IITP 비대면 과제가 마무리되어가는 시점에 저희 과제와 동일한 연구를 진행한 논문을 읽어보았습니다.저희 과제에 대해 익숙하지 않으실 분들이 있을 것 같아 논문을 가능한 자세하게 적고자 노력하였습니다.
시작에 앞서
김지원 연구원과 제가 참여하고 있는 IITP 비대면-뇌인지 과제에서는 우울 정서 판단을 위해 스마트폰에서 취득된 여러 센서데이터를 기반으로 유도 특성(Derived Feature) 모델링하는 방법 즉, 피처모델링에 대해 연구하였습니다. 9월 중 슬랙에서 안드로이드 스마트폰 사용자 분들에 한하여 어플 설치를 요청드린 이유가 바로 이 연구를 위한 것이었습니다. (늦었지만 데이터 수집 요청에 흔쾌히 응해주신 연구원분들 모두 감사합니다 ?♀️ )
현대인들은 거의 서마트폰을 끼고(?) 산다해도 과언이 아닌데, 그렇기에 1)스마트폰의 내장된 센서로 수집되는 데이터로 2)사용자의 행동을 인식하고 3)행동 패턴을 판단하여 4)우울 정서를 판단하고, 더 나아가 5)그에 맞는 대응까지 하는 것: 이 최근 많이 수행되는 우울 정서 판단 관련 연구입니다. 스마트폰은 충분히 고도화되어 내장된 센서들의 정확도 역시 충분히 신뢰 가능하며, 현대인들의 스마트폰 밀접도가 일상과 거의 같기에 행동 패턴 파악 역시 가능하다는 점에서 연구가 활발히 진행되고 있습니다.
따라서 저희 이번 과제에서는 데이터로 (1)수면활동, (2)신체활동, (3)주의집중력, (4)사회적교류, (5)표정 관련 유도특성을 추출하여 우울 정서를 예측하였습니다. 이제부터 본 논문은 어떤 데이터를 사용하여, 어떤 피처모델링을 하였고, 어떤 유의미한 분석을 가져왔는지 확인해보도록 하겠습니다.
[JMIR Mhealth Uhealth] Predicting Depression From Smartphone – Link

Introduction
Clinician-administered & Self-Reported Questionnaires (의사가 관리하거나, 자가보고식 설문지를 이용한 우울증 진단) 과 같은 전통적인 우울증 진단 방식은 내원이라는 높은 진입장벽 혹은 자가보고식 설문지 작성 시 발생할 수 있는 기억 왜곡 및 사회적으로 바람직한 답변을 작성해야한다는 인식으로 인한 신뢰성 하락과 같은 한계가 있습니다.
스마트폰과 웨어러블은 이런 전통적인 우울증 진단 방법의 한계를 극복할 수 있는 기기로 관심을 받고 있습니다. (IITP 과제가 바로 여기에 해당합니다) 스마트폰 및 웨어러블 기기는 내장된 센서를 통한 개인화 및 실시간 모니터링이 가능하다는 장점이 있습니다. 따라서 해당 기기로부터 수집된 데이터로 개인의 행동 패턴을 파악하고, 이를 통한 개인의 정신 건강 판단, 이후 기기를 통한 직접적이고 시기적절한 대응까지 가능하다는 점에서 많은 연구진들이 해당 연구를 진행하고 있습니다.
본 논문에서도 스마트폰에서 취득된 데이터로 bio marker^* 를 사용하여 우울증을 예측할 수 있는 가능성에 대한 연구를 진행합니다. 지금부터는 해당 논문에서 피처모델링을 어떻게 설계하였고, 데이터셋은 어떻게 구성되어 있는지 IITP 에서 진행한 연구와의 차이점을 위주로 리뷰해보고자 합니다.
* bio marker 란, 생물학적 과정 또는 의료 개입에 대한 반응 지표로 계량화되고 평가되는 병리학적, 해부학적 또는 생리학적 특성을 의미합니다.
Dataset
먼저 해당 논문을 위한 데이터셋은 저희 과제와 마찬가지로 실제 사람들로부터 취득된 데이터입니다. 차이점은 저희 과제에서 수집한 데이터는 실제 내원한 임상 환자의 데이터이며, 해당 논문은 전세계 익명의 안드로이드 사용자의 데이터입니다. 또한 Carat 이라는 어플을 통하였기 때문에 전세계의 다양한 익명의 데이터를 수집할 수 있었으며, 총 6달동안 843명의 데이터를 수집할 수 있었다고 합니다.
