해당 논문은 IEEE ACCESS에 2021년에 나온 논문으로 10월에 최종승인되었습니다. 그 History는 아래와 같습니다.
Received October 8, 2021, accepted October 13, 2021, date of publication October 15, 2021, date of current version October 25, 2021
처음 제출한게 Oct. 8th 인데 Publication까지 10일도 걸리지 않았네요?… 역시 IEEE ACCESS는 돈을 많이내서 그런지 프로세스가 빠른가봅니다.
음 해당논문은 욜로베이스에 Thermal을 쓰는데 AP기준으로 성능이 좋게 나온 논문이 있다는 김지원 연구원의 추천으로 읽게되었습니다.
일단, 멀티스펙트럴이 아니라서 좀 아쉽지만 그래도 YOLO로 적외선 영상에 대해 연구를 진행한 논문이 많이 없었기 때문에 좀 색달랐습니다. 또한, 개인적으로 느끼기에 욜로시리즈 난이도가 SSD나 R-CNN에 비해 좀 더 높은편이라 리마인드하고 복습하는 느낌에서 좋았습니다. 개인적으로 욜로시리즈는 매번 볼때마다 그전에 안보이던 새로운것을 얻어가는거 같네요.
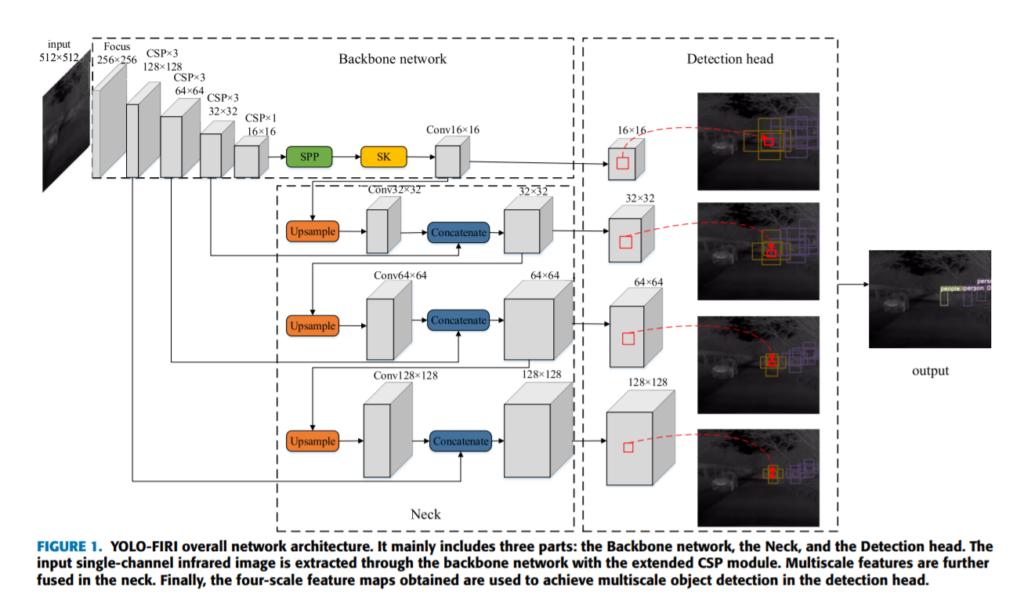
먼저 이게 전체적인 파이프라인이고, 그림에서 자명하게 드러나듯 input으로 적외선 영상을 받고 detection을 수행하는 그런 구조 입니다. 대부분의 욜로시리즈가 그러하듯이 역시나 메인저자가 관여했던 욜로3에서 큰영감을 받아 FPN 구조를 띄고 있습니다. 그렇다면 차이점들이 무엇인지 한 번 같이 알아봅시다.
YOLO 시리즈 3에 대해서 학습하신적이 있으신 분들은 아마 전체적인 흐름을 이해하는데는 어렵지 않을거라고 생각이 들지만, 그래도 해당 논문만을 읽고 이해하는데 쉽지않은 부분들이 생각보다 많이 있습니다. 실제 이 리뷰를 작성하기전에 아래 4개의 논문을 띄워놓고 원하는 부분들을 찾아가며 읽었고, 그를 통해 궁금증을 해결할 수 있었습니다. 제가 참고했던 논문들을 소개해드리겠습니다. 이중 몇개는 제가 리뷰도 했던거 같은데 참고해보시면 좋을거같고 아래 링크와 같습니다.
