안녕하세요. 이번 주 X-review에서는 object detection 논문 중에 end-to-end learning을 가능하게 하는 요소가 무엇인지에 대해 분석한 논문에 대해서 소개해드리겠습니다.
해당 논문은 one-to-one 기반의 방법론들과 one-to-many + NMS기반의 방법론들의 차이를 이해하는데 도움을 주었습니다.
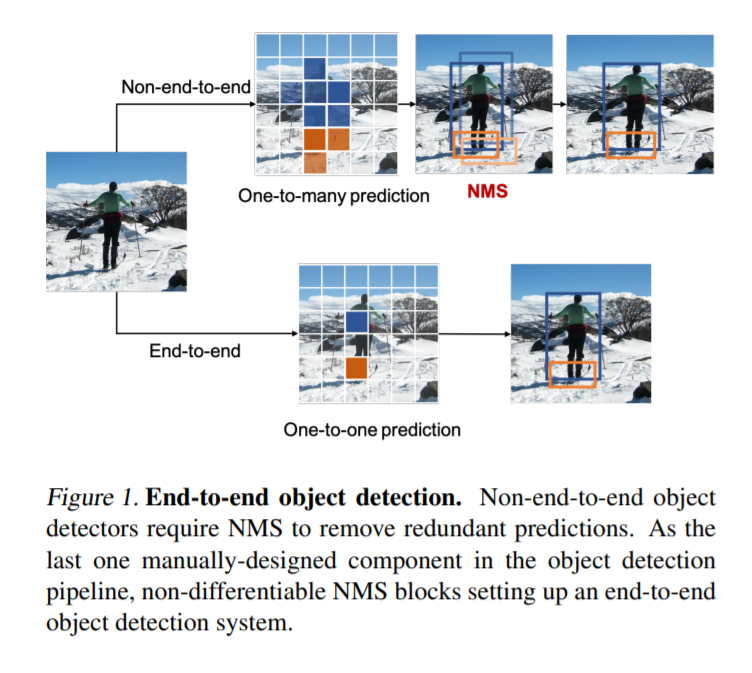
먼저 one-to-many 와 one-to-one의 차이를 아셔야하는데. 위의 그림이 그를 잘 설명해줍니다. 일반적으로 저희가 잘 알고있는 SSD와 YOLO같은 경우에는 one-to-many에 해당합니다. 즉, 앵커박스를 치고, 해당 앵커박스와 GT와의 오버랩을 기준으로 positive 박스들을 예측하게되는데 이때, positive box는 각 object마다 여러개가 나오게 됩니다. 즉 한개의 object에 many개의 box를 예측하므로 one-to-many라고 불리게 됩니다.
이와는 반대로 위의그림에서 one-to-one prediction을 보시면 object별로 positive sample을 한개만 추출하게 됩니다. Positive sample이 한개이기 때문에 NMS를 별도로 할 필요가 없으며, 이는 모델만으로 모든 것을 처리하는 end-to-end manner로 추론이 가능합니다.
다음으로는 해당 논문에서 공개한 깃허브에서 가지고온 사진입니다.
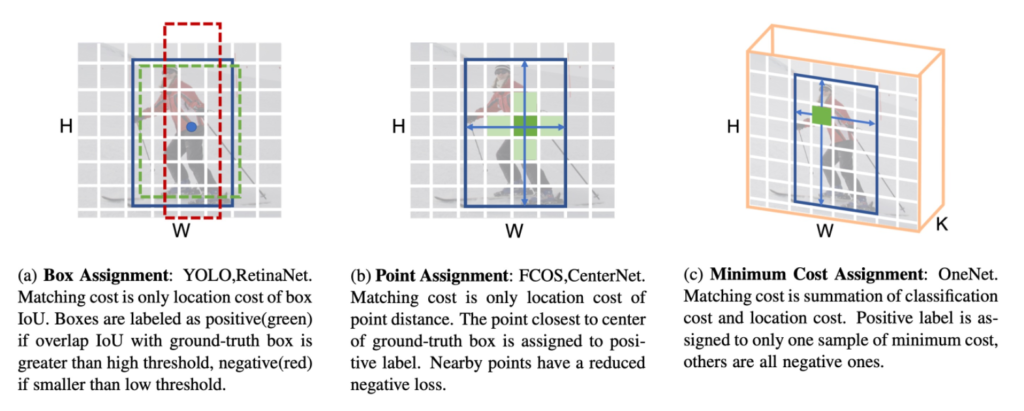
맨 왼쪽에 Box Assignment 같은 경우에는 우리가 흔히 알고있는 앵커박스를 이용하여 GT와의 IoU를 계산하고, 일정한 threshold를 기준으로 positive, negative로 나눈 후 NMS처리를 하는 그러한 경우입니다.
