KAIST Benchmark Datasets을 이용하여 활발한 연구를 수행중인 카이스트 노용만 교수님 연구실에서 나온 논문입니다.
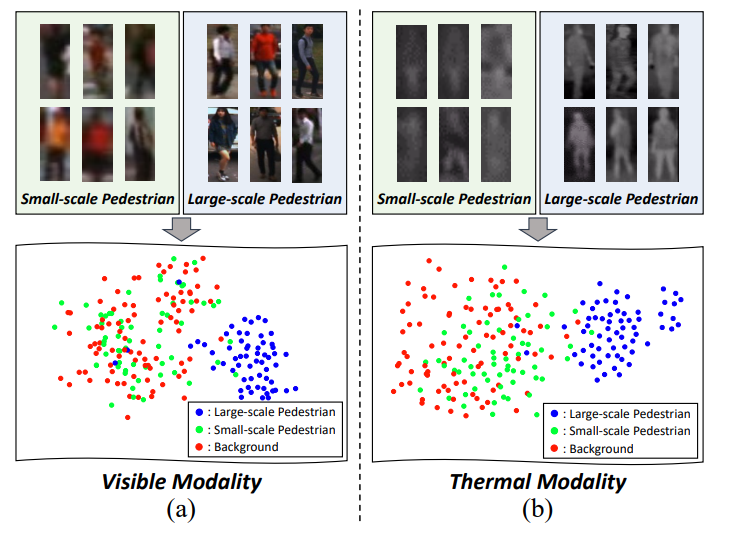
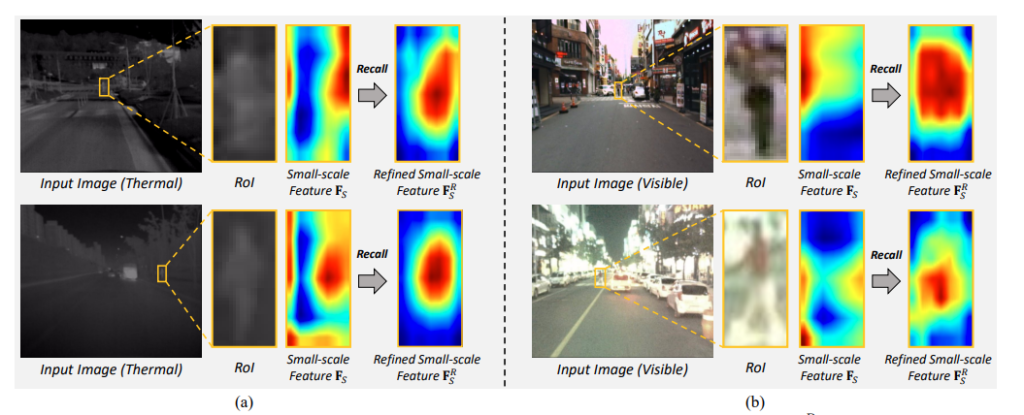
보행자 인식에서 small Pedestrian을 검출하는것은 어려운 문제입니다. 해당 논문의 티저 이미지를 통해 확인해보면 실제 small-scale Pedestrian 의 feature가 Large-scale Pedestrian과 비교하여 Background와 구분되지 않는 것을 확인할 수 있습니다. 이는 Visible, Thermal 모두 동일하게 나타나는 문제입니다. 그리고 이 논문에서는 이러한 Small-scale Pedestrian을 잘찾기위해 Memory Network를 적용하였습니다.
