 방법론을 특징 추출기로써 사용하여 SOTA 방법론과 비교 실험을 진행하였으며, 이전 SOTA 방법론보다 빠른 추론(FPS), 적은 파라미터(A.d Params)를 보여줌으로써 실용적인 방법론임을 입증합니다. 또한 Image/Pixel-level AUC에서 다양한 백본에서 좋은 성능을 보여줍니다. +Patch Core, SPADE는 특징 추출기 이후부터는 딥러닝이 아닌 기계학습 방법론을 이용하여 A.d Params에서는 0을 보여줍니다.
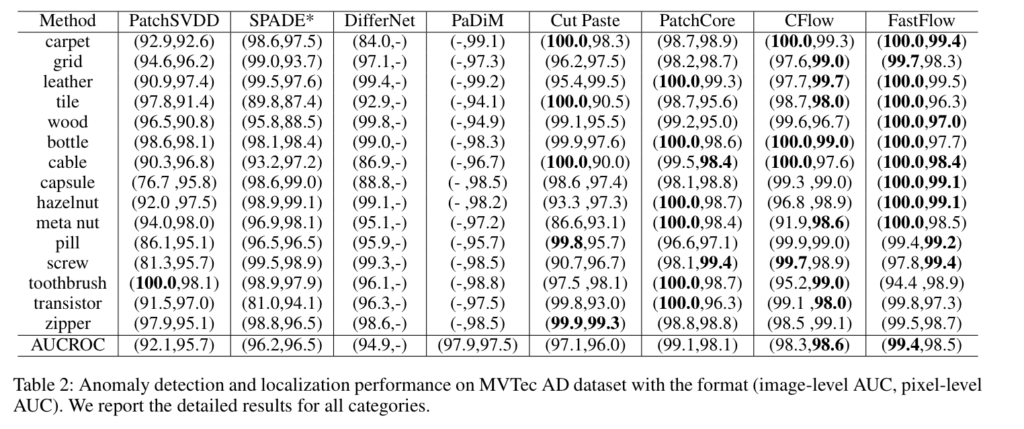
Table 2에서는 MvTec 데이터 셋에서의 Pixel-level AUC에 대한 부류별 성능입니다. 이전 방법론보다 좋은 성능을 보여줍니다.
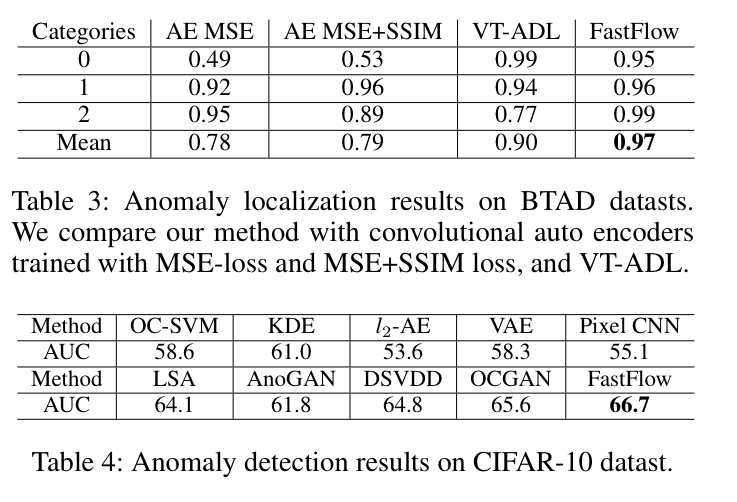
Table 3(BTAD), Table 4(CIFAR-10)에서도 우수한 성능을 보여줍니다.
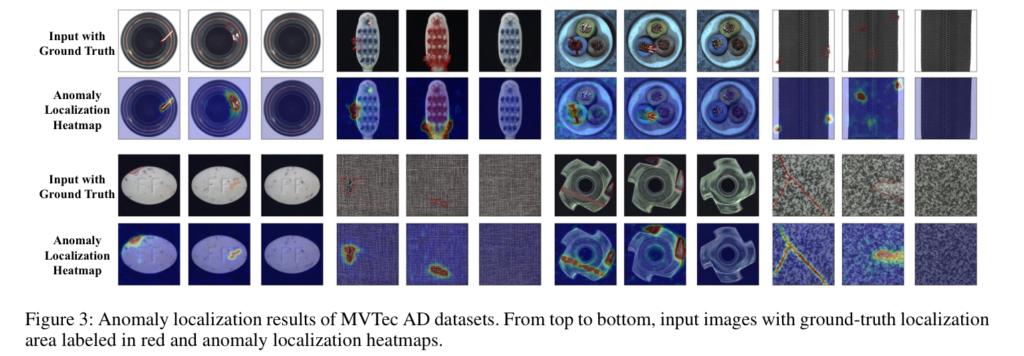
Fig 3에서 정성적인 결과를 확인 할 수 있습니다.
===============================================================
이번 논문은 Paper with code에서 기준 #1을 달성하여 읽게 되었습니다. 아직 미완성된 논문으로 명확한 방법에 대해서는 알 수 없지만, 해당 논문의 관련 연구 섹션을 통해 현재 이상 검출의 흐름이 flow를 이용한 방법론이라는 것을 알 수 있었습니다. Flow의 특성상, 정상 분포를 표현하는데에 적합한 방법론이며, 이후 이상 검출 방법론은 flow로 구성될 가능성이 높아 보입니다. 추후 flow에 대해 보다 깊이 공부하여 적용하는 것도 좋을 것으로 판단됩니다.