가운데 Point Assignment는 기존에 box를 기준으로 detection을 수행했던것을 reference point를 기반으로 수행하는 것을 의미합니다. 이때, GT box의 centre point와 가장 가까운 point가 positive label로 할당됩니다. 다른말로하면, Matching cost를 location에 대해서만 고려하여 해당 matching cost가 가장 낮은 경우에 positive로 할당하고 나머지는 모두 negative가 됩니다.
C에서 Minimum cost assignment같은 경우에는 Matching cost에 classification term을 추가한 경우입니다. 기존의 localization cost만을 matching cost로 정의하여 사용하는 방법들과는 다르게 classification cost+localization cost를 matching cost로 사용하여 positive sample을 할당합니다.
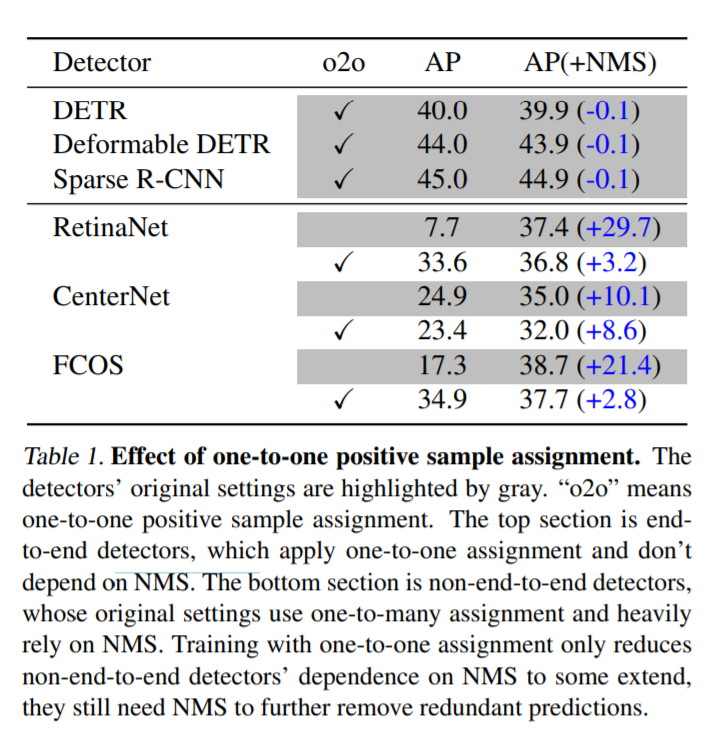
그렇다면 NMS에 의존적이지 않은 One-to-one prediction기반이 성능이 더 좋을까요? 위의 표에서는 이를 보여줍니다. 해당 표에서 위의 3개의 방법론은 one-to-one 기반의 방법론이고, 아래는 one-to-many assignment 기반의 방법론입니다.
(용어가 헷갈리실거 같아서 잠시 정리하고 넘어가겠습니다. one-to-many는 non-ene-to-end이고, one-to-many는 end-to-end입니다.)