- YOLO-FIRI: Improved YOLOv5 for Infrared Image Object Detection (리뷰하려는 논문)
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- YOLOv3: An Incremental Improvement
- YOLOv4: Optimal Speed and Accuracy of Object Detection
- https://www.youtube.com/watch?v=a0sxeZALxzY CSPNet설명 YouTube 동영상(20분 분량)
모두 좋은 논문들이라 한 번쯤 읽어보시길 추천드립니다. 특히 CSPNet은 내용이 논문으로는 좀 어려워 YouTube를 참고하여 도움을 받았습니다.
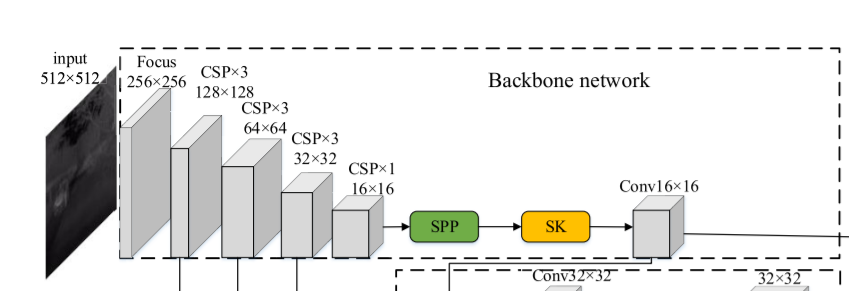
그럼 먼저 아키텍쳐중에서 Backbone network에 대해서 살펴보겠습니다. 다른 detection network들과 크게 다르지않게 Backbone 네트워크를 이용하여 적외선 영상을 인풋으로 받고 다운샘플링하며 중간중간 피쳐들을 뽑아내서 사용을 합니다. 하지만, 여기서 몇몇개 살펴볼만한 것들이 있기에 소개하겠습니다.
먼저, CSP 네트워크에 대해서 이야기 해봅시다. CSPNet은 DenseNet의 후속연구로 나온 모델이며 그 목적은 경량화에 있습니다. DenseNet은 엣지컴퓨팅 방식으로 연산처리하는데 어려움이 있었고, 저자는 Jetson시리즈와 같은 임베디드보드상에서 모델을 돌리기위해 경량화된 모델설계에 대한 연구를 하였습니다. 이와 같은 아이디어 에서 비롯하여 아래 그림 (b)와 같이 CSPNet을 제안하였습니다.


대략적인 내용으로 DenseNet에서는 DenseLayer마다 별도의 CNN 블록에서 나온 features를 concat 하여 이어가는 식으로 설계를 하였는데 이러한 방식에서는 gradient 계산이 중복된다고 지적하였습니다. 즉, 위의 그림 (a) Dense Layer1에서 맨앞에 초기 feature map이 모든 dense layer마다 copy되어 feed-forward 및 backprop 연산에 관여합니다. 이러한 불필요하게 중복된 gradient연산은 모델의 computation time을 높이고, 정확도면에서도 오히려 더 떨어지는 결과를 초래한다고 주장합니다.
따라서, DenseNet에서 이러한 중복되는 부분을 제외하기위해 위의 그림 (b)와 같이 CSPNet을 사용합니다. Dense Layer 1에서 초기에 feature 전체를 사용하지 않고 partitioning 하여 사용하기 때문에 훨씬 경량화되었으며, 성능도 더 올랐다고 합니다. 해당 CSPNet구조는 일반적인 CNN 백본네트워크에도 적용할 수 있단 장점이 있습니다.
백본네트워크를 설명하기위해 말이 좀 길어졌는데 다시 메인토픽으로 와서 설명을 이어가겠습니다.
해당 논문에서는 512 x 512 해상도와 1채널의 적외선 영상을 인풋으로 받아 256*256*4 로 변환한뒤 위에서 설명드린 CSP구조를 반복하여 사용하는식으로 레이어를 쌓아서 피쳐를 추출합니다.
