Active Learning 에 대하여 많이 듣곤 하였으나, 저는 전혀 아는 것이 없는 연구여서 이번 기회에 한 번 공부도 할 겸 논문을 읽어보게 되었습니다.
본격적인 리뷰에 들어가기 앞서, 저처럼 Active Learning 을 처음 접하는 분들도 이해하기 쉽도록 여러 글을 참고하여 알아두면 좋을 내용에 대하여 소개하도록 하겠습니다.
[참고] Active Learning Literature Survey
딥러닝 기반의 연구가 여러 분야에서 뚜렷한 성과를 나타내고 있지만, 이를 위해서는 충분한 양의 “라벨링된 데이터”가 필요합니다. 그러나 “라벨링” 이라는 작업은 많은 비용이 들어가기에, 어떻게 해야 이 노동과 비용을 줄일 수 있는지에 대한 고민에서부터 이 연구가 시작되었습니다.
다시말해, 같은 수의 데이터에 라벨링을 하더라도, 어떻게해야 더 좋은 성능을 내는 데이터를 골라 라벨링할 수 있을지가 바로 Active Learning이 주로 다루고자 하는 문제입니다.
what is the optimal way to choose data points to label such that the highest accuracy can be obtained given a fixed labeling budget?
리뷰할 논문의 Introduction 중 일부
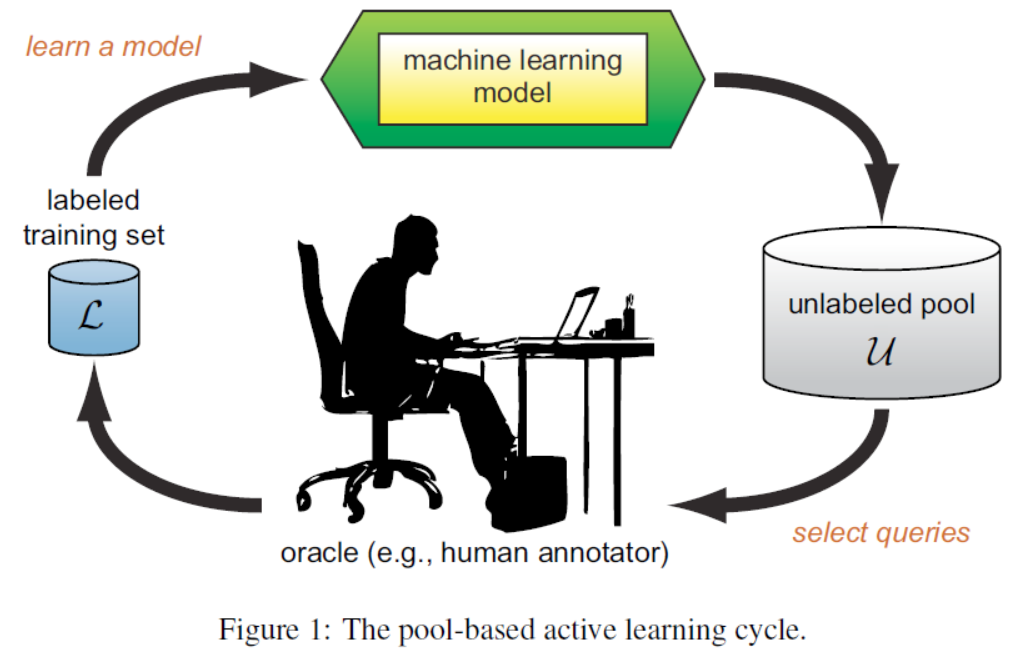
Active Learning 은 아래 과정을 목표한 성능이 나올 때까지 반복합니다.
- 초기 학습 데이터를 이용하여 모델 학습
- Unlabeled Pool에 있는 데이터 중 *모델에게 도움이 되는 데이터 선별
- 선별한 데이터를 사람(oracle, human annotator)이 Labeling
- Labeling을 마친 데이터를 기존 학습데이터와 합쳐 다시 모델 학습
^{*} 모델에게 도움이 되는 데이터는 대개 모델이 판단하기 어려워하는 데이터
그렇다면 일반적인 지도학습과 Active Learning은 어떤 차이가 있을까요? 이를 A, B 학생의 공부법으로 비유하여 예를 들어 보겠습니다. A, B 학생이 100문제씩 포함된 서로 다른 문제집 10권을 가지고 있습니다. 500문제를 풀고 나서 실력을 비교한다고 했을 때 각 학생의 공부법은 다음과 같습니다.