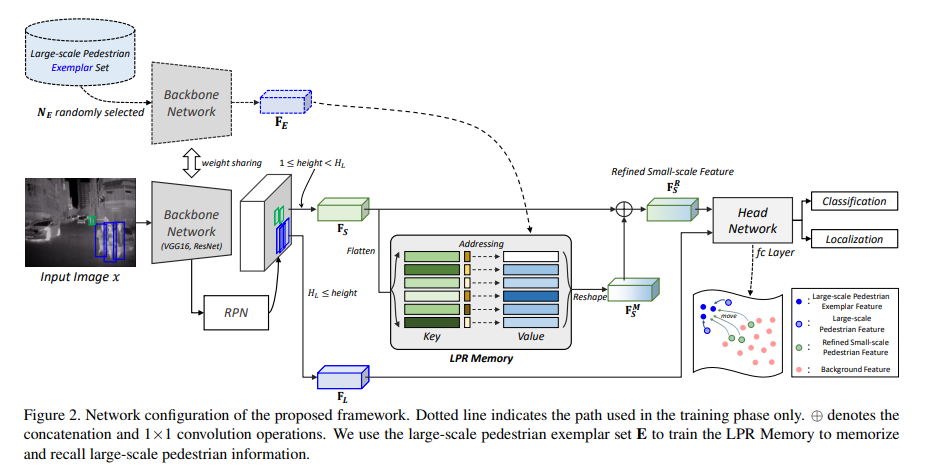
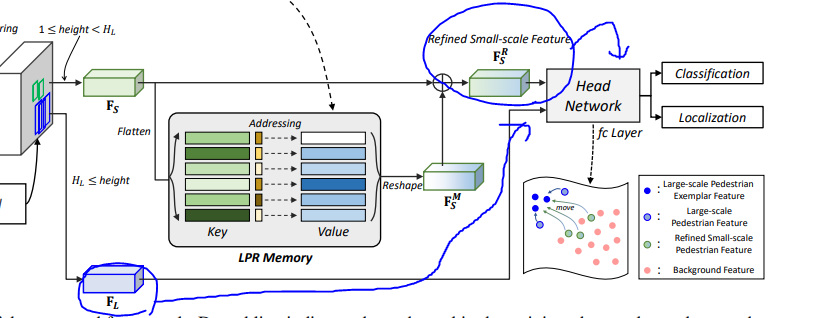
본 논뭉네서 제안하는 전체 프레임워크 입니다. 특징적인 부분을 살펴보면 학습 데이터에서 Large-scale Pedestrian Exemplar set을 만들고 동일한 Feature를 추출합니다. 이를 통해서 LRP Memory 라는 Memory Network를 학습하게 되고, 이후 Detection을 수행할 때 ROI 기준으로 small pedestrian이 감지된다면 해당 small pedestrian feature는 memory network에 입력하여 small pedestrian feature를 refine 하게 됩니다. 그렇다면 LRP Memory는 어떻게 작용할까요?
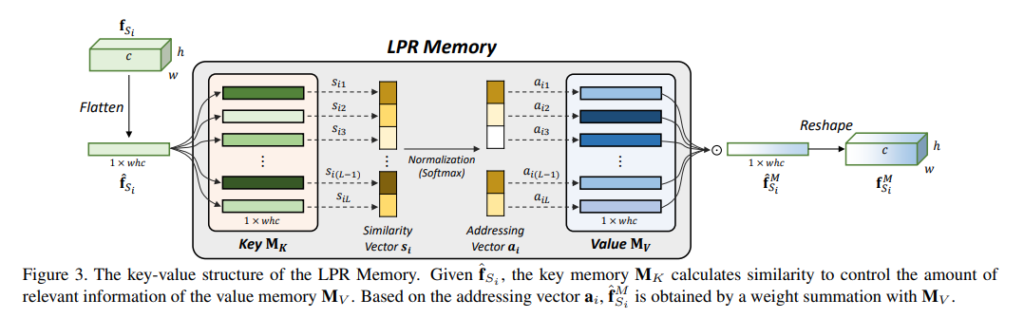
먼저 LPR Memory는 key와 value의 값을 가지고 있습니다. (해당 네트워크의 key와 value를 구하는건 뒤에서 설명하겠습니다.) ROI의 사이즈에 의해서 small-scale feature로 구분된 feature vector를 LPR memory의 입력으로 사용합니다. 그러면 해당 feature vector와 LPR memory의 key와의 cosine similarity를 구하고, 이를 softmax 하여 value와 곱하고 최종적으로 refine feature를 만들게 됩니다. 이를 수식적으로 나타내면 다음과 같습니다.
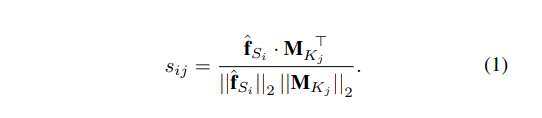
입력을 LPR Memory의 key값과 cosine similarity를 구하고,

soft-max를 취한 후에 value 값과 곱하여 새로운 feature를 만드는 과정입니다. 이렇게 하면 small pedestrian feature를 refine 하여 detection을 더욱 잘할 수 있다고 합니다.