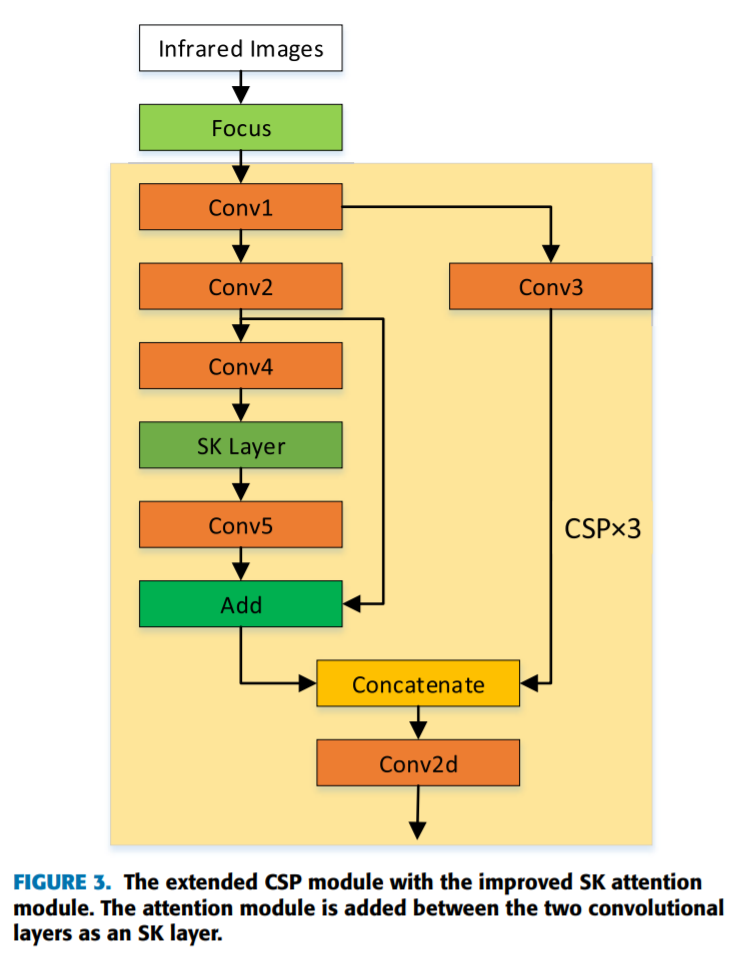
좀 더 자세히 안을 들여다보면 위와같은 구조로 되어있습니다.
여기서 아마 SPP와 SK Layer가 무엇인지 궁금증을 느끼셨을 겁니다. 차례대로 설명해드리겠습니다.
SPP는 2015년에 나온 논문으로 딥러닝의 거장중에 한명인 Kaiming He이 1저자로 작성한 논문에서 제안한 방법입니다.
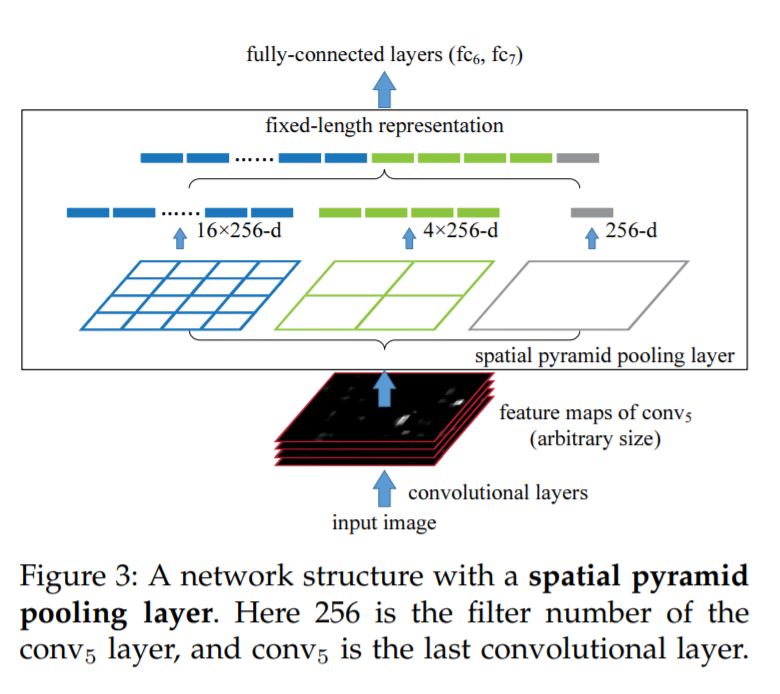
SPP 논문에서 그림을 따왔습니다. 위와같이 pooling을 이용하여 1D 로눌러쓴 피쳐를 사용하는게 SPP의 핵심입니다. 이때, SPP를 쓰는 이유는 바로 scale invariant 하기 때문입니다. CNN은 레이어를 통과하면서 해상도가 변하게되는데 SPP같은 경우에는 풀링을 사용함으로써 channel dimension에 따라서 아웃풋으로 반환되는 1D vector가 달라지게됩니다. 즉, 해상도에 상관없이 channel에 의해서만 1D vector의 길이가 달라지므로, CNN 레이어 사이에 SPP 레이어를 추가하면 scale 에 상관없이 모델을 학습할 수 있습니다. 이러한 방법론은 2015년 이미지 분류 분야에 적용되어 당시 SOTA 성능을 달성하였습니다.
