

이번에 리뷰할 논문은 ECCV 2018에 나온 Find and Focus라는 논문입니다. Paragraph-to-Video Retrieval에 대해 다루는 논문이지만 현재 준비 중인 저희 논문의 컨셉과 유사한 부분이 있어 리뷰를 하게 되었습니다. 이 논문 전 방법론들은 주로 비디오 전체를 embedding하여 사용하기에 제약된 표현럭을 지닌 단점이 존재했습니다. 본 논문은 이를 two stage로 나누어 top-level에서 matching하고 part-level에서 refinement를 진행하는 방식으로 해결하고자 했습니다. 자세하게 어떤 식으로 구성되었는지는 이후 파트에서 설명드리겠습니다.
1. Method
1.1 Two-level Structured Formulation
잠깐 위에서 설명드린 바와 같이 본 논문이 풀고자 하는 문제의 분야는 Paragraph-to-Video Retrieval 입니다. Paragraph와 video는 서로 다른 도메인에 속하는 데이터입니다. Paragraph의 경우 언어적인 도메인에 포함되며 문장으로 구성되고, Video의 경우 시각적인 도메인에 포함되며 clip(혹은 snippet)으로 구성됩니다. 두 데이터는 비록 서로 다른 도메인이기는 하나 여러 유사한 특징을 지니고 있습니다. 두 데이터 모두 서브 데이터(문장 or clip)으로 특정한 event를 기술하며, 앞 뒤 서브데이터에서 temporal information을 얻을 수 있다는 점 입니다. 그리고 두 데이터는 서브 데이터 단위로 event를 기술하기 때문에 동일한 event를 가리키는 Paragraph와 Video가 있다면 같은 의미를 나타내는 문장과 clip이 각각 존재할 것 입니다. 본 저자는 이 문장과 clip 간의 연관관계, 즉 part-level의 관계를 사용해 Paragraph-to-Video Retrieval의 문제를 해결하고자 하였습니다.
1.2 Clip Localization
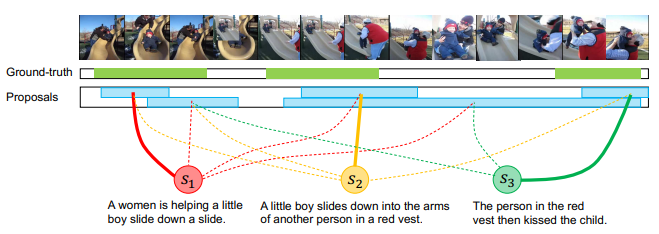
앞서 언급한 part-level의 관계는 clip localization으로 확인됩니다. Clip localization은 총 세 가지 과정으로 구성되며 결과적으로 두 데이터 간의 part-level similarity를 반환하게 됩니다.
- Feature extraction
우선 Paragraph의 경우 문장 단위로 feature를 추출하고 Video의 경우 clip 단위로 feature를 추출하게 됩니다. Clip의 경우 TSN기반의 two-stream network를 사용하며 문장도 비슷한 방식으로 추출한다고 합니다.(Bag of Words weighted with tf-idf) 그리고 각각 추출한 두 데이터의 feature들은 서로 다른 도메인이기때문에 서로 비교가 가능하도록 같은 도메인으로 projection시켜 줍니다. 어떤 방식으로 projection 시키는 지에 대한 자세한 언급이 되어 있지 않으나 흔하게 하는 방식으로 fc layer를 쌓지 않았을까 싶습니다.
- Clip proposal
그다음으로는 앞서 projection하여 공통된 도메인이된 문장에 대한 feature와 clip에 대한 feature를 활용해서 clip proposal을 생성합니다. Temporal Actionness Grouping 방식에서 아이디어를 얻었다고 하며, 만약 i번째 문장의 feature가 있을 때 이와 모든 clip feature의 코사인 유사도를 계산하여 연관성을 판단하게 됩니다. 만약 연관있다고 판단된 clip feature가 연속되어 있다면 grouping 하여 proposal이 생성되는 방식 입니다.
