오랜만에 depth estimation과 관련된 논문을 리뷰해보았습니다.
명시적으로 left-right consistency를 활용하는 손실 함수를 통해 단일 이미지 깊이 예측에서 당시의 SOTA를 넘어설 수 있었습니다. 또한 예측 오류를 줄일 수 있는 LiDAR GT의 올바른 사용법을 설명하였습니다.
Introduction
단일 이미지에서의 supervised 방식은 LiDAR의 실측 데이터를 사용하며 이러한 데이터를 이용하기 위해서는 시간과 비용이 많이 듭니다. 또한 sparse한 정보를 가지며 일반적으로 카메라와 동일한 시야를 공유하지 않아 지도학습 방식으로는 이미지와 겹치지 않는 영역에서의 깊이 추정이 어렵다는 문제가 있습니다.또한 비지도학습은 stereo view에서 reconstruction 원리를 이용하므로 전체 이미지에 대한 깊이 추정을 할 수 있으나 정확도가 stereo의 reconstruction에 의해 제한적이라는 문제가 있습니다.
이 논문에서는 semi-supervised 방식을 이용하여 단일 이미지의 depth 예측에서 당시의 SOTA를 넘겼습니다. 기존에 사용되던 left-right consistency라는 용어를 사용하여 새로운 준지도 loss를 제안하였습니다. 지도학습에서는 LiDAR 데이터를 이용하고 비지도학습에서는 stereo 이미지를 이용하여 학습을 한 뒤 test 단계에서는 단일 이미지를 이용하였습니다. 또한 해당 논문의 모델에 projected raw LiDAR 정보를 사용한 경우와 주석이 달린 depth map을 사용한 경우에 어떤 영향이 있는 지에 대해서도 연구를 하였고 projected raw LiDAR 데이터를 이용할 때 LiDAR와 카메라의 변위에 의한 노이즈한 artifact들에 의해서 성능이 저하되는 것을 확인하였습니다.
Contribution
- 준지도 학습 단일 이미지 예측에서 손실 함수에 left-right consistency term를 사용하는 것의 중요성을 보임
- LiDAR로부터 annotation을 진행하여 얻은 정보를 사용하는 것이 raw LiDAR 데이터를 이용하는 것 보다 좋은 정확도를 얻을 수 있음을 경험적으로 제시
- 인기 있던 Monodepth architecture를 기반으로 한 준지도 학습 네트워크 제안
Method
Monodepth1의 방식은 비지도 학습시 rectified된 stereo 이미지만을 사용하지만 본 논문은 추가적인 실측 데이터를 이용하여 학습을 진행하였습니다.
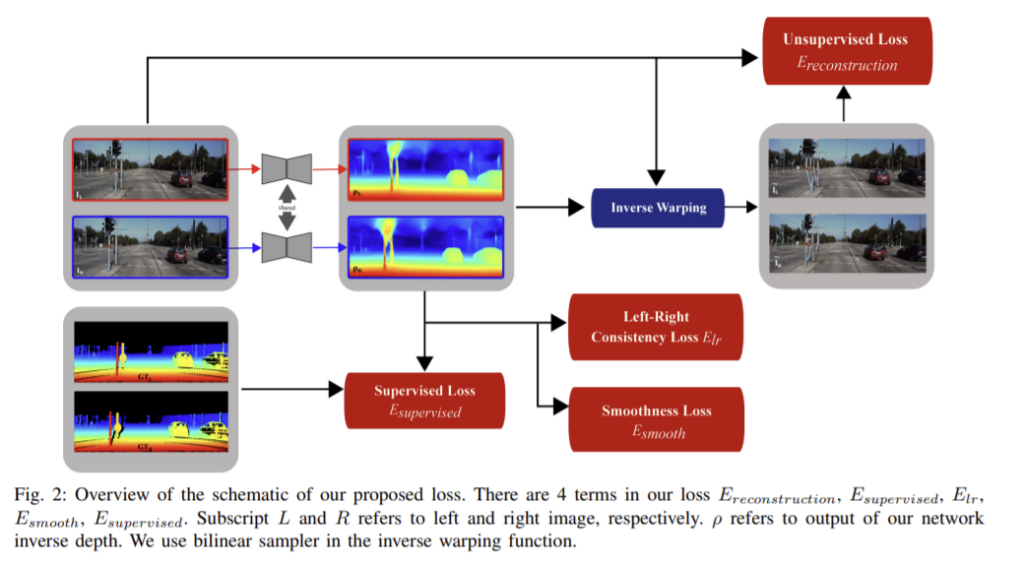
Loss Terms
monodepth1과 유사하게 L_{s}는 출력 결과의 크기 s에 따른 loss로 다음과 같이 정의된다.