그런면 여기서 질문이 SPP는 1D vector를 아웃풋으로 내보내는데, Fully convolutional network 구조에서는 과연 어떻게 적용을 할까요? 제가 이번에 리뷰하고 있는 논문에서도 CNN 블록들 사이에 SPP Layer를 추가하여 사용하였는데 과연 어떠한 방법으로 사용한 것일까요? 그 해답은 YOLO v4 논문에서 찾을 수 있었습니다. YOLOv4 논문에서는 아래와 같은 문구가 등장합니다.
“Since the SPP module proposed by He et al. [25] will output one dimensional feature vector, it is infeasible to be applied in Fully Convolutional Network (FCN). Thus in the design of YOLOv3 [63], Redmon and Farhadi improve SPP module to the concatenation of max-pooling outputs with kernel size k × k, where k = {1, 5, 9, 13}, and stride equals to 1.”
YOLOv4 논문에서는 YOLOv3 저자가 해당 문제에 대해서 다루었다고 하는데 실제 YOLO v3 논문에서는 저러한 얘기가 등장하지 않습니다. YOLOv3 논문은 레퍼런스와 리부탈레터 빼면 총 4페이지 밖에 않되는 짧은 캐쥬얼한 형식의 technical report이기 때문에 아마도 생략된거 같습니다. 하지만 저런 내용이 YOLOv4에 있는거보면 아마도 코드를 분석하고 쓴거 같네요.
아무튼 SPP의 컨셉을 살려서 풀링을 하고 kernel 사이즈가 k x k 인 아웃풋을 stack하여 피쳐맵을 만드는식으로 SPP를 CNN에서도 사용합니다.
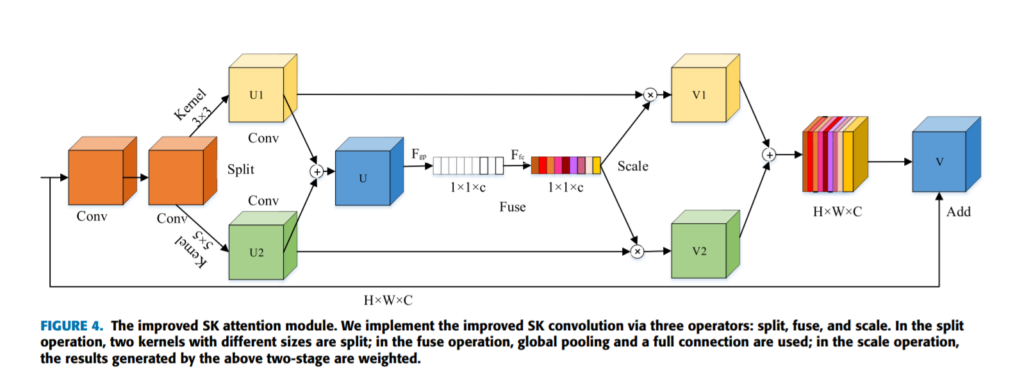
다음으로는 SK모듈인데, conv feature를 split하여 두개로 만들고 sum한 피쳐맵에서 weigh를 뽑아낸 후, 해당 weight를 다시 split된 피쳐맵에 곱한 후 concat하는 식으로 attention을 주는 방법입니다.