아래의 one-to-many 방법론들을 one-to-one기반으로 학습하였을때에 일반적으로 성능향상이 있었습니다. 그러나 항상그런것만은 아닙니다. 그렇다면 과연 어떠한 요소들이 one-to-one assignment를 가능하게 할까요? 즉, end-to-end로 모델을 사용할 수 있을까요? 이러한 것에 대한 분석이 해당 페이퍼에서 다루는 주된 내용입니다.
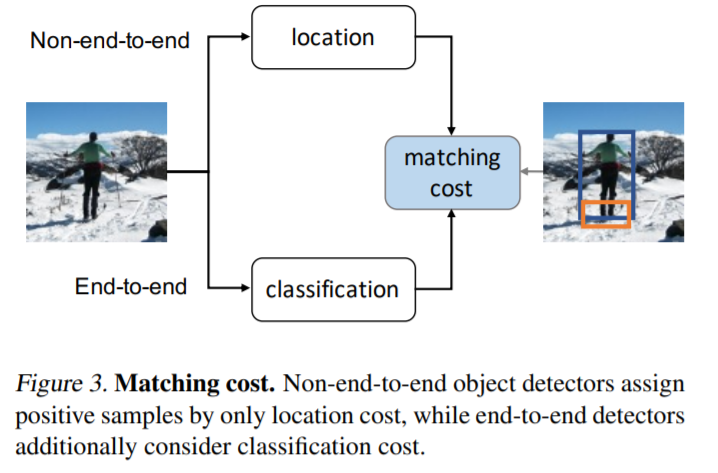
one-to-one prediction 기반의 방법론들이 최초에 나왔을때, 대부분이 location에 대한 loss를 matching cost로 사용하였습니다. 이게 무슨말이냐면, location에 대한 error만을 고려하여 positive sample을 할당하였다는 소리입니다. 즉, GT box가 있으면 GT박스에서 reference point를 추출하고, 해당 reference point와의 거리를 이용하여 matching cost를 산정하였습니다. 이렇게 거리만을 산정하였기때문에 location만을 고려하였다고 언급한 것 입니다.
이러나 이러한 방식보다는 classification cost까지 고려하여 matching cost를 정하는게 “score gap”을 늘릴 수 있다고 저자는 주장합니다. 여기서 말하는 score gap이라는 컨셉은 해당 논문에서 소개하는 용어로써 positive sample과 negative sample간의 matching cost 차이를 의미합니다.