Carat 는 Helsinki 대학의 연구진으로부터 개발된 모바일 센싱 어플로, mobile app store 에서 무료로 접근이 가능하기 때문에 공간 및 인종의 제약없이 다양한 데이터를 수집할 수 있었다고 합니다. (아래는 실제 어플인데, 안드로이드 뿐만 아니라 IOS 사용자도 다운이 가능한 것 같네요…?)

Mobile Sensing Variables Collected by Carat
(수집 데이터 목록)
- 배터리 소모량
- foreground app 사용량 (i.e. 사용자가 상호작용한 앱)
- 인터넷 연결 상태
- Screen Lock/Unlock log
- (+) 자가보고식 설문지를 통한 나이, 성별, 학벌, 직업 정보
- (+) 우울증 심각성 판단을 위한 PHQ-8 설문 결과
Mental Health Assessment ( 정신 건강 판단 )
사용자들은 Carat 앱을 통해 2주간격으로 PHQ-8에 응답합니다. PHQ-8 은 우울 심각도 평가를 위해 개발된 자가보고식 평가지인 우울증 선별도구 PHQ-8(Patient Health Questionnaire)로, 임상적으로 검증된 지표이면서 이전 연구에서 계속 사용되온 지표이기 때문에 해당 지표를 사용했다고 합니다. (저희 연구에서 사용된 지표는 8문항이 아닌 9문항으로 구성된 PHQ-9 입니다.) 설문은 지난 2주간의 우울증 중증도를 “어떤 일을 하는데 흥미나 즐거움이 거의 없다”, “기분, 우울함, 절망감”, “떨어지거나 잠들어 있거나 너무 많이 자는 것”과 같은 항목으로 구성되어 있습니다. 각 항목은 0(전혀 그렇지 않음)에서 3(거의 매일)로 응답하며, 총 점수는 0에서 24까지이고 10점 이상일 경우 심각한 우울증을 의미합니다.
Feature Modeling
Entropy
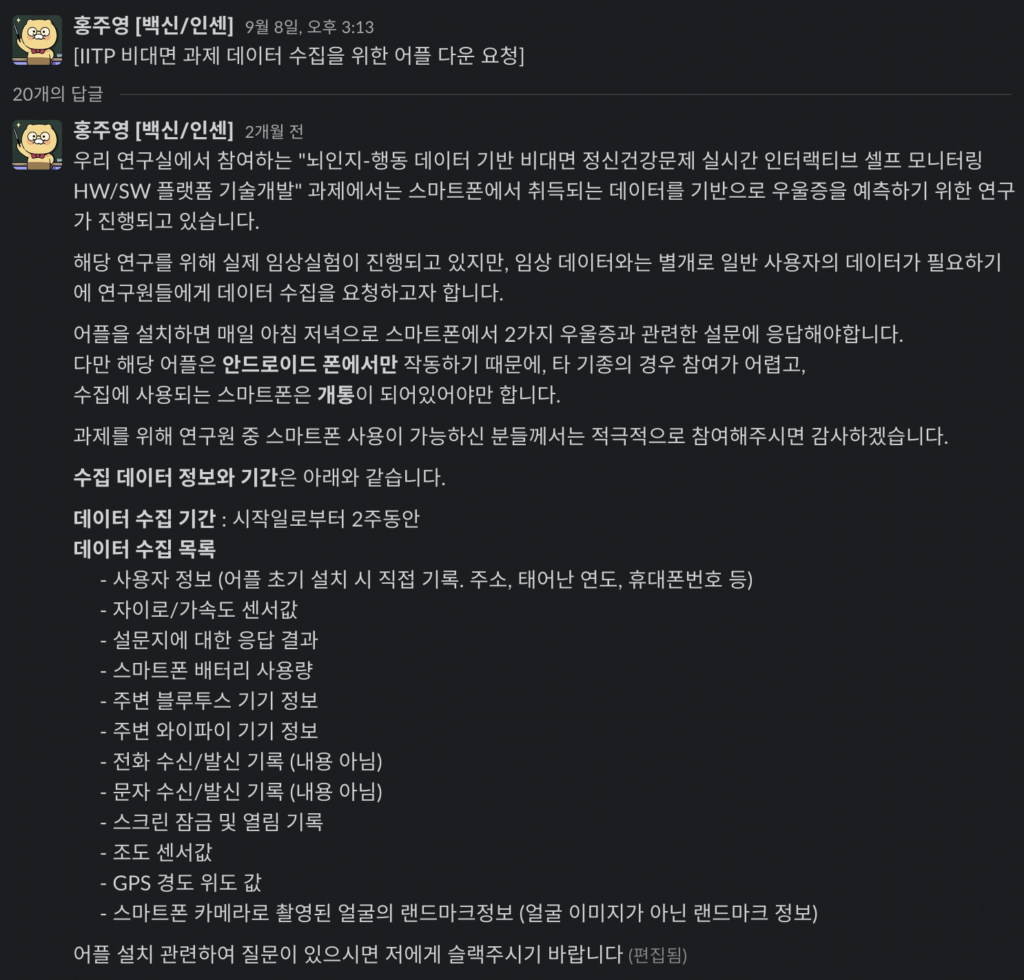