말이 좀 복잡햇는데 위의 그림을 보시면 이해가 쉬울거라고 생각합니다. 사실 이러한 형태의 attention은 제가 리뷰에서 굉장히 여러번 다루었습니다. 최근 성능좋은 detection 모델은 거의 attention모델을 달고있는 경우가 많아서 어찌보면 이제는 필수가 아닐까 싶기도 합니다.
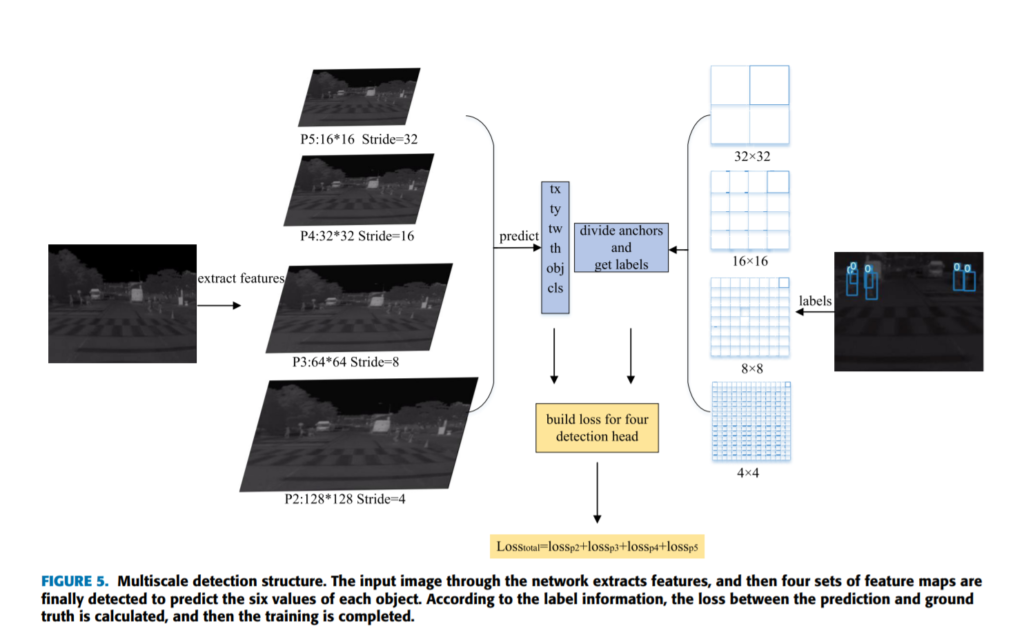
여러가지 설명한 요소들이 앞에 있었지만, 전체적인 파이프라인은 다른 욜로시리즈와 매우 비슷합니다. 욜로시리즈들이 대부분 3개의 scale이 다른 feature map을 뽑아내는데 해당논문에서는 4개를 뽑아내며 그 이유는 small object에 대해서도 좀 더 잘 찾기위해서 이라고 합니다.
피쳐맵에서의 아웃풋은 욜로기 때문에 x, y, w, h, obj, cls 순으로 나오고요. 각각 bounding box의 좌표와 object인지 아닌지에 대한 확률, class에 대한 확률값으로 나오게 됩니다. 이때, x, y 각 1개의 픽셀을 0~1로 두었을때의 bbox의 상대적인 값이며, x, y는 bbox의 left top corner가 아닌 center값을 의미합니다. bounding box는 w, h 에 따라 scaling되어있으며, 여기서 각 피쳐맵마다 스캐일이 다르기때문에 나중에 prediction값을 다시 원래의 해상도로 돌릴때는 이를 고려하여야합니다.
loss는 다른 yolo 시리즈와 동일하며 제가 이전에 작성해둔 욜로시리즈 리뷰를 참고해보시기 바랍니다.