- A: 문제집 5권을 임의로 골라 다 풀기
- B: 문제집 3권을 임의로 골라 다 풀고, 자주 틀린 유형을 골라 남은 7권의 문제집에서 이와 비슷한 유형에 대해 200문제 풀기
일반적으로 풀 수 있는 문제 수가 정해져있을 때 자주 틀리는 유형에 대비한 B 학생에 대해 더 효율적으로 공부했다고 할 수 있습니다. 눈치 채셨겠지만, A 학생의 공부법을 지도학습 / B 학생의 공부법을 Active Learning에 비유한 예시였습니다. 풀 수 있는 문제 수가 제한된 상황 같이, 레이블링할 수 있는 수가 제한된 상황에서는 성능 향상에 효과적인 데이터 선별하는 것이 매우 중요해집니다.
그렇다면 지금부터는 기존 Active Learning 연구에는 어떤 방법론들이 있는지 가볍게 살펴보겠습니다. 앞서 설명한 “모델에게 도움이 되는 데이터를 선별하는 방법”을 “Query Strategy” 이라고 합니다. 성능 향상에 효과적인 인스턴스를 쿼리하는 방법을 의미하는데 대표적인 방법론들에 대해 간단히 설명하겠습니다. (예전에 사용되던 방법이기 때문에 수식은 최대한 제외하며 깊이 다루지는 않았습니다.)
- Uncertainty Sampling
학습된 모델의 output을 기준으로 불확실한(확실하지 않은) 데이터를 먼저 쿼리하는 방법입니다. 여기서 불확실성을 정의하는데에는 크게 세 가지 지표가 있습니다: Least Confidence(LC) / Margin Sampling / Entropy Sampling.
각각의 방법을 아래 테이블을 통해 알아보도록 하겠습니다.
| Data | Class 1 | Class 2 | Class 3 |
|---|---|---|---|
| x_1 | 0.1 | 0.2 | 0.7 |
| x_2 | 0.34 | 0.37 | 0.29 |
| x_3 | 0.41 | 0.39 | 0.2 |
| x_4 | 0.3 | 0.4 | 0.3 |
- Least Confidence (LC)
argmin(P(y_1|x))
Least Confidence 는 Confidence가 가장 낮은 것 Uncertainty의 기준으로 설정하는 방법입니다. 쉽게 말해 모델이 예측한 각 클래스의 확률 중 Top 1 확률이 가장 낮은 데이터부터 쿼리하는 방법입니다.
Confidence 가 작다는 것은 그만큼 해당 클래스일 가능성(확실성)이 낮다는 것이기에, 모델이 어려워한다고 가정하고 쿼리하게 됩니다. 위 테이블 1의 예시를 정리하면 Top 1과 이에 따른 쿼리할 순서는 아래 그래프와 같습니다.
| Data | Top 1 | Priority |
|---|---|---|
| x_1 | 0.7 | 4 |
| x_2 | 0.37 | 1 |
| x_3 | 0.41 | 3 |
| x_4 | 0.4 | 2 |
- Margin Sampling
argmin(P(y_1|x)-P(y_2|x))
Confidence 차이가 가장 적은 것을 Uncertainty의 기준으로 설정하는 방법입니다. 쉽게 말해 모델이 예측한 각 클래스의 확률 중 Top 1 과 Top 2의 확률 차이가 가장 낮은 데이터부터 쿼리하는 방법입니다.
위 테이블 1의 예시를 정리하면 Top 1 – Top 2 와 이에 따른 쿼리할 순서는 아래 그래프와 같습니다.
| Data | Top 1 – Top 2 | Priority |
|---|---|---|
| x_1 | 0.5 | 4 |
| x_2 | 0.05 | 2 |
| x_3 | 0.03 | 1 |
| x_4 | 0.1 | 3 |
- Entropy Sampling
모델이 예측한 각 클래스에 속할 확률을 활용하여 엔트로피가 가장 큰 데이터부터 쿼리하는 방법입니다. Entropy자체가 불확실성을 나타내는 수치기 때문에 이를 Uncertainty 기준으로 설정하며, 엔트로피를 계산하기 위한 수식은 아래와 같습니다.
