이번 리뷰는 TPAMI2020에 게재된 논문으로 저에게 상당히 충격을 준 논문입니다. 주제는 High Resolution 표현을 잘 살리는 backbone 네트워크이며 저같은 경우에는 Dense level prediction task를 주요 연구주제로 하고 있었기에 상당히 매력적인 논문이었습니다.
Dense level prediction에 관심이 있으신 분들은 꼭 한번 논문으로 읽어보시는 것을 추천드립니다.
Introduction
Deep Neural Network(DNN)은 정말 다양한 테스크에서 우수한 성능을 보여주고 있습니다만 이러한 성능 향상의 시작은 이미지 2012년 ILSVRC에서 그 당시 압도적인 성능으로 1등을 한 AlexNet이 시작이 아닐까싶습니다.
AlexNet을 필두로 다양한 백본 네트워크들 예를 들어 VGG, ResNet DenseNet, GoogleNet 등이 제안되어왔는데 알렉스넷 포함 위에 네트워크들은 모두 LeNet과 유사한 구조를 뛰고 있습니다. LeNet은 아래 그림과 같은 구조로 되어있는데 점진적으로 feature map의 해상도가 줄어드는 특징을 가지고 있습니다.
![Deep Learning, CNN, PyTorch Code] LeNet-5](https://blog.kakaocdn.net/dn/bChW5M/btqTKLpO6ST/bfZ99UcRuKz1xC7LwgrtB0/img.png)
이러한 구조는 low resolution feature map이 가지는 abstract 특징들을 잘 살릴 수도 있으며 해상도에 따라 연산량도 줄일 수 있기 때문에 이미지 분류 task에 적합한 모델입니다.
하지만 영상 내 위치정보들과 구조적 정보들이 필수적인 분야들(Object Detection, Segmentation, Human Pose Estimation etc)에서는 위에 모델들을 사용하기에는 high resolution feature map을 활용하기 힘들기 때문에 그림2. (b)와 같이 추가적인 모델 설계가 필수적입니다.

저희가 흔히 알고 있는 U-Net, HourglassNet, DeconvNet 등 Encoder-Decoder 구조를 가지는 네트워크들을 의미하겠죠.
하지만 이러한 Encoder-Decoder 네트워크들은 결국엔 입력 영상을 encoder를 통해 한번 압축하고 이를 다시 decoder를 통해 원래 해상도로 만드는 작업을 진행하기 때문에 결과적으로 구조, 위치 정보들의 손실이 있을 수 밖에 없습니다.
그래서 저자는 굳이 High to Low로 feature map을 줄였다가 다시 Low to High로 늘릴 필요가 있는가? 에 대해 의문을 품었고 처음부터 끝까지 High Resolution feature를 살리면 되지 않을까 라는 생각을 가졌습니다. 그래서 High-Resolution Net이라는 네트워크 구조를 제안하였습니다.
HRNet
먼저 HRNet의 구조는 그림3과 같습니다.

보시면 첫번째 스테이지에서 계산된 High Resolution Feature map이 2번째 3번째, 마지막 스테이지까지 계속해서 존재하는 것을 확인할 수 있습니다. 물론 새로운 스테이지를 지날 때마다 scale이 2배씩 own sampling이 된 feature map을 생성하여 low resolution representation도 배우는 모습입니다.
또한 한가지 눈여겨 보실 점은, 각 스테이지가 끝날때 쯤에 서로 다른 sclae을 가지는 feature map들끼리 fusion을 하는 것을 볼 수 있습니다. 이러한 fusion은 단순히 High에서 low로 또는 low에서 High와 같이 일방적인 방식으로 fusion되는 것이 아니라, High, middle, Low 모든 스케일의 feature map에 값을 주고 받는 모습입니다.
저자는 이러한 방식을 통해 각각의 stage에서 가질 수 있는 정보들 (예를 들어 High Resolution은 보다 detail한 정보를, middle level은 texture 정보를, low level은 전체적인 abstract, global한 정보들을 가지고 있겠죠)을 서로가 주고 받으며 보다 정확한 feature representation을 학습할 수 있다고 합니다.
그림3을 수식적인? 모습으로 확인하면 다음과 같습니다.
