이번 논문은 이전의 쓴 BSN이라는 논문의 후속 논문으로 나온 논문입니다. 역시 비디오에서 액션의 유무와 위치를 알아내는 것에 관련된 내용이고 기호가 여전히 많습니다. 그럼 시작하겠습니다.
1. Introduction
Untrimmed long video에서 Temporal action detection은 object detecion과 매우 유사합니다. 그래서 이걸 object detection처럼 나눠보면 temporal action proposal generation과 action classification으로 분류 가능합니다. 하지만 detection performance가 매우 낮아서 최근의 방법론들은 이 문제를 해결하기 위해 도전 중이라고 합니다. 이 문제를 해결하는 것은 proposal generation을 어떻게 하는가와 연관이 있습니다. 많은 방법론들이 top-down 방식을 사용하지만, GT를 커버하는 유연한 예측 결과를 생성하기 어렵다는 단점이 있어 논문 저자는 전작인 BSN 에서부터 bottom-up 방식을 적용해오고 있습니다. 하지만 이 BSN도 bottom-up과는 약간 맞지 않는 부분이 있어 Boundary-Matching 방법론을 적용한 BMN을 소개한다고 합니다.
2. Out Approach
2.1. Problem Formulation
역시 시작하기 전에 문제 정의부터 시작합니다.
X = \{x_n\}^{l_v}_{n=1} ( X = Untrimmed Video, l_v = frames, x_n = n-th RGB frame )
일단 우리가 untrimmed video에 대한 비디오 검색을 수행할 예정이므로 이에 대한 정의를 수행합니다.
Ψ_g = \{ϕ_n = (t_{s,n}, t_{e,n})\}^{N_g}{n=1} ( Ψ_g = X에 대한 temporal annotation set, N_g = GT action 객체의 갯수, t{s,n}, t_{e,n} = action instance ϕ_n에 대한 시작 시간과 종료 시간 )
그리고 action instance set도 위와 같이 정의해줍니다. temporal action detection과는 다르게 proposal 생성시에 액션의 카테고리는 고려되지 않고, inference 할때는 Ψg를 커버하는 Ψp를 만드는데 쓰인다고 합니다.
2.2. Feature Encoding.
새로운 방법을 사용하지는 않고 이미 널리 쓰이고 있는 “Two-stream convolutional networks for action recognition in videos.”라는 방법론을 가져와서 적용했습니다.
F = \{f_{t_n}\}^{l_f}_{n=1} ∈ R^{C×l_f} ( F = visual feature sequence of video X, l_f = 비디오 길이, C = dimension of feature )
