이번 리뷰는 이상 검출 논문을 서베이하던 중 흥미로운 연구 내용을 발견하여 리뷰하게 되었습니다. 이상 검출은 의학, 산업 환경 등, 단일 물체에 집중된 연구들이 주로 이루지만, 이번 연구는 도로 주행 상에서 발생하는 이상 검출에 집중합니다. 가장 흥미로운 점은 이상 검출 과정에 있습니다. 도로 영상으로부터 명확한 도로 정보로 구성된 데이터 셋으로부터 학습된 sematice segmetation model이 이상치에 대해 제대로 구현하지 못하는 점을 이용하여 영상을 재구성하고 이에 대한 차영상 정보와 불확실성(이상치)에 대한 엔트로피를 이용하여 이상치를 검출하는 방법을 이용합니다.
Intro
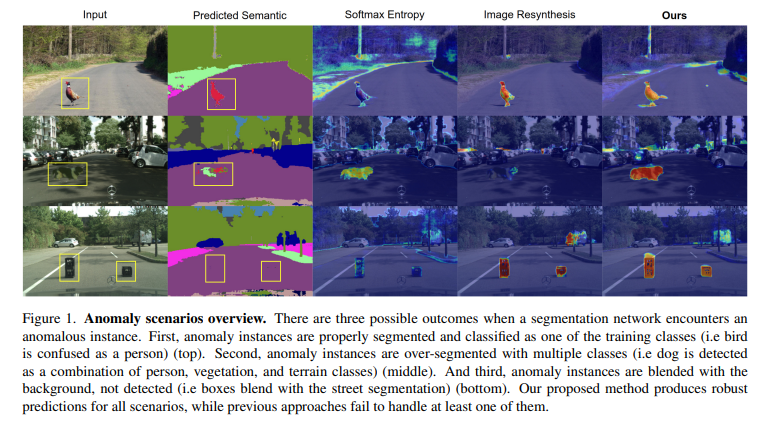
자율주행에 있어 Sematic segmentation은 환경에 인지함에 있어 매우 중요한 태스크입니다. 하지만 이상치에 대해서는 검출을 실패하는 경우가 많습니다. 모델 관점에서 라벨이 없는 데이터가 보이는 경우에는 Fig 1의 2행과 같은 형태로 이상치를 처리합니다. 해당하지 않는 라벨로 검출(1열)하거나 다양한 라벨이 결합된 형태로 검출(2열)하거나 아예 검출을 하지 못하는 형태(3열)로 예측하는 문제가 발생합니다. 이러한 경우, 실제 환경에서 빈번히 발생할 수 있는 상황으로 반드시 해결되어야 하는 요소 중 하나입니다.
이러한 문제를 해결하기 위해서 크게 2 그룹으로 연구가 진행되어져 왔습니다. 먼저 첫번째는 Fig 1의 3행과 같이 모델의 불확실성(~엔트로피)을 이용하여 검출하는 방법이 있습니다. 하지만 이는 3행 1,3열과 같이 한 쪽 라벨에 명확한 신뢰도를 가지는 경우 이상 검출에 실패하는 문제가 있습니다. 남은 그룹으로는 이상이 존재하는 영상으로부터 정상적인 영상으로 재생성하여 이상을 검출하는 방법(Fig 1 4행)입니다. 해당 그룹의 최신 연구는 생성된 의미론적 영상으로부터 영상을 생성하는 방법을 이용합니다. 이는 불확실성을 오히려 역으로 이용함으로써, 명확한 신뢰도를 보이는 경우에 강인한 모습을 보여주지만 2열과 같이 모호하게 노이즈 라벨이 존재하는 경우에도 영상을 생성하여 이상 검출에 실패하는 경우를 보여줍니다.
저자는 두 그룹의 상호적인 특성을 두 그룹의 최신 방법론을 결합하여 보완함으로써 문제 해결을 제안합니다.
Method
Pixel-wise Anomaly Detection Framework
저자가 제안하는 네트워크는 영상으로부터 추론된 Sematic map으로부터 영상을 생성하여 차영상을 이용하는 방법론을 기반으로 합니다. 그러나 불확실성에 대한 정보에 강인성을 주기위해 Fig 2와 같이 불확실성 정보를 앙상블함으로써, 개선된 성능을 보여줍니다.
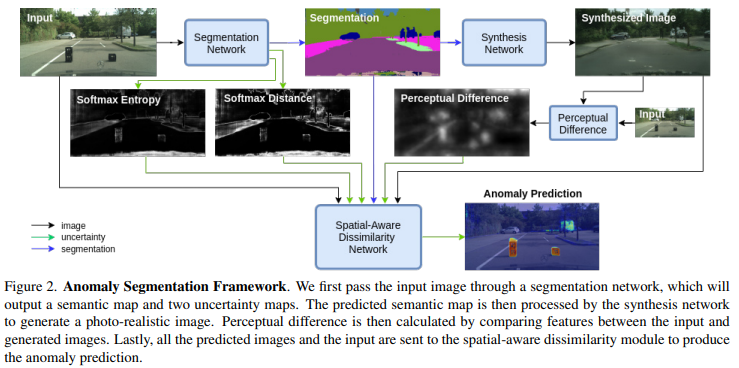
Segmentation Module. 먼저 해당 모듈을 이용하여 segmentation model로부터 sematic map을 획득합니다. sematic map 외에도 모델의 불확실성을 정량화하기 위해서 두 가지 분산 측정을 계산합니다. 이 두 가지 분산 측정은 SoftMax Entropy H와 softmax 거리 D(두 개의 가장 큰 softmax 간 차이)이며, 이는 segmentation의 오류를 이해하는데에 큰 도움이 되는 것이 [1]으로부터 증명이 되었습니다. 이를 계산하는 수식은 아래와 같습니다.