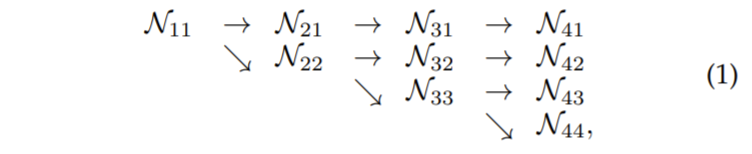
\mathcal{N_{ij}}에서 i와 j는 각각 stage와 scale level을 의미합니다. i값이 커질수록 네트워크의 뒷단을 향해간다는 것을 의미하며 j 값이 커질수록 Low Resolution을 가진다고 생각하시면 됩니다. 참고로 \mathcal{N_{11}}의 경우 해상도는 입력 이미지의 4배 다운 샘플링된 것이라고 보시면 됩니다.
Repeated Multi-Resolution Fusions
제가 위에서도 잠깐 언급드렸지만 i stage에서 i+1 stage로 넘어가기 직전에 1~j stage의 feature map들끼리 서로 fusion을 주고 받는다고 했었습니다. fusion을 어떻게 하는지에 대해 알아봅시다.
방식은 상당히 간단합니다. 큰 feature map은 down sampling을 해주고, 작은 feature map은 target feature의 해상도에 맞게 up sampling을 해줘서 더해주면 됩니다.
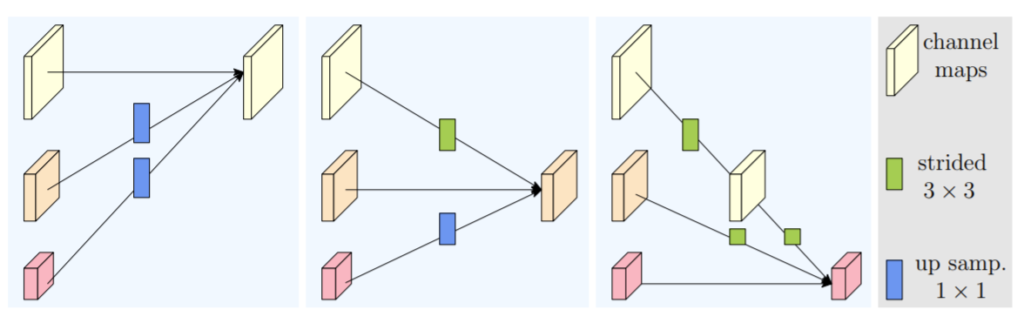
그림4의 제일 좌측의 경우 scale j가 1인 인 feature map이 target resolution 이므로 j=2,3인 feature map들이 up-sampling + 1×1 conv를 타고 나와 더해주게 됩니다. 우측의 경우에는 target resolution이 j=3인 feature map이므로, j=2인 feature map은 2배 down-sampling, j=1인 feature map은 2배 down sampling을 2번 연달아 진행해줍니다.
참고로 down sampling의 경우 3×3 kernel size에 stride 값을 2로 지정한 컨볼루션 레이어를 통하여 down sampling합니다.
Representation Head
그렇다면 최종 output은 어떻게 나오게 될까요? 각 task마다 다르겠지만 해당 논문에서 평가한 task는 각각 Human pose estimation, Segmentation, Object detection 입니다. 그렇기에 각 task마다 서로 다른 representation head를 설계하였는데, 각각의 구조들은 그림5에서 확인가능합니다.
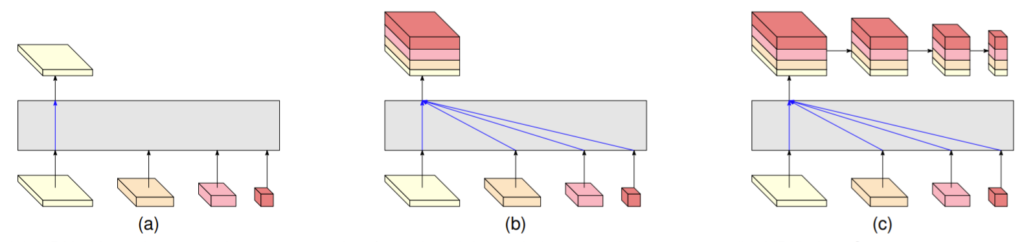
저자는 그림5.a를 HRNet v1으로 칭하며, b는 HRnet v2, c는 HRNetV2p라고 명칭하고 있습니다. HRNet v1의 j=1인 가장 High level의 feature map만을 사용하며 주로 Human pose estimation을 수행하기 위한 heatmap을 예측한다고 합니다.