엔트로피를 계산하여 매일 24시간 동안 화면 상태(켜짐/꺼짐 상태), 인터넷 연결(연결 끊김/연결 상태), 포그라운드 앱(앱당 사용 빈도)에서 참가자 행동 상태의 변동성, 복잡성, 무질서 및 임의성의 정도를 파악합니다. 엔트로피는 아래 공식에 의해 계산됩니다.
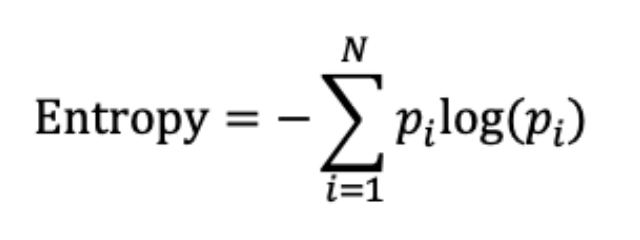
- N: the number of states
- p_i: the percentage of the state i: in the time series data
예를 들어, Screen Entropy 가 낮으면 사용자의 화면이 24시간 동안 한 상태(켜짐 또는 꺼짐)에 있는 경우가 많다는 것을 의미합니다. 추가로 엔트로피를 로그(N)로 나눈 것으로 정규화된 엔트로피를 계산하였다고 합니다.
Regularity Index
Regularity Index (규칙성 지수)는 서로 다른 요일에 걸쳐 동일한 시간 사이 사용자 행동의 유사성(또는 차이점)을 파악하여 사용자의 행동 패턴을 수치화한 값을 나타냅니다. 예를 들어, 매일 9시 사용자의 인터넷 연결 상태의 패턴을 수치화하는 것이 바로 규칙성 지수입니다. 아래 수식을 통해 a와 b일 동안의 화면의 규칙성 지수, 인터넷 접속성, 그리고 포그라운드 앱 사용량의 Regulartiy Index를 계산할 수 있습니다.
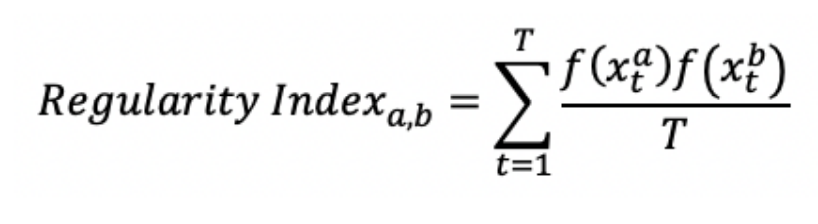
- a & b: 2-day pairs
- T: 24 hours
- x_t^a: the rescaled (ie, between –0.5 and 0.5) value of hour t of day b
Standard Deviation and Counts
Standard Deviation(표준 편차) Feature 는 하루를 기준으로 4일 epoch 간의 일일 동작 변화를 확인합니다. 이 때, 오전은 6-11시, 오후는 12-17시, 저녁은 18-23시, 밤은 0-5시로 설정하였다고 합니다. SD와 count feature는 아래와 같습니다.