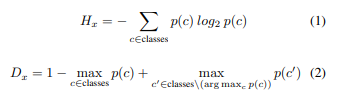
위의 수식에서 class c에서의 p(c)는 softmax의 확률 값에 해당하며, 확률 값들은 [0, 1] 사이로 정규화되어 사용됩니다.
++ 이해를 돕기 위해 수식에 대해 추가적으로 설명을 하겠습니다. 수식 1은 모든 클래스에서의 엔트로피 또는 불확실성을 구합니다. 이를 통해 명확하지 않은 예측 값들에 대한 정량화가 가능해집니다. 수식 2에서는 가장 확률이 높은 클래스의 확률 값과 두번째로 큰 클래스에서의 확률 값 간 차이(거리)를 이용합니다. 즉, 모호성에 대해 수치화 가능해집니다.
+++ 위의 수식은 이번주 홍주영 연구원님이 작성한 [ICLR 2018] Active learning for convolutional neural networks: A core-set approach – (Part 1)에서도 다루고 있으니 참고하시기 바랍니다.
Synthesis Module. 해당 모듈에서는 픽셀 대 픽셀 대응으로 주어진 sematic map으로부터 Synthesized image를 생성합니다. semantic map과 입력 영상 정보 간 생성 분포를 맞추기 위해서 조건부 생성 적대 네트워크(cGAN)을 이용합니다. cGAN은 실제와 유사한 자동차와 건물 보행자를 생성할 수 있지만, 색감이나 디테일한 모양 정보까지 완벽하게 생성하기 힘드기 때문에 이를 보완하기 위해서 원본 이미지와 Synthesized image 간의 지작적인 차이(Perceptual Difference) V를 계산하여 사용합니다. 해당 아이디어는 특징 추출기로써 ImageNet으로 사전 학습된 VGG를 이용하여 구현됩니다.
입력 영상의 모든 픽셀 x와 이에 대응되는 Synthesized image의 모든 픽셀 r 간의 지각적인 차이는 아래의 수식을 이용하여 계산되어집니다.
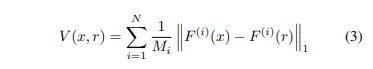
수식 3은 N 개의 레이어를 가진 VGG의 i 번재 레이어 F^{(i)}와 이를 구성하는 feature map Mi로 구성되며, 일관성을 위해 [0, 1]로 정규화되어집니다.
++ 즉, 원본 영상과 생성 영상의 색상, 질감 등 cGAN으로 원복하기 힘든 저수준의 특징을 특징 추출기인 VGG를 활용함으로써, 영상 내의 정보, 공간적인 정보를 고려한 고수준의 특징에서 비교한다는 이야기입니다.
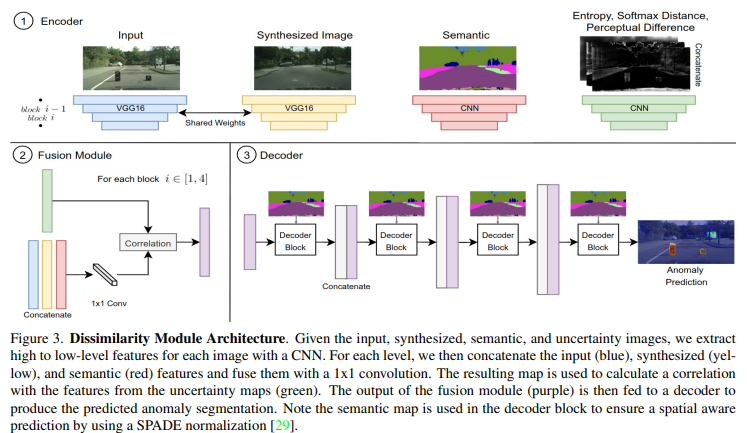
Dissimilarity Module. 해당 모듈에서는 원본 영상, 생성 영상과 sematic map, 위에서 계산된 불확실성 맵(Softmax Entropy, Softmax Distance, Perceptual Difference)을 입력으로 사용합니다. 또한 해당 모듈은 Fig 3과 같이 Encoder와 Fusion module, Decoder로 구성됩니다. 먼저 Encoder에서는 원본 영상과 생성 영상을 사전 학습된 VGG를 이용하여 인코딩합니다. 또한 불확실성 맵과 sematic map에 대한 정보를 임베딩하기 위해 간단한 구조를 가진 CNN을 이용합니다. Fusion Module에서는 Feature pyramid의 각 수준([1-4])에서의 원본, 생성 영상과 semaic map에 대해 concat 후, 1×1 conv를 통해 feature를 생성합니다. 그리고 concat 된 불확실성 맵의 특징 정보를 point-wise correlataion을 수행함으로써 특징맵에서 불확실성이 높은 영역에 주의를 기울이도록 안내합니다. 그런 다음 Decoder를 통해 각 특징 맵들을 디코딩하고 이상 분할 예측을 얻을 때까지 상위 레이어와 concat을 수행합니다. 또한 공간 정보에 대한 정규화를 위해 sematric map을 이용합니다.이를 통해 Decoding 과정에서 의미 정보를 놓치지 않도록 합니다.(이는 [*]에서 제안된 방법이라고합니다. 해당 정보는 논문을 읽고 x-review를 작성하도록 하겠습니다.)