V2의 경우에는 모든 level의 feature map을 최종적으로 concatenation을 수행하여 예측하게 됩니다. multi scale feature map에서 표현되는 정보들이 중요한 Semantic Segmentation, Object Detection 등이 이러한 multi level feature map을 활용합니다.
최종 resolution으로 up-sampling하는 과정은 bi-linear upsampling과 1×1 컨볼루션을 통해 이루어진다고 합니다. 참고로 object detection 용인 HRNetV2p의 경우에는 HRNetv2에서 multi-scale fusion된 feature map을 다시 down sampling하여 detection에 사용되는 것으로 보입니다.
Model Detail
전체적인 방법론의 설명은 모두 끝이 났고 조금 더 디테일한 부분을 다루도록 하겠습니다. 먼저 위에서도 잠깐 언급했듯이 j=1인 첫번째 stage의 feature map 해상도는 원본 해상도의 4배 다운 샘플링 되었으며 각 스테이지별로 2배씩 다운 샘플링이 됩니다. (1/4, 1/8, 1/16, 1/32)
첫번째 스테이지의 경우 4개의 residual unit으로 구성되어 있으며, 해상도가 높다보니 채널수를 64로 줄이는 bottleneck 구조를 사용했다고 합니다. 그다음 마지막에 3×3 컨볼루션을 통해 채널을 C로 변경하게 됩니다.
그다음 2,3,4번째 branch의 경우에도 4개의 residual unit을 가지고 있습니다. 각각의 residual unit의 경우 3×3 컨볼루션, batch norm, ReLU 구성이 2개씩 짝을 지어져 있습니다. 마지막으로 해상도가 2배씩 줄어들게 될 경우 채널 수도 2배씩 늘어나게 됩니다.
Experiments
다음은 실험 파트입니다. 논문에서는 Human pose estimation, Semantic Segmentation, Object Detection의 결과를 보여주고 있는데, Human pose estimation과 object detection은 제 관심분야에서 잠시 떨어져있는 것들이라 간략하게 언급만 하고 넘어가겠습니다.
Human pose estimation
Human pose estimation은 사람의 각 관절마다 key point를 예측하는 분야로 논문에서는 해당 문제를 추정해야하는 관절의 총 개수 K개의 히트맵을 예측하는 문제로 풀었다고 합니다.
HRNetV1과 HRNetV2가 Pose estimation에서 성능은 둘다 유사해가지고 더 빠르게 동작하는 V1을 사용했다고 하며, 학습은 mean squared error를 통해 regression 형식으로 문제를 풀었다고 합니다.
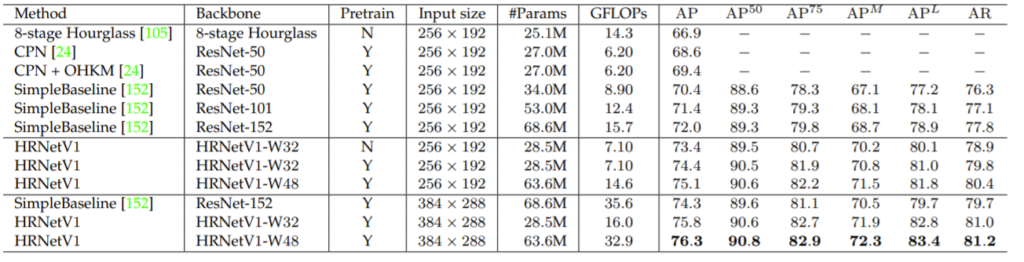
데이터 셋은 COCO human pose estimation 데이터 셋 중 validation dataset 사용했으며 평가 메트릭으로는 Object Keypoint Similarity(OKS)를 통한 average precision and recall score를 사용했습니다. 예를들어 AP50은 AP at OKS = 0.50이라는 의미라고 합니다.
다음은 COCO pose dataset 중 test dataset에서 평가한 결과입니다.