H(X) = -\sum_{i=1}^nP(x_i)logP(x_i)또한 테이블 1의 예시를 정리하면 Entropy 와 이에 따른 쿼리할 순서는 아래 그래프와 같습니다.
| Data | Entropy | Priority |
|---|---|---|
| x_1 | 0.8018 | 4 |
| x_2 | 1.0937 | 1 |
| x_3 | 1.0547 | 3 |
| x_4 | 1.0889 | 2 |
Uncertainty Sampling은 위에서 보는 것과 같이 불확실성 정의에 따라 순서가 바뀌기도 합니다. 이 방법은 가장 직관적이고 단순한데다 성능도 나쁘지 않아 보편적으로 사용되는 방법입니다.
2. Query-by Committee (QBC)
여러개의 모델을 동시에 학습시켜 많은 모델이 틀리는 데이터를 쿼리하는 방법입니다. 앙상블 모델을 생각하면 이해하기 쉬울 것 같습니다.
3. Expected Model Change
현재 모델에 가장 크게 변화시키는 데이터를 쿼리하는 방법입니다. 예를 들어 어떤 데이터가 들어갔을 때 Gradient가 가장 크게 변화하는 데이터를 쿼리하는 방식을 의미합니다.
4. Expected Error Reduction
라벨링 후 데이터가 학습데이터로 추가될 때(인스턴스가 추가되었을 때), 일반화 에러(generalization error)를 최소화 시키는 데이터를 쿼리하는 방식입니다. 즉, 학습데이터와 라벨링되지 않은 데이터에 대해 모델 학습 시 예상되는 에러를 추정하여, 이 에러를 최소화시키는 방법입니다. 그러나 이 방법은 Computation Cost 가 높아 이진 분류 이상의 태스크 수행에는 Practical 하지 않다고 알려져 있습니다.
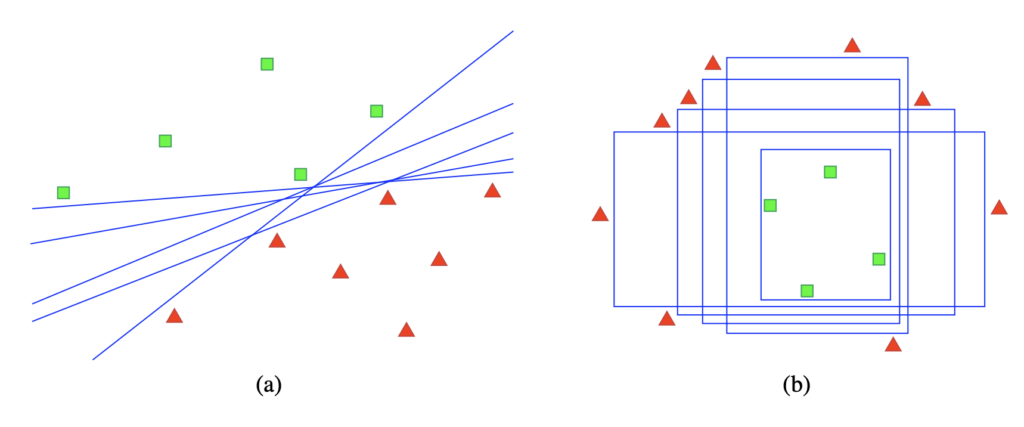
5. Density Weighted Method

각각의 인스턴스가 아닌 전체 공간을 고려하도록, 데이터가 밀집된 지역의 데이터를 쿼리하는 방법입니다.
위에 첨부한 그림에서 보통 우리는 결정 경계에 있는 데이터를 판별하기 어렵다 판단하기 때문에 보통 A의 Uncertainty가 가장 높다고 생각합니다. 이 방법의 메인 아이디어는 정보량이 많은 인스턴스는 모델에게 불확실하다는 것이기 때문에, A 가 아닌 B에 불확실성을 더 높게 부여해야합니다. 따라서 Density에 대한 Weighted를 줌으로써 주변에 샘플 많지 않은 A보다 B의 Uncertainty가 더 높다고 판단되는 방식을 바로 Density Weighted Method라고 합니다.
지금까지 active learning을 이해하기 위한 배경 지식에 대하여 알아보았으니.. 이제부터는 본격적인 논문 리뷰를 시작하겠습니다.
