오늘 또한 깊이 추정 연구를 가져왔습니다. 하지만.. supervised를 곁들인.. ㅋㅋ
현재 supervised depth estimation은 성능이 거의 Lidar와 유사할 정도로 끌어올려졌는데요. 이제는 얼마나 사물과 배경의 윤곽을 깔끔하게 예측하였냐가 중점인 것 같습니다. 그러한 관점으로 봤을때 이 논문의 결과는 정말 대단한데요.
이 논문은 depth estimation통해 예측한 결과의 디테일을 거의 한계까지 끌어올렸다고 봐도 무방할 정도로 기가막힙니다. 아래 그림을 보면 조각상들과 관중들의 디테일이 엄청납니다.


이 논문에서 이렇게 디테일이 살아있는 영상을 만들기 위해서 아래 그림과 같이 입력영상을 다양 사이즈로 변경한 후 merge를 하였습니다. 물론 merge 한 방법이 이 논문의 특색이 되며, 입력영상을 다양하게 한 이유 또한 이 논문의 contribution 입니다.
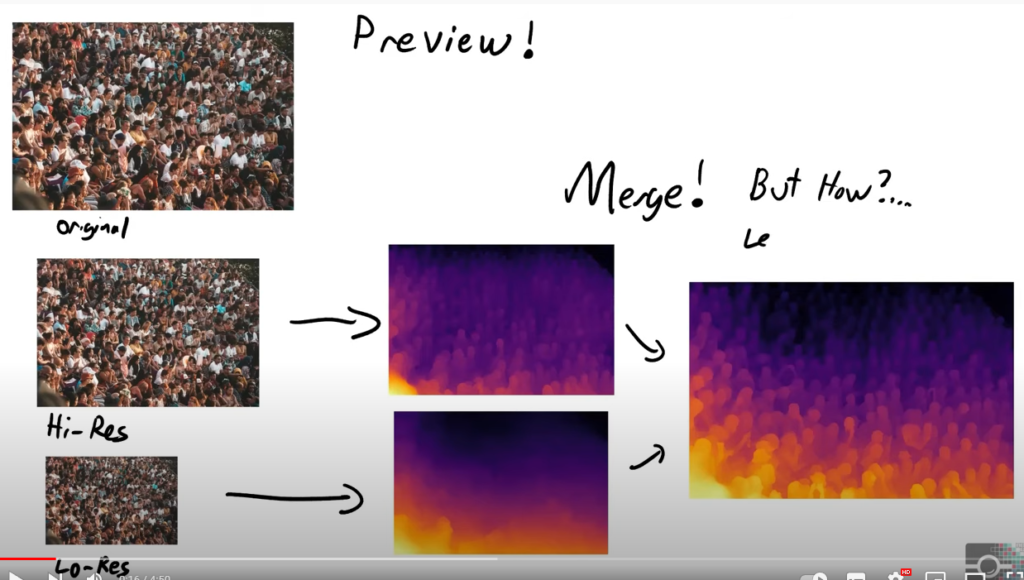
이 논문의 contribution은 다음과 같습니다.
- 입력 영상이 low와 high resolution 일때 scene structure와 detail의 trade-off 관계를 분석하고, 간단히 두 영상 사이즈를 병합하여 두 가지 요소를 모두 얻은 결과를 보였다.
- 다양한 영상 사이즈의 결과를 병합하기 위해서 영상 전체와 지역적인 부분을 합치는 방식을 제안합니다.
Method
추정된 깊이 영상이 갖춰야할 요소가 전체적인 구조에 대한 표현력과 물체에 대한 디테일을 꼽습니다. 이 논문에서 두 마리 토끼를 다 잡기 위해서 하나의 가정을 가지고 증명을 합니다. 그 가정이란, 영상의 사이즈가 작아지면 전체적인 구조에 대한 표현력이 좋아지고 영상의 사이즈가 커지면 물체의 디테일이 살아난다입니다. 그것을 증명하기 위해서 실험적으로 보이는데요. 아래와 같습니다.
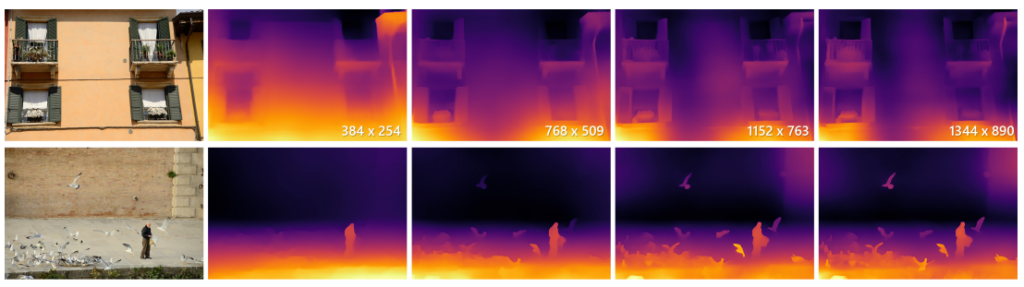
위 사진은 영상 사이즈를 점점 키워가면서 예측했을때 결과 입니다. 먼저 위 창문을 보면 영상이 제일 클때 창문의 texture 혹은 디테일이 잘 살아 있는 것을 볼 수 있으며 그에 반해 다 동일해야할 견물 외벽의 깊이가 다른 것을 볼 수 있습니다. 하지만 영상의 사이즈가 작을 땐 창문의 디테일은 적지만 외벽의 데테일은 잘 살아 있는걳을 볼 수 있으며, 아래 사진 또한 영상의 사이즈가 클땐 새의 디테일이 살고 도로가 울통불퉁하고 뒤의 벽이 잘 예측이 안되고 영상 사이즈가 작을땐 반대인 것을 볼 수 있습니다.