이러한 score gap에 대한 이해가 바로 해당 페이퍼에서 주장하는바를 이해하는데 핵심이 됩니다.
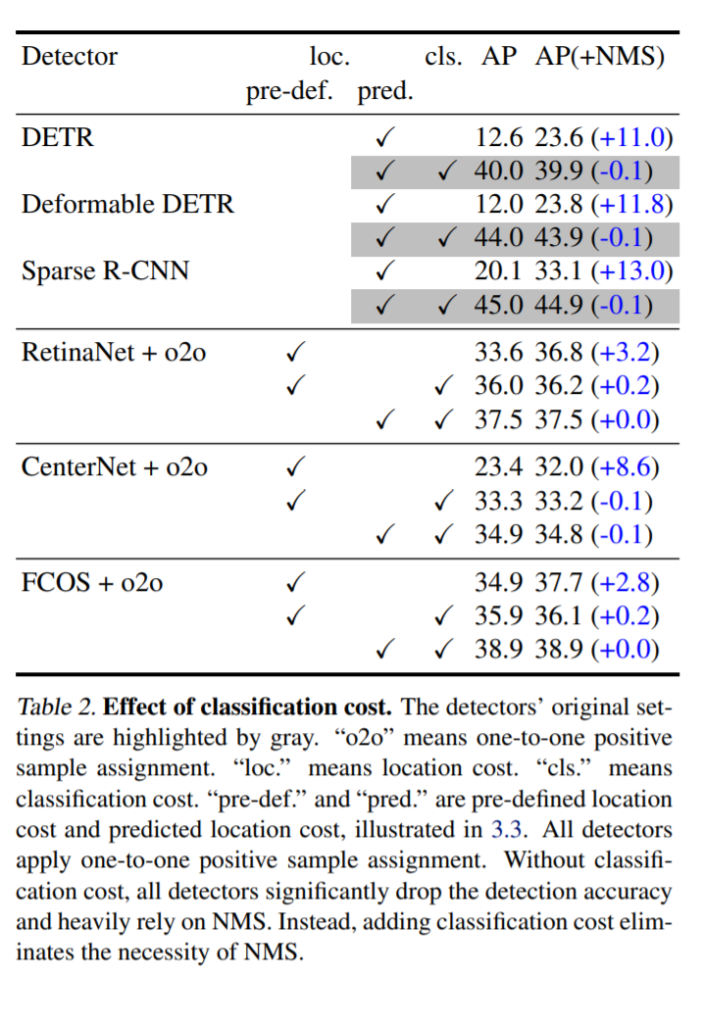
저자는 classification loss를 matching cost에 추가하면 score gap을 증가시킬 수 있고, score gap이 크면 성능이 올라간다고 말하고 있습니다. 그리고 그를 위의 실험에서 보여줍니다. classification loss를 matching cost에 포함했을때 AP 기준 성능이 많이 올라간것을 알 수 있습니다.
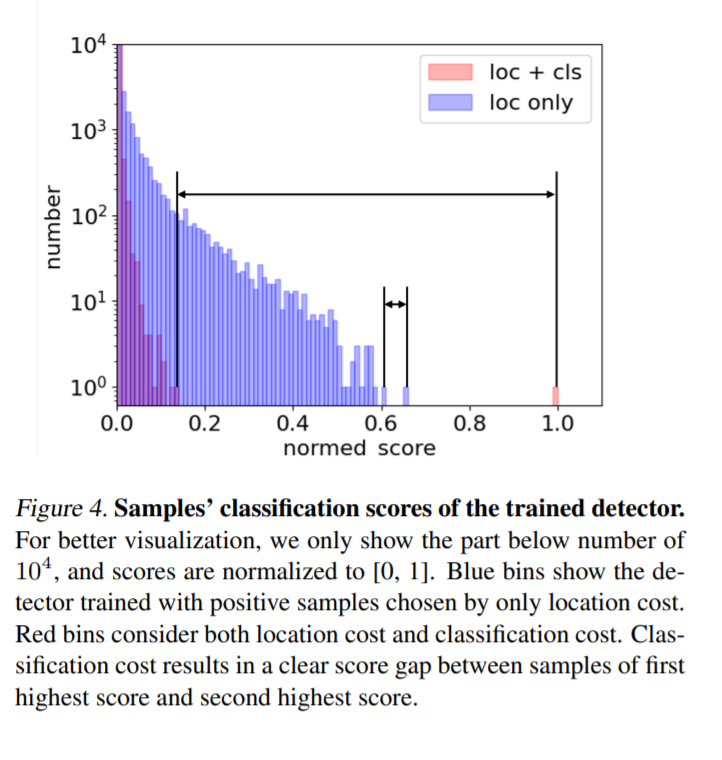
또한 위의 그래프에서 처럼 score gap을 visualization 하여 보여줍니다. loc만을 사용했을때와 cls를 추가했을때의 score gap차이가 normalized 된 차원에서 plot되어 있습니다. loc만을 썻을때 보다 cls를 추가햇을때 눈으로보기에도 10배이상은 차이가 나보이네요. 이렇게 score gap차이가 난다는 것은 positive sample과 negative sample간의 차이가 많이 난다는 것으로 discriminative 한 sample들을 얻는데 효율적이며, 이는 성능 향상을 불러옵니다.