1) Unsupervised Loss _ E_{reconstruction}
양쪽 이미지 사이의 photometric reconstruction loss를 사용합니다. 다른 비지도 방법과 유사하게 두 이미지 사이의 광도 일관성을 가정하고 inverse warping을 사용하여 추정된 이미지를 얻은 다음 추정된 이미지와 실제 이미지를 비교합니다. SSIM과 L1, ternary census를 조합하여 사용합니다. SSIM과 ternary census는 gamma와 조도 변화를 어느정도 보상할 수 있고 조도 일관성에 대한 가정을 강화할 수 있습니다.
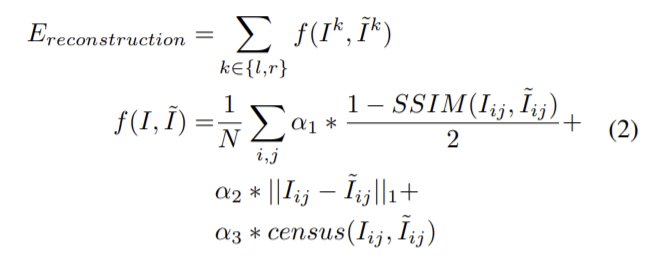
** census 관련
2) Left-Right Consistency Loss _ E_{lr}
좌우 이미지를 각각 독립적으로 네트워크에 넣어 출력된 depth map이 일관되도록 두 출력을 공동으로 최적화합니다. left 시야의 inverse depth가 right 시야의 projected inverse depth와 같도록 만들고자 하고 이러한 loss는 optical flow예측을 위한 전후 이미지의 일관성과 유사하며 다음과 같이 정의됩니다.
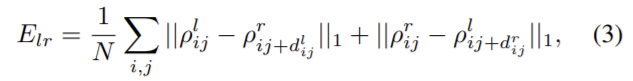
** 기존 방식의 left-right consistency loss는 아래의 식으로, 대칭적으로 left, right을 모두 비교하지 않았습니다.
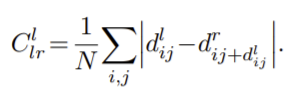
3) Supervised Loss _ E_{supervised}
GT를 사용할 수 있는 점 Ω에서의 inverse depth Z^{-1}와 예측 inverse depth의 차이를 이용하여 loss를 구하고 다음 식으로 표현할 수 있습니다.
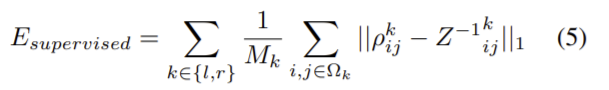
4) Smoothness Loss _ E_{smooth}
smoothness loss는 정규화 term으로 다음과 같이 정의됩니다.
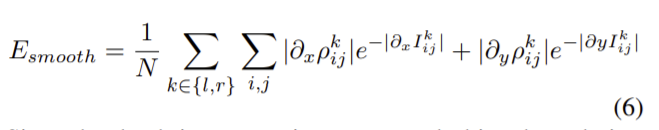
Experiments
LiDAR와 카메라 센서 사이의 변위 때문에 noisy 아티팩트가 생깁니다. KITTI 에서 제공한 사전의 처리 단계를 거쳐 annotation 된 depth map은 left-right의 일관성을 확인하여 outlier를 제거하고 projected raw LiDAR 정보를 밀도있도록 한 것으로 Fig. 3을 통해 차이를 확인할 수 있습니다.

annotated depth map을 이용하여 성능을 확인해보았다.