전작과 동일하게 모든 frame에 대한 feature를 뽑지 않고, interval σ를 두기 때문에, 실제로는 l_f = l_v / σ 입니다.
2.3. Boundary-Matching Mechanism
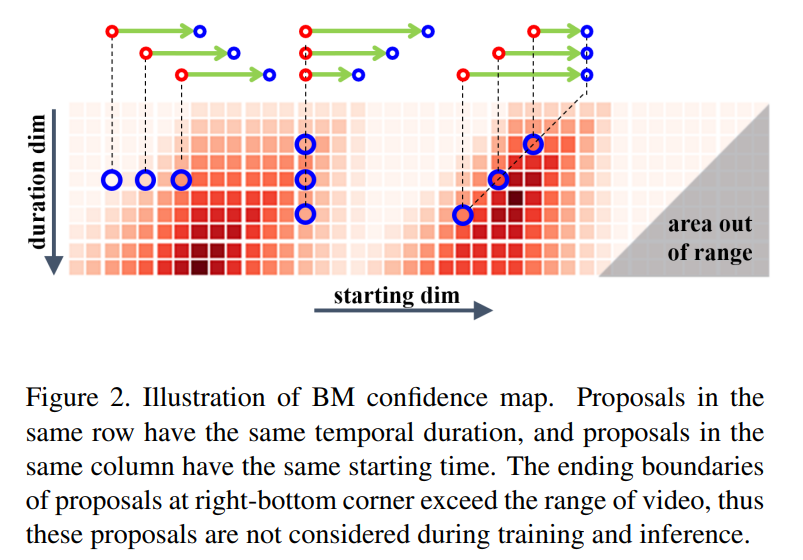
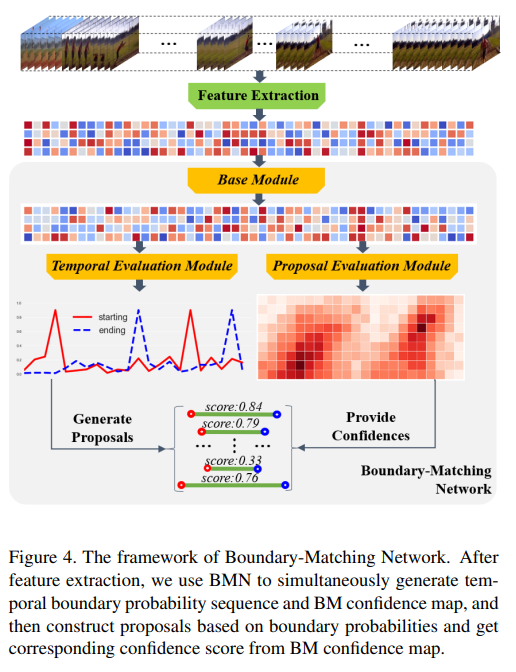
해당 부분에서 논문에서 중점적으로 이야기하는 BM 메커니즘을 설명합니다. 그림에서 보는 것과 같이 시작점과 끝점을 기준 구간을 만드는데 이를 temporal proposal ϕ를 matching pair로 만들고, 이것을 BM confidence map(M_c)으로 생성합니다. 여기서 M_c(i,j) = ϕ_{i,j}인데, 여기서 starting boundary t_s = t_j이고, duration d = t_i 그리고 ending boundary t_e = t_j + t_i이라고 합니다. 그래서 BM confidence map을 생성함으로서 조밀하고 분산된 제안을 위한 confidence score를 생성할 수 있다고 합니다.
Boundary-Matching Layer.
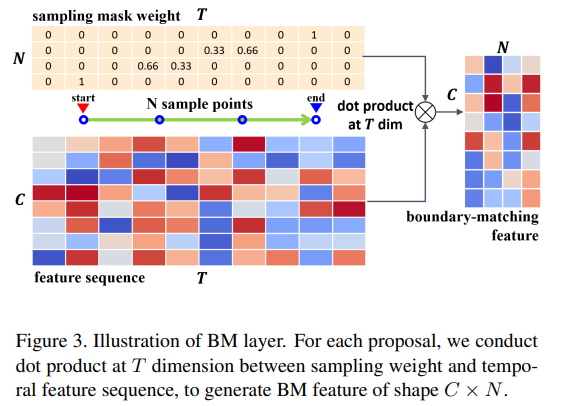
이제 BM confidence map을 생성하는 것은 알겠는데, 생성 방법에 관한 내용은 이 부분에서 등장합니다. 여기서 설명하는 BM confidence map은 뒤의 PEM에서 씁니다. 일단 위의 그림과 같이 temporal feature sequence S_F ∈ R^{C×T}로 부터 BM feature map M_F ∈ R^{C×N×D×T} 을 만듭니다. 이 과정에서 행렬곱이 사용되고, 그림에서 sampling mask weight라는 것도 사용하는데요.
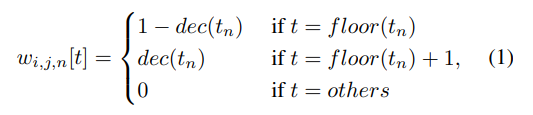
이 과정을 통해 proposal ϕ_{i,j}가 상응하는 weight를 가질 수 있다고 합니다. 그리고 이것은 feature sampling을 하는 과정에서 생기는 문제점을 해결하기 위해 고안한 방법이라고 합니다. 그러면 이 weight와 temporal feature sequence를 확장해서 BM confidence map의 모든 proposal에 대해 W ∈ R^{N×T×D×T}를 얻을 수 있습니다. 여기서 행렬곱을 사용하면, 위에서 말한 것 처럼 BM feature map을 만들 수 있습니다. 그런 다음 M_F에 Convolution layer를 태우면 M_C ∈ R^{D×T}가 만들어집니다. (D는 미리 정의된 proposal의 최대 길이) 이 과정은 보다 풍부한 컨텍스트를 담은 proposal을 만들기 위해 수행된다고 합니다.