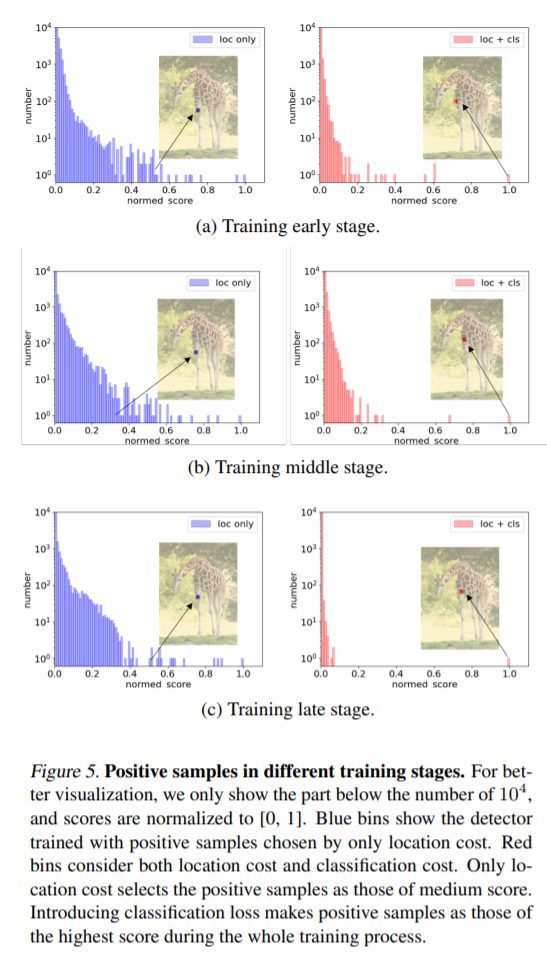
이러한 경향성은 학습이 진행될수록 더 커집니다. 위의 그림에서 보시면 Training late stage에서는 score gap이 엄청 커진 것을 알 수 있습니다.

그리고 또하나 이야기 하는게 이렇게 score gap차이가 커지면 실제로 prediction point를 visualization 하였을때도 차이를 보인다는 것 입니다. loc loss만을 matching cost로 사용하였을때는 prediction point가 background로 나오는 경우가 많았는데, cls를 추가하였더니 그런 경우가 감소하고 기린의 목이라던가 특징이 될만한 곳으로 prediction이 되었습니다.
즉, prediction point들이 해당 object의 특징이 될만한 곳으로 잘 나타내어진것을 알 수 있었습니다.
요약하자면 해당 논문에서는 object detection에서 one-to-many // one-to-one 기반의 방법론들의 차이를 다루었고, one-to-one기반의 방법론들에서 matching cost에 classification loss를 추가함에 따라 positive sample과 negative sample간의 score gap이 생긴다고 말하였습니다. 그리고 이러한 차이가 있어야 one-to-one prediction이 가능하다고 말하였습니다. 즉, one-to-one prediction이 가능하다는 것은 NMS에 의존적이지 않고 end-to-end로 모델을 사용할 수 있다는 의미입니다.
이상 리뷰 마치겠습니다. 질문은 코멘트해주세요.
리뷰 잘 읽었습니다.
한가지 질문이 있는데 One to One 방법론들은 Anchor free 기반의 detection 방법론을 의미하나요?
네 맞습니다. 100% 라고 말하기엔 항상 반례가 있을수있다고 생각하지만, 일반적으로는 제가아는선에서는 맞습니다.
이번 CVPR2021에 비슷한 논문을 봤습니다. 기회가 된다면 해당 논문도 함께 리뷰해주시면 해당 분야의 최신 흐름을 이해하는데 도움이 될 것 같습니다.
https://arxiv.org/abs/2012.03544
http://server.rcv.sejong.ac.kr:8080/2021/06/27/cvpr-2021-end-to-end-object-detection-with-fully-convolutional-network/
ㅇㅅㅇ
상당히 흥미로운 논문이라 재미있게 읽었습니다,
만약 논문 이야기 대로라면 o2o?를 적용하게 된다면 속도도 개선될 것 같은데
추론 속도 혹은 계산 복잡도에 대한 내용은 없었나요?