[*] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2337–2346, 2019. 5, 8, 11
Experiments
실험에서는 Cityscapes로 학습된 SOTA인 Sementation model(PSP Net)을 사용했습니다. 생성 모듈 또한 동일한 데이터 셋에서 학습된 모델(CC-FPSE)을 사용하였습니다. 평가를 위해서 Fishyscapes benchmark를 이용했습니다. 해당 벤치마크는 평가 메트릭으로는 AP와 false positive rate(95%) FPR95를 이용하였습니다. 또한 해당 벤치마크에서 제안한 데이터 셋은 3가지로 나눠서 실험을 진행했으며, 이는 FS Lost & Found (L&F), FS Static, FS Web로 구성됩니다.
– FS Lost & Found (L&F) : 차량의 앞 쪽에 이상치를 두고 촬영된 데이터셋. 275장의 영상으로 구성
– FS Static : Cityscapes에 Pascal VOC의 물체들을 합성하여 생성한 데이터셋. 1,000장의 영상으로 구성
– FS Web : 도로 상 물체가 존재하는 영상을 웹 상에서 크롤링한 데이터 셋. + 총 몆 장인지는 Fishyscapes benchmark을 태그함. 추후 조사 후 업데이트 필요
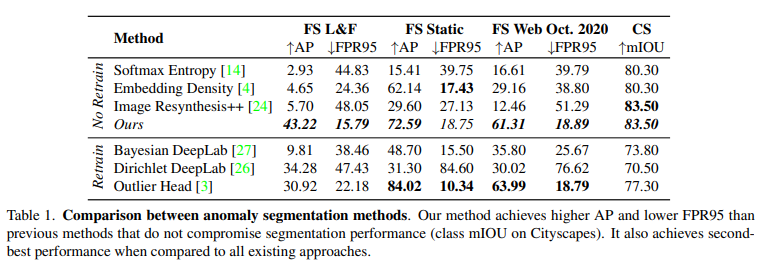
Table 1에서 보면 No Retrain과 Retrain으로 구성된 것을 볼 수 있습니다. Retrain인 경우, Outlier Exposure에 해당하는 방법론입니다. 기존 Outlier Exposure 방법론들은 이상치에 해당하는 정보들을 재 학습함으로써 불확실성을 예측하는 방법론에 해당합니다. 저자는 이러한 방법론들이 정확도 측면에서는 우세하더라도 재 학습이 필요하게 됨으로써, 다양한 이상치에 대해 일반화가 힘들어진다는 점을 지적합니다.
그럼에도 불구하고 저자가 제안하는 방법론은 FS L&F에서 SOTA를 달성하고, CS에서 우세도 우세한 성능을 보여줌으로써 일반화된 성능을 보여줍니다. 또한 베이스가 되는 불확실성을 이용하는 Softmax entropy과 가상의 영상을 생성하는 Image Resyntehsis++보다 높은 성능을 보여줌으로써 두 방법론을 결합함으로써 우세한 성능을 보여줍니다.
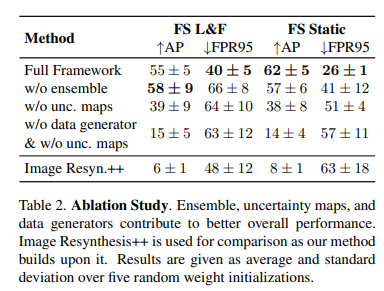
또한 저자는 Table 2와 같이 각 모듈을 제거하며, ablation study를 진행하여 제안하는 방법론의 효과를 정량화하여 보여줍니다.
=========================================================================
최근 가짜 레이블 정보를 이용한 자기지도 학습에 대한 연구가 붐을 이루고 있습니다. 하지만 가짜 레이블을 이용하는 방법론의 한계로 노이즈가 되는 정보도 학습에 사용된다는 문제가 있습니다. 해당 방법론은 이런 정보들에 이상치를 예측하여 노이즈를 필터링 함으로써, 앞서 이야기한 한계를 극복할 수 있을 것 같다는 생각이 들었습니다. 추후 승현이와 함께 진행하고 있는 연구에 적용해보는 것도 좋을 것 같다는 생각이 듭니다.