Boundary-Matching Label.
여기서 또 새로운 BM label map이라는 것이 등장합니다. 모든 GT 객체와 ϕ_{i,j}에 대한 maximum IoU를 나타내는 g^c_{i,j} ∈ [0,1]인 BM label map을 G_c ∈ R^{D*T}와 같이 정의합니다. (shape는 M_c와 동일함) BM label map을 사용하는 이유를 요약하면 BM confidence map M_c를 생성할 때 이 G_c를 이용한다고 한다고 합니다.
2.4. Boundary-Matching Network
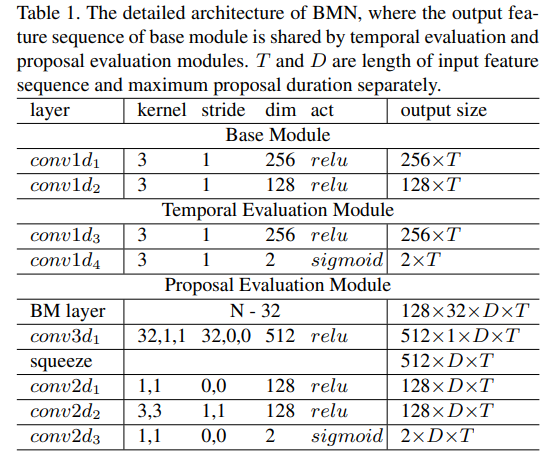
논문 저자의 전 논문인 BSN에서는 stage가 여러개였는데, 이번 BMN에서는 한번에 학습 가능한 통합된 프레임워크로 만들어졌다고 합니다. 자세한 구조는 위의 표에서 확인할 수 있고, 이번 프레임워크는 3가지 모듈로 나눠집니다.
- Base Module
- Temporal Evaluation Module (TEM)
- Proposal Evaluation Module (PEM)
Base Module은 백본처럼 작동한다고 합니다. receptive field를 확장시키고, TEM과 PEM에 feature sequence를 주기 위해 있는 모듈입니다. 그리고 나머지 두 모듈의 이름이 익숙한데, TEM과 PEM은 이전 논문에서 나왔던 내용입니다. TEM은 이전 논문이랑 동일한 것 같은데, 역시 시작점과 끝점의 확률이 계산되는 모듈입니다. PEM은 약간 다른데 이전 논문에서는 confidence score를 학습해서 반환하는 것이 목표였다면, 이번 논문에서는 BM confidence map M_{CC}와 M_{CR}를 학습하는게 목표입니다. 참고로 CC는 binary classification, CR은 regression loss function 학습에 쓰입니다.
3. Experiments
이전 논문과 동일하게 데이터셋은 ActivityNet-1.3, THUMOS14을 사용했습니다.