- Cross-domain Matching
앞서 구한 clip proposal내 clip feature와 문장에 대한 feature의 유사도를 계산하여 matching을 하는 과정입니다. 본 논문의 저자는 bipartite하게(양방향으로) one-by-one 비교를 하게되면 중간에 존재하는 노이즈로 인하여 잘못된 매칭결과로 이어지는 것을 확인하게 되었고, 이에 따라 보다 강인하게 작동할 수 있는 robust bipartite matching scheme 을 제안하였습니다. 이는 원래 clip proposal 내 clip feature와 문장에 대한 feature를 one-by-one으로 비교할 때 가중치를 주며 계산하는 방식으로, 가중치는 clip proposal 내의 모든 clip feature를 평균낸 proposal feature G와 문장에 대한 feature 간의 코사인 유사도로 계산되었습니다. 이와 같이 유사도를 계산하고 part-level의 association score로 선정하였습니다.
1.3 Overall Framework
앞선 방식으로 계산된 part-level association score를 모든 Paragraph와 Video 쌍 마다 계산을 하게 된다면, 만약 데이터 베이스가 클 경우 검색하는데 있어 오랜 시간이 걸리게 됩니다. 이를 해결하기 위해 part-level association score 보다는 정확하지는 않지만 검색 영역을 줄여 줄 수 있도록 top-level matching을 우선적으로 진행합니다.
- Find: Top-level Retrieval
두 데이터를 각각 embedding 시켜 한 비디오 당 하나의 feature, 한 Paragraph 당 하나의 feature를 생성합니다. 이처럼 embedding 시킬 때 각각 positive pair와 negative pair를 생성하여 triplet margin loss로 학습을 시키게 됩니다. 이후 feature 간의 유사도를 계산하여 top-level의 relevance를 계산하고 한 Paragraph 별로 K개의 유사한 Video를 반환합니다. 저자는 실험적으로 K가 작음에도 높은 recall을 보였다고 합니다. Recall이 높을 수록 데이터 셋에 존재하는 GT가 K 내에 많이 포함되어 있음을 나타냅니다. 고로 작은 K에도 충분히 GT가 포함되어 있기에 searching space를 줄이는데 도움이 되었다고 볼 수 있습니다.
- Focus: Part-level Refinement.
앞서 얻은 K개의 pair에서만 refinement를 진행합니다. 위에서 설명한 방식대로 part-level의 association score를 계산하고 video-level relevance score와 곱하여 final relevance score를 계산합니다. K 개의 pair에서 모두 계산 후 이 final relevance score에 따라 reranking을 하였다고 합니다.
2. Experiments
2.1 Whole Video Retrieval
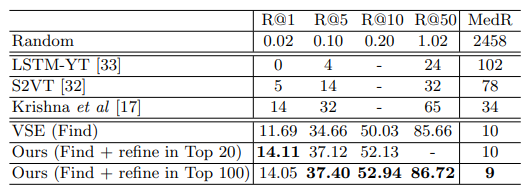
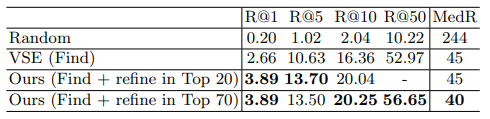
Table 1과 2는 각각 ActivityNet Captions 데이터 셋과 LSMDC 데이터 셋에서 제안된 Find and Focus framework의 성능을 나타냅니다. R@K는 전체 GT 수 대비 K rank안에 존재하는 GT 수를 의미하는 것으로 높을 수록 성능이 좋은 것을 의미하며, MedR은 전체 GT가 배치된 중간 rank의 위치를 나타내는 것으로 낮을 수록 성능이 좋은 것을 의미합니다. Find의 모델로 VSE라는 기존 제안된 모델이 사용되었는데 이 모델 만으로도 R@50의 성능이 높은 것을 보아 searching space를 줄이는데 도움을 준 것을 알 수 있으며 refinement까지 진행했을 때 Recall이 많이 올라간 것을 알 수 있습니다.
2.2 Proposal Generation and Clip Localization
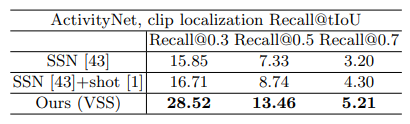
Table 3은 Clip localization 과정(VSS)에서 생성된 proposal에 대한 평가입니다. 2018년도에 제안된 논문이라 Temporal Action Proposal task에서 최근 유명한 여러 방법론들과는 비교하지 못한 듯 하나, Recall@tIoU 기준으로 가장 높은 성능을 보였습니다. Recall@tIoU는 GT segment와 proposal의 overlap이 tIoU 이상일 때 TP로 보고 Recall을 계산하는 방식 입니다.
3. Reference
[1] https://openaccess.thecvf.com/content_ECCV_2018/papers/Dian_SHAO_Find_and_Focus_ECCV_2018_paper.pdf