Active learning for convolutional neural networks: A core-set approach – [Link]

Introduction
Annotation 에 필요한 시간, 노동, 비용이 많이 들기에 Active Learning 은 여느때와 같이 중요해지고 있지만, 기존 Active Learning 에 사용되던 Heuristics 한 방법론들은 CNN에 적합하지 않다고 합니다. 왜냐하면, 앞서 알아본 기존 방법들은 대부분 Instance 단위로 데이터를 쿼리하는데, 배치 단위로 학습하는 CNN 에 이 방법을 사용하는 것(하나씩 쿼리하는 것)은 비효율적이기 때문입니다.
따라서 본 논문에서는 Active Learning을 Label 정보가 필요한 Uncertainty 대신 CNN의 Feature 를 사용하여, Unlabeled 데이터 전체를 대표할 수 있는 Core-set Selection 문제로 새로 정의합니다. 여기서 이 Core-set만을 사용하여 모델을 학습시킨 성능이, 전체데이터를 사용한 성능과 거의 비슷할 정도로 전체 데이터를 대표하는 데이터를 Core-set 이라고 합니다.
Problem Definition
본 논문에서는 줄곧 Active Learning 을 Core-Set Selection 문제로 재정의하여 접근하였다고 합니다.
따라서 Active Learning 문제는 Subset에서의 모델 성능과 전체 데이터셋에서의 성능 차이를 최소화하는 문제로 재정의됩니다.
아래 그림이 바로 본 논문을 대표하는 그림입니다.
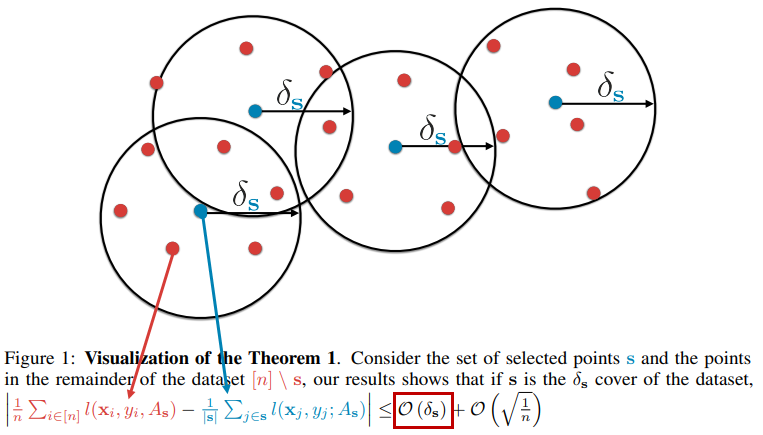
Core-set을 찾기 위해서는, 위 그림에서 빨간색의 데이터 샘플은 모두 Cover 할 최적의 거리 \delta{s}를 구하고, 그에 해당하는 Core-point인 파란 데이터 샘플을 찾아야합니다. 따라서 이 \delta{s}를 최소화하는 방법에 대해 문제로 전환되게 됩니다.
논문의 내용이 너무 어려워 Active Learning 이 무엇인지에서부터 시작하다보니 내용이 길어졌습니다. 지금까지 작성한 내용 중 부족한 부분을 보완하고, 잘못된 내용이 있다면 정정하여 PART 2. 에서는 본격적인 본 논문에 대한 리뷰를 작성해보고자 합니다. 감사합니다.
예전부터 불확실성에 대해 관심이 많아 언제 한번 정리해야겠다 했는데 먼저 다뤄주셔서 많은 도움이 될 것 같습니다.
근데 방법론 마다 Uncertainty 우선 순위가 다른 걸 보니 각 방법론마다 장단점이 있을 것 같습니다.
어떤 경우에 어떤 방법론을 사용해야 할지도 같이 정리 해두시면 좋을 것 같습니다.
네 좋은 답변 감사합니다. 안그래도 저도 리뷰를 다시 읽어보며, 그 점이 부족하다고 느껴서 Part 2 작성 시 함께 작성해보려고 합니다. 좋은 말씀 감사합니다~!
안녕하세요 홍주영 연구원님, 좋은 리뷰 감사합니다.
active learning이 뭔지 몰라서 찾아보려고 하고 있었는데, 마침 잘 설명되어있는 리뷰가 눈에 띄어 읽게 됐습니다.
제가 이해한 바로는 다음과 같습니다.