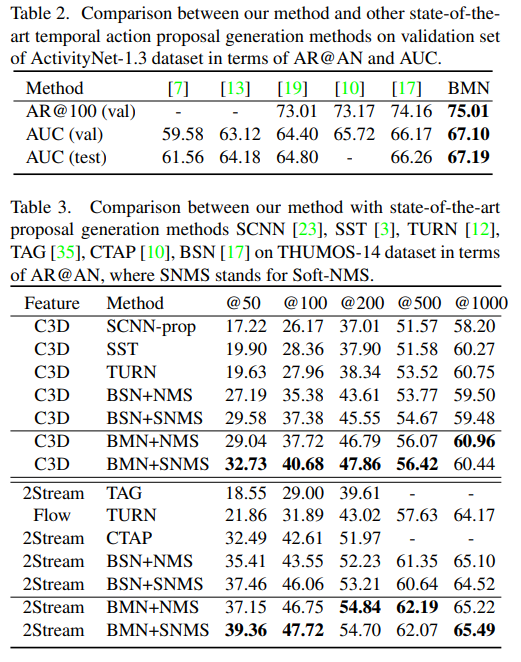
ActivityNet에서는 기존의 방법론들 보다 약간 더 좋은 성능으로 SOTA를 달성하였고, THUMOS14에서는 전반적으로 좋은 성능을 보여주고 있습니다. 특이한 점으로는 서로 다른 feature 추출 방법을 사용해도, NMS를 다른 방식으로 적용해도 성능이 여전히 좋습니다. 이러한 BMN의 아키텍쳐 자체가 좋아서 그렇다고 논문 저자는 밝히고 있습니다. 그리고 action instance의 98%를 커버할 수 있는 D(Boundary-Matching Layer에서 설정해야하는 값)를 64로 설정해줬는데, 이건 미리 분석을 하고 설정해준 것 같습니다.
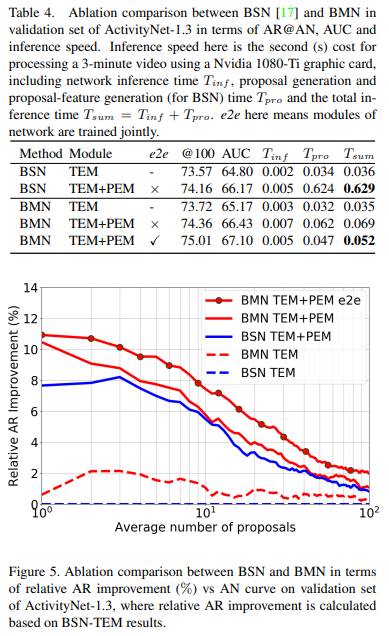
논문 저자의 이전 논문인 BSN과의 비교 실험도 있습니다. 이 부분은 새로 제안한 BM 방법론의 효용성을 보이기 위해 넣었다고 합니다. 실험 결과를 보면, TEM과 PEM을 함께 학습하는 새로운 구조가 더 좋은 성능을 보이는 것을 입증한 것 같습니다.
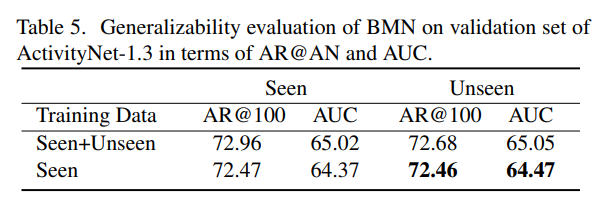
또한, BMN에서는 모델이 학습하지 않은 상황에 대해서도 잘 탐지한다는 실험 결과도 있습니다.
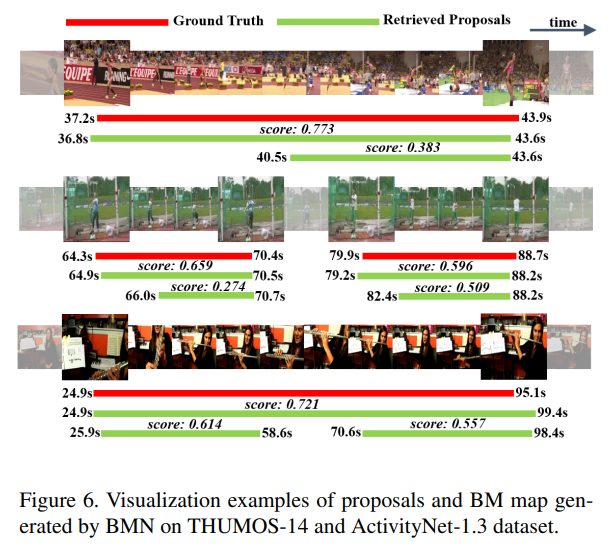
마지막은 실제 탐지 예시입니다.