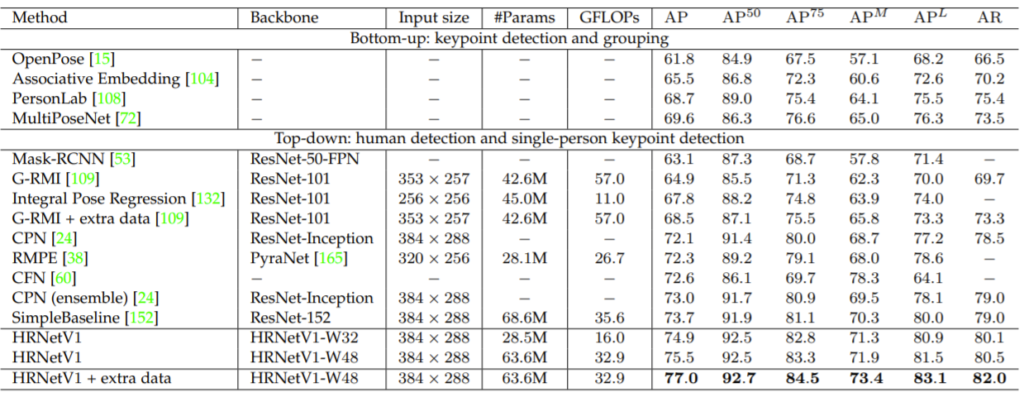
보시면 HRNet이 다른 방법론들과 비교하였을 때 학습 파라미터 수는 더 많긴하지만, 처리속도를 의미하는 GFLOPs에서 더 빠르며 성능 역시도 훨씬 좋은 것을 확인할 수 있습니다. 참고로 W48이 아닌 W32 모델의 경우 학습 파라미터와 속도가 2배 이상으로 빨라졌으면서 성능 역시 타 방법론보다 더 좋은 것을 확인할 수 있습니다.
다음은 정성적 결과입니다.

Object Detection
object detection에 사용한 데이터 셋 역시 MS COCO 2017 데이터 셋입니다. detection을 수행하기 위해서 그림5 (c)의 HRNetV2p를 사용했으며 정량적 결과는 다음과 같습니다.
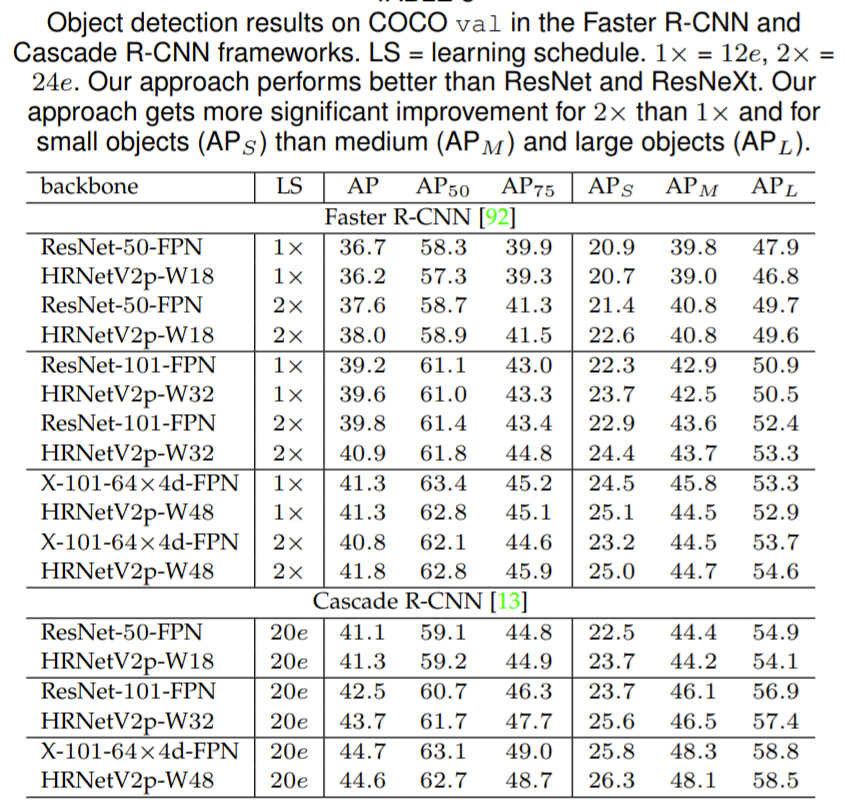
LS는 learning scheduler를 의미하며 비교 방법론으로는 ResNet, ResNeXt을 사용했으며 Faster RCNN, Cascade R-CNN 2개의 anchor based framework를 사용했습니다. 저자는 HRNet이 ResNet과 유사한 파라미터 수, 속도를 가지면서도 성능은 더 좋다고 주장합니다. 하지만 LS가 1x일 때 HRNetV2p-W18이 ResNet-50-FPN보다 성능이 밀리는 모습을 볼 수 있습니다. 이거에 대해서 저자는 최고 성능에 도달하기 위한 최적화 관련 파라미터 튜닝이 완벽하지 못했다는 식으로 이야기 하네요.