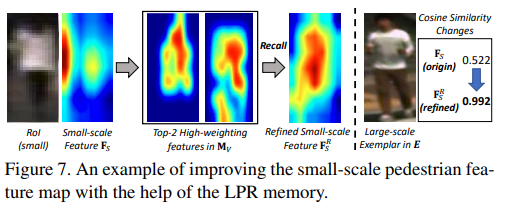
다음과 같이 feature를 refine 하게되며, 이는 detection 성능을 향상시킨다고 합니다.
앞서 티저영상과 다르게 이러한 refine을 수행하고 다시 t-sne로 나타내면 small-scale pedestrian의 feature가 더 잘 구분됨을 확인할 수 있습니다.

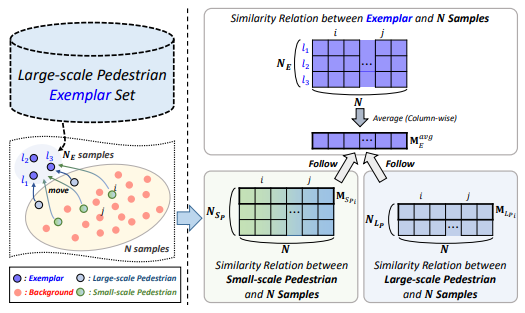
자 그렇다면 다시 LPR Memory의 key와 value는 어떻게 구할 수 있을까요? 방법은 Large-scale의 pedestrian을 모아둔 examplar set에서 동일하게 feature vector를 추출하고 처음 랜덤으로 설정되는 key와 similarity를 구하게 됩니다.
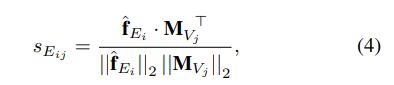
그리고 동일하게 softmax 이후 value 값과 곱을하여 refine 하게 되죠.
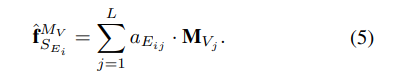
이렇게 나온 refine feature는 large-scale pedestrian feature와 동일해져야 하고, 입력 자체가 large scale pedestrian 이여야 하므로 Loss는 다음과 같이 설정하게 됩니다.
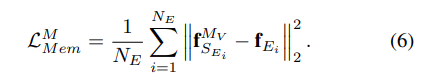
즉 입력된 feature와 memory network의 key와 value를 통해서 refine한 feature가 동일하도록 loss를 설계하면 memory network는 large feature로 변경하는 key와 value를 학습하게 됩니다. 여기에 한가지 모델의 프레임 워크를 다시 살펴보면 Detection head에는 Large scale feature와 refined small scale feature가 동시에 들어갑니다.
이를 Head Network가 학습하려면 두 feature가 유사해야 학습에 방해가 되지 않을 것 같습니다. 이를 위해 저자는 Large-scale Pedestrian Recalling Loss를 추가적으로 제안합니다.
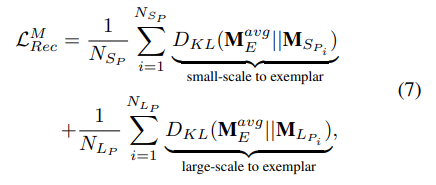
정리하면 KL divergence를 이용하여 small-scale, large-scale pedestrian feature가 large-scale exemplar feature와 유사해지도록 만드는 loss 입니다.
따라서 이러한 Loss 텀이 추가된 최종 Loss는 다음과 같습니다.
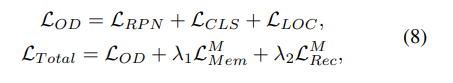
해당 논문에서 제안하는 방법에 대한 실험은 카이스트 벤치마크 데이터셋과 CVC-14 데이터셋에서 진행하였습니다.