세부적으로 좀 더 판단해보면, 영상 사이즈가 작을때는 칠판을 하나의 물체처럼 깊이를 예측한 반면 사이즈가 클때는 그렇지 못한 것을 볼 수 있습니다.

위 그림을 보면 확실히 작은 사이즈일때 구조를 살리고 영상이 커지면 texture및 디테일이 산다는 게 눈에 보일 겁니다.
이렇듯 영상 사이즈마다 각각의 장점이 있으며 이 장점을 살리기 위해서 이 논문에서는 아래와 그림 같은 순서로 각 사이즈이 깊이 영상을 병합했습니다.

- (b)와같이 영상 사이즈에 따른 깊이 영상을 추정 한다. 이때 추정기는 MiDAS를 사용
- 그런 다음 (c)와 같이 각 사이즈 별로 patch를 추정한 후 각 patch 별로 깊이 값을 남김.
- 각 patch를 잘 조합한 후 병합하여 최종 영상을 예측.
간단하게 흐름을 설명하면 위 순서와 같다. 그럼 좀더 자세히 설명하도록 하겠습니다.
Patch는 분석을 통해서 receptive field의 최대치 사이즈로 하는 것이 물체의 전체적인 구조를 파악하기에 가장 적합하다고 판단했고 모든 패치는 따라서 영상의 20퍼정도의 사이즈로 정했다고 합니다. 다음으로 영상 전체에서 patch 를 뽑지 않고 영상의 edge map을 추전한다음 그 edge map을 중심으로 patch를 계산합니다. 다음 각 패치와 영상을 병합하기 위해서 아래 그림과 같이 병합용 네트워크를 사용하며 이때 병합용 네트워크는 pix2pix를 사용했다고 합니다.
사실 이 내용이 굉장히 어렵고 딥하여 자세히 다루지 않았지만 위 설명이 거의 흐름이니 이렇게만 이해하고 넘어가셔도 좋을 것 같습니다. 궁금하신 분은 … 논문을… 참고
Result
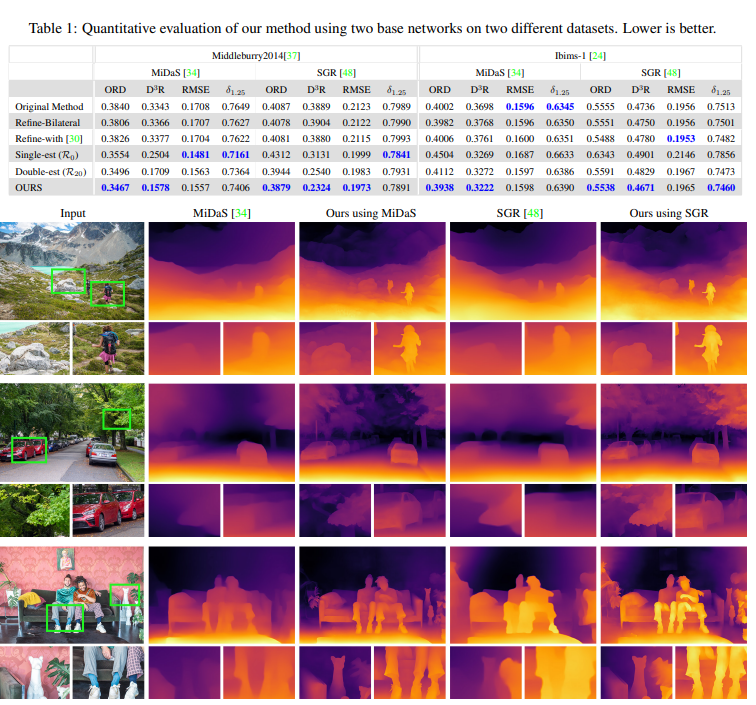
두 데이터셋에서 성능을 비교한 것입니다. 그랬을때 original method에 비해 최종 성능이 좋고 정성적으로 도 디테일이 살아 있는 것을 볼 수 있습니다.

GT와 비교해도 거의 동일한 디테일을 담는 것을 볼 수 있습니다.
좋은 리뷰 감사합니다!!
한가지 궁금한 점이 있습니다.
영상 사이즈가 작은 경우는 구조가 살고 영상 사이즈가 큰 경우는 디테일이 살아난다고 하셨는 데 두 이미지를 병합하면 서로 좋은 점만 남을 수도 있지만 나쁜 점만 남을수도 있을 것 같은데 이러한 문제는 병합 네트워크에서 해결이 되는 건가요??