- 각 화면 상태 수, 각 인터넷 연결 상태 수, 일일 epoch당 포그라운드 앱 사용량 수
- 일일 에포크당 일일 SD
- 각 화면 상태의 요일 수, 각 인터넷 연결 상태 수, 포그라운드 앱 사용 수
- 포그라운드 앱을 하루에 처음 및 마지막으로 사용할 때까지의 분 수
Result
Participants’ Demographics
아래는 테이블은 데이터 수집에 동의한 사용자들의 정보입니다. 남자의 피실험자가 매우 많고, 고학력의 사용자의 비율이 높다. 또한 해당 어플을 개발한 나라인 USA 출신 사람이 많다는 특징이 있습니다.




Other Country : Comprising 49 different countries with less than 15 participants, including South Africa, Morocco, Brazil, Philippines, Qatar, Japan, Russia, and Denmark.
Smartphone Data and PHQ-8 Distribution
테이블2는 PHQ-8 의 설문 결과 응답 횟수를 나타내며, 테이블 3은 스마트폰 데이터의 분포와 참가일수를 나타냅니다.


Predicting Depression From Features
아래는 추출한 Feature 만을 가지고 10 fold cross validation 에 대한 테이블입니다. RF를 사용했을 때, Accuracy가 97.97%이라는 성능을 달성하였음을 보입니다.

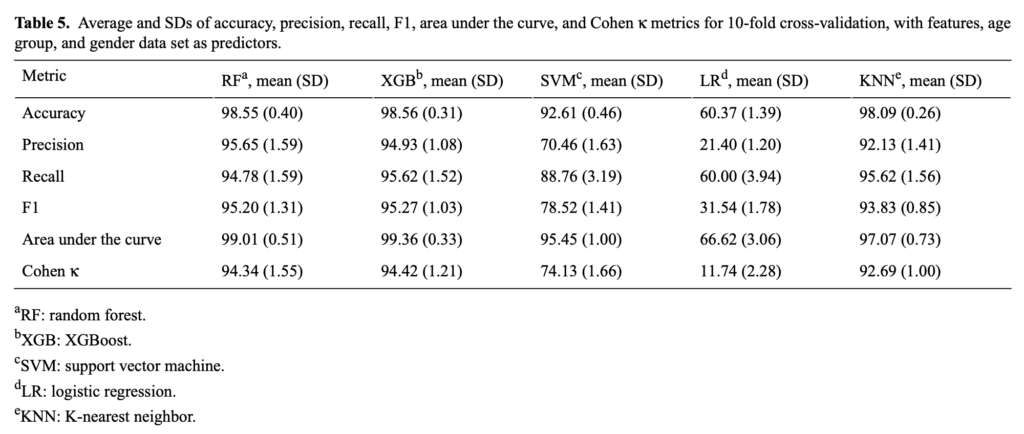
그리고 테이블 5는 추출한 Feature에 나이, 성별에 대한 정보를 추가하여 성능을 리포팅한 결과인데요, 전반적으로 성능 향상을 가져왔다고 언급하였습니다. 특히 RF를 사용했을 때, Accuracy가 98.55% 라는 성능을 달성하였음을 보였습니다.
Conclusion
본 논문의 연구 결과는 우울증에 대한 전통적인 평가를 강화하는데 있어 digital bio-marker 유용성에 대한 설득력을 강화시키고, 이에 따라 스마트폰을 통한 우울증의 지속적인 모니터링이 가능함을 보입니다.
screen, internet, application 데이터만으로 상당한 성능을 리포팅하였는데, 데이터의 imbalancing을 고려할 때 General 한 모델인지는 확인이 필요할 것 같습니다. 다만 해당 방법을 통한 피처모델링을 과제에서 수집된 데이터에 적용하여, 논문에서 첨부된 여러 Feature Importance, Correlation, Association 을 분석해볼 필요가 있겠다는 생각이 드는 논문이었습니다.
PHQ-8 평가지가 평가의 실제 정답값이 되는 것 인가요?
그렇다면 평가지에 응답하는 행위 자체에 노이즈가 있을 확률도 있을 수 있다는 분석도 혹시 포함되어있느지 궁금합니다.
네 아무래도 IITP 과제에서 수집된 임상 실험자들과는 달리 어플을 통한 비대면으로 수집된 데이터다 보니 PHQ-8 평가지가 실제 정답값이 됩니다.
아쉽게도 질문주신 응답하는 행위에 대한 노이즈에 대한 분석은 없었네요!