1. active learning은 기계 학습에 필요한 데이터를 라벨링하는 비용이 비싸니 효율적인 라벨링을 위해 전체 데이터셋에서 학습에 유리한 데이터를 정제하는 과정이다.
2. batch 단위로 학습하는 CNN 특성 상 기존 active learning에 사용되던 휴리스탁한 방법은 적절하지 못하다(기존 방법들은 대부분 instance 단위로 데이터를 쿼리하기 때문).
3. 본 논문에서는 uncertainty가 아닌 CNN feature를 사용한다. unlabeled 데이터 전체를 대표할 수 있는 core-set selection 문제로 재정의해서 접근한다. core-set은 1.core-point data sample과, 2.그 주위를 cover 할 거리인 δs를 찾아서 구할 수 있다.
제가 해당 리뷰를 제대로 이해한 것인지 궁금합니다.
리뷰를 읽다보니 제가 아직 관련 지식이 얕아 이해하기 힘든 부분이 있었습니다.
1. 데이터는 어떤 공간에 분포하게 되며 그 위치는 feature에 의해 결정되는 것으로 보입니다. 근데 데이터가 분포되는 공간과 데이터 간 거리(δs를 구해야 하므로)가 어떻게 정의되는지 궁금합니다. 이에 관한 간단한 설명이나 구글링을 위한 관련 keyword를 알려주신다면 부족한 부분을 메꾸는데 큰 도움이 될 것 같습니다.
2. CNN 학습에 앞서 active learning으로 학습 데이터를 선별하는 모델이 있는 것으로 보입니다. 일반적으로 active learning을 이용해 image classification/regression을 수행할 때, 한 모델에서 통합되는지(data batch 선별 + CNN), 아니면 active learning을 수행하는 모델과 CNN모델을 분리해서 사용하는지 궁금합니다.
질문에 대한 답변 남겨주신다면 감사하겠습니다.
허허 해당 논문을 읽은지 꽤 된지라, 명쾌한 답변이 될지 모르겠으나 다시 정리해보겠습니다.
우선 Coreset이라는 AL 방법론은 현재까지도 Benchmark로 다뤄지고 있을 정도로 근본 방법론이라고 할 수 있습니다. Image Domain에 Active Learning 을 적용하였다는 점, 모델 선별에 CNN을 사용하였다는 점, 그리고 Batch 단위로 데이터셋을 선별하여 Annotation을 요청하였다는 Contribution이 있습니다.
그렇다면 Active Learning 은 어떻게 학습이 진행될까요?
1) Train(Labeled): 랜덤하게 뽑은 Labeled dataset으로 모델을 학습
2) Selection: 학습한 모델의 출력값에 대해 저자가 설정한 선별 기준(sampling method)에 따라 라벨링할 데이터를 선별합니다. 이번 리뷰 내용 중 Uncertainty Sampling (LC, Margin sampling 등등) 이 바로 sampling method 입니다.
3) Query: 선별한 데이터를 Oracle(어노테이터, 라벨러) 에게 라벨링하라고 요청합니다.
4) Add and Re-train: 라벨링이 완료된 데이터는 기존 Labeled dataset에 추가합니다. 그 다음 다시 모델을 학습합니다.
2)-4) 를 목표치에 도달할 때까지 반복합니다.
이렇게 점차 데이터셋을 추가하면서, 방법론의 성능을 평가(가령 정확도)합니다.
이제 질문에 대해 답변드리려고 하는데요.
1. Feature space..? 정도라고 할 수 있을까요? Model의 출력값은 보통 (h, w, c) 차원으로 구성되어 있는데, 이 공간에서의 거리를 측정하여 데이터를 선별하는 것이 바로 Core-set 방법론입니다. 즉, 이미지를 어떤 차원의 feature로 만들어야 데이터셋을 잘 선별할 수 있을까? 에 대해 고민한 방법론이라고 할 수 있죠. CNN은 여기서 image들을 어떤 feature space로 만들지를 계산해내는 역할입니다.
2. 둘 다 맞습니다. 보통 Task model은 Classification/regression을 수행하는 모델이라고 합니다. 이 Task model의 출력값에 대해 Sampling method를 적용하는 경우가 있구요. 이거 말고 Scoring Network를 추가하여 데이터셋의 가치(성능을 얼마나 올릴 수 있을지)를 평가하는 모델이 별도로 있는 경우도 있습니다. 아주 다양하게 연구되고 있습니다.