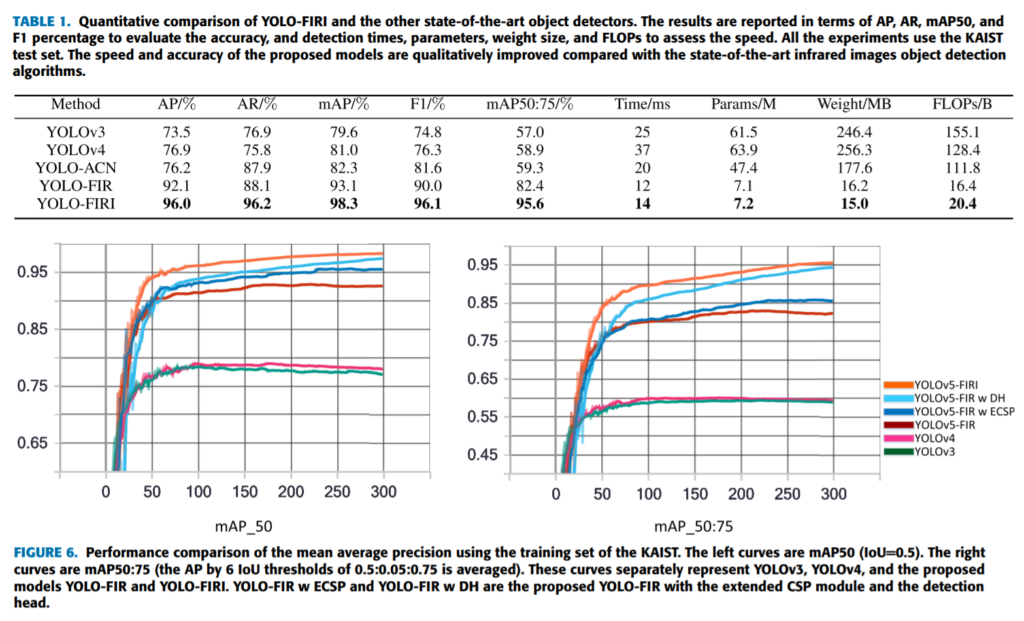
평가에서 상당히 좋은 성능을 보입니다. 그런데 카이스트 데이터셋에서 AP 로 평가한 점수가 익숙하기 않아서 얼마나 좋은지 감이 잡히지 않습니다. 음…얼핏보기에는 thermal만 사용해서도 multispectral을 넘겼다고 까지도 보이는데요. 정확한건 miss-rate를 기준으로 해봐야 알거같은데 코드를 공개하진 않네요.
그래서 생각을 해봤는데 아무래도 AP score로 평가한건 기존 다른 논문들과 동일한 세팅에서 miss-rate 평가지표를 기준으로 평가하면 height 기준 55 pixel 이하를 ignore 처리하기 때문에 small object를 찾으면 false positive로 분류되어 패널티로 작용하였기 때문이 아닐까 싶습니다. 과연 miss-rate로는 몇일지 궁금하긴 한데 원복실험을 해볼만큼 가치있는 논문은 아닌거같네요.
개인적으로 요새드는 생각이 ultralytics 얘들이 만든 yolov5가 이슈가 없고, 성능도 좋으며 코드 정리가 깔끔하게 잘되어있는거 같은데 해당 네트워크를 기반으로 멀티스펙트럴에 사용해보는게 어떨까 싶습니다. 근데… 모듈화가 너무 많이되어있어서 싱글모달리티일때는 아주편하지만, 멀티스펙트럴로 바꾸는데는 그 dependent한 관계를 모두 해결해야 하는데 매우 쉽지 않아보입니다. mmDetection을 multispectral로 바꾸는 수준의 cost가 소요되지 않을까 싶습니다.
yolo v5 코드가 보기 어렵더라도 결국 같은 코드여서 해당 코드를 멀티스펙트럴로 변경하실 수 있습니다. 변경해주실 것으로 믿겠습니다. 해당 논문은 단일 모달리티에서 좋은 성능을 나타냈네요. 근데 말씀하신것처럼 성능만보면 기존 연구들에서 리포팅하는 성능과 갭이 존재해 의심이 드는것 같습니다. 추가적으로 이와 관련해 평가 부분에서 특별히 언급한건 없었나요?
Object Detection 분야에서 YOLO 뿐만아니라 여러 방법론들이 존재하는 것으로 알고 있습니다. 그러나 YOLO만큼 여러 버전이 나왔던 방법론은 없었던 것 같은데, YOLO만 버전이 많은 이유는 어떤 것이라고 생각하시나요?