다음은 정성적 결과입니다.

Semantic Sgmentation
다음은 Segmentation 결과입니다. 데이터 셋으로는 CityScape, Pscal-Context, LIP dataset을 사용하였습니다. CityScape는 너무 유명하니 따로 설명은 필요 없을 듯 합니다. Pascal-Context는 학습과 평가용 데이터가 각각 약 5천장 정도를 가지고 있으며 label 종류는 59개 bg가 1개라고 합니다.
LIP데이터 셋은 약 5만장가까이 되는 데이터 셋으로 사람을 annotation 친 label을 함께 제공합니다.
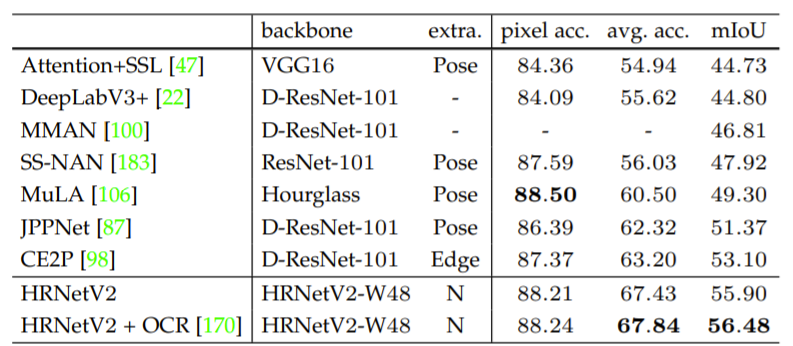
각 데이터셋의 정량적 결과는 다음과 같습니다.
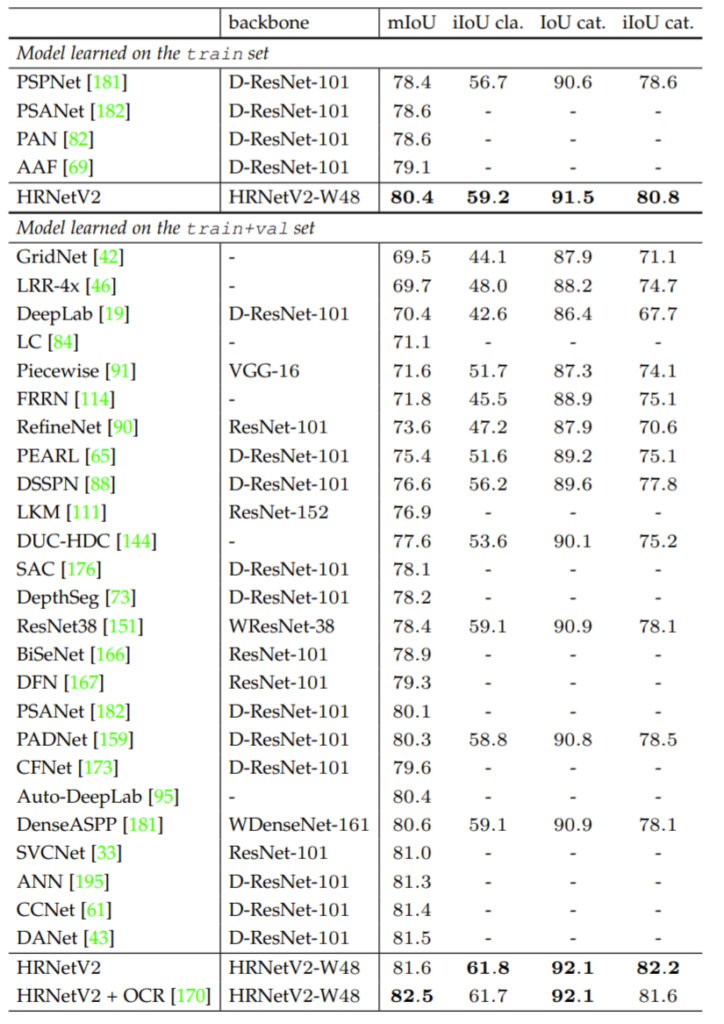
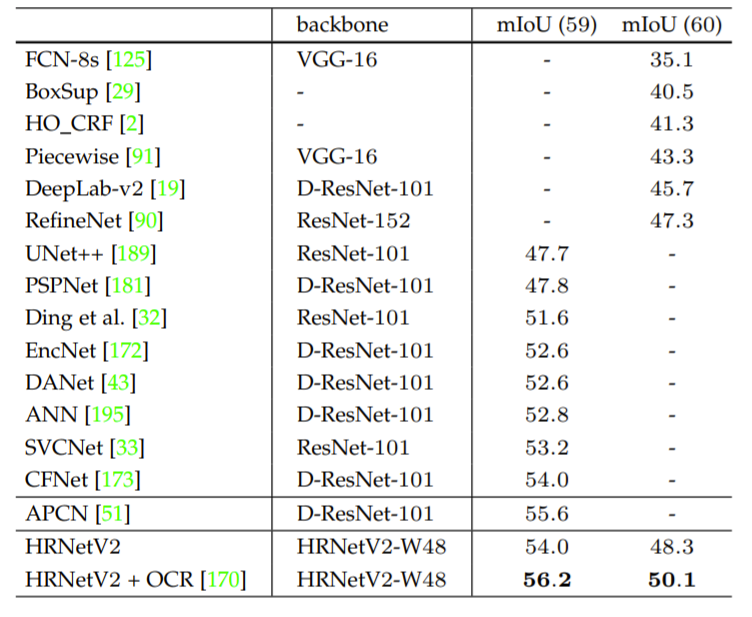
Semantic Segmentation의 정성적 결과는 아래와 같습니다.

결론
Transformer 관련 논문을 자주 읽다보니 백본 네트워크에 대한 관심이 무척 많아졌는데, 해당 논문은 제게 정말로 큰 충격을 준 논문이었습니다.. 저희에 일반적인 상식으로는 백본 네트워크에서 타고 나온 feature map은 반드시 점진적으로 down scaling이 되어야만 하기 때문이죠.