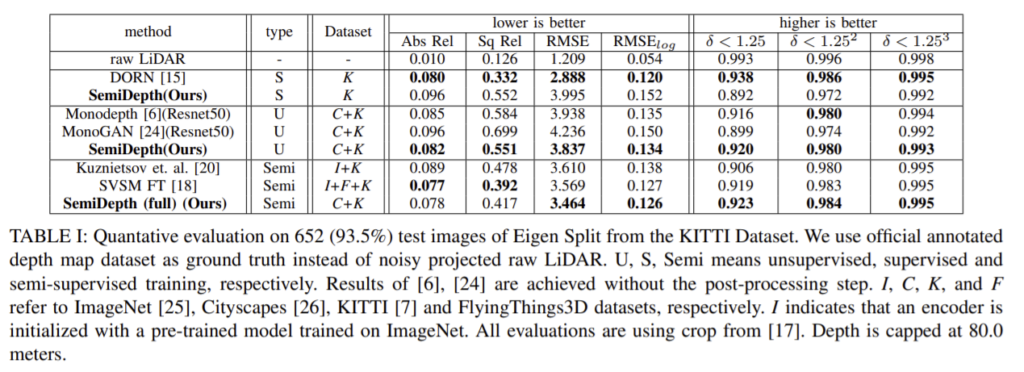
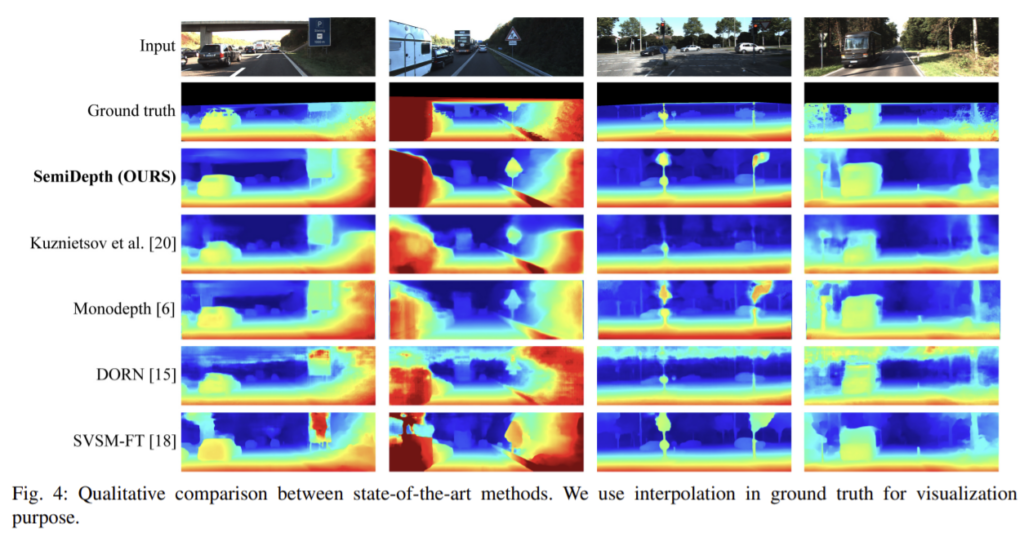
left-right consistency loss와 annotation depth map사용의 효과를 확인하기 위한 실험의 정량적 결과입니다. 2행과 3행을 통해 left-right consistency loss의 효과를, 1행과 3행을 통해 annotation depth map을 이용하는 것의 효과를 확인할 수 있습니다.
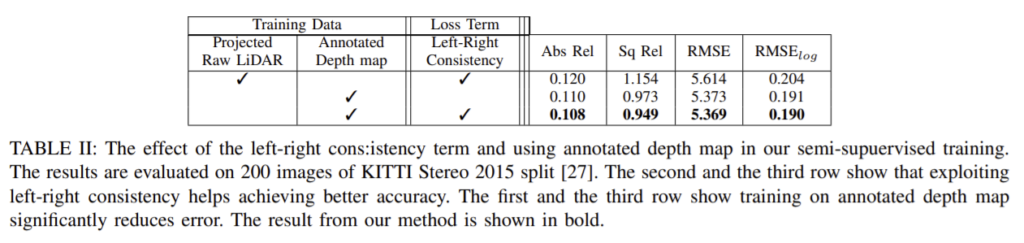
monodepth1과 비교했을 때 차이가 loss term에 한쪽 방향이 아닌 양 방향에서의 loss를 같이 계산하는 것이 효과적이라는 것 과 데이터를 annoteted depth map을 이용하였을 때 효과적이라는 내용이 핵심인 데 loss를 제안했다기보다도 조금 보완한 느낌이고 양쪽을 같이 본 이유에 대한 설명이 부족한 것 같아서 아쉬웠습니다…