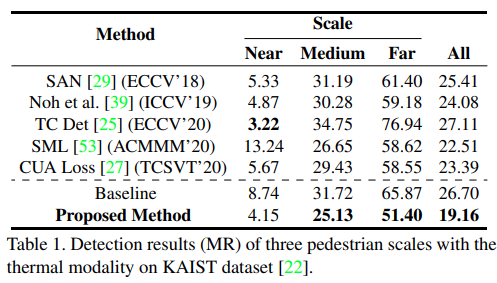
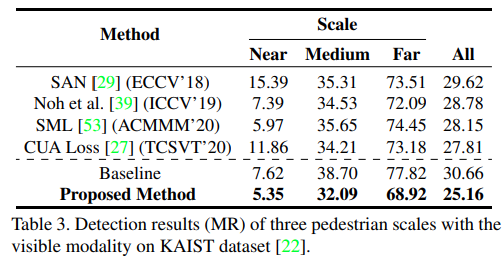
Thermal과 Visible 모두에 대해서 Medium, Far의 성능이 향삼됨을 이야기합니다.
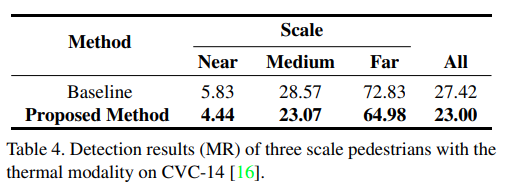
또한 CVC-14 데이터셋 에서도 성능 향상이 나타남을 실험적으로 나타내고 있습니다. 추가로 자신들의 Loss 추가에 따른 Ablation study도 진행합니다. 또한 LPR Memory network의 유무에 따른 성능비교도 함께 진행하고 있습니다.
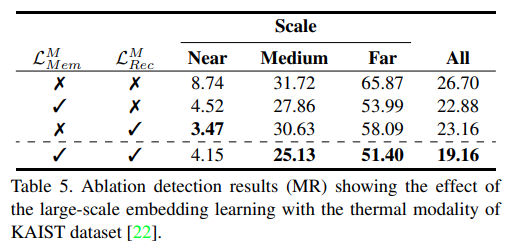
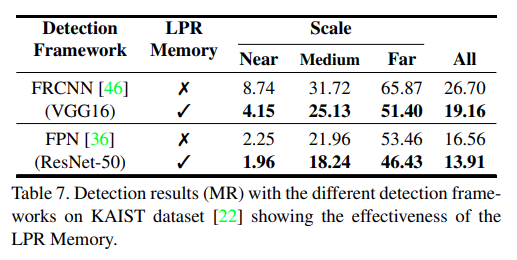
또한 LPR Memory의 slot 갯수에 따른 성능도 아래와 같이 나타내고 있습니다.
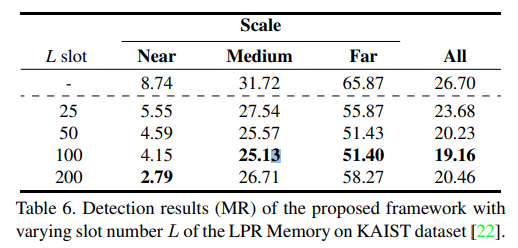
결론
Memory Network라는 것에 대해서 예전에 연세대학교 발표에서 들은적이 있었는데 이런식으로 응용이 가능할 수 있다는걸 알게돼 다양한 분야에 지식이 필요하다는것을 다시 느끼게 됐습니다. 또한 해당 연구실은 카이스트 벤치마크 데이터셋을 이용하여 최근 저널과 학회에 여러편을 제출할 만큼 활발한 연구가 수행되고 있습니다. 해당 연구실의 연구 내용들을 보면서 다양한 자극을 받았는데, 저도 더욱 분발해야할 것 같습니다.
이번 논문 작업을 하면서 읽었던 논문에서 memory bank라는 개념을 사용하는 논문이 있어 비슷한 내용일까 읽어봤는데, 메모리에 올려둔 feature와 유사도를 계산한다는 점이 비슷한 걸 보면 이런 것도 약간 공통적으로 쓰이는 방법론인것 같네요. 논문의 목표가 small-scale pedestrian detection이라 작은 물체만 볼 것이라고 생각했는데, Large-scale feature를 바탕으로 모든 feature에 가중치를 주는 느낌이네요. Memory bank를 쓰던 논문에서는 bank에 들어간 negative 쌍을 배치마다 초기화 해줬는데, 혹시 여기서 memory network에 들어가는 값이 랜덤으로 선택되고 학습 동안 갱신되지 않는지 궁금합니다.