그렇지 않으면 당연히 많은 연산량이 필요로 하다보니, 속도가 너무 느려질게 뻔하다고 생각하였기에 그 누구도 HRNet과 같은 시도를 하려기 보다는, 대부분은 Encoder feature를 어떻게 Decoder에 전달해줄까 라는 생각만을 가지게 되었죠.
하지만 HRNet처럼 병렬적으로 각 scale의 feature map을 계속해서 살려서 디테일한 정보는 정보대로 다 가지고 속도는 속도대로 챙기는 것이 참으로 허허합니다. 생각보다 시간이 오래 걸릴 줄 알았는데 ResNet과 유사하거나 그 이상으로 빠르다고 하니 왜인지 궁금하더군요.
논문에서는 우리 네트워크가 왜 빠르다! 라고 하는지에 대해서는 미처 못본거같은데, 제가 생각하기엔 어처피 Encoder-Decoder 구조를 사용하는것이 Encoder 그 자체가 Decoder인 HRNet과 유사한 레이어 개수 및 연산량을 가져서 그런게 아닐까 싶네요.
아무튼 해당 논문이 너무나 매력적이어서 지금쓰고 있는 논문이 마치면 이후 연구에서는 HRNet을 기반으로 Depth나 Image Translation과 같이 Dense level prediction을 해볼까 합니다.
리뷰 잘 읽었습니다. 정말 일반적으로 알고 있던 사실과 반대되는 놀라운 내용이네요. 게다가 속도까지 빠르다니… 당연히 안될 것 같은 것도 시도해봐야 한다는 교훈이 있는 논문이네요.