이번에도 Facial Landmark Localization 논문입니다. 새로운 Loss 함수를 제안한 논문으로, 기존에 리뷰한 논문과는 다른 2D 기반의 Landmark Localization 방법론입니다.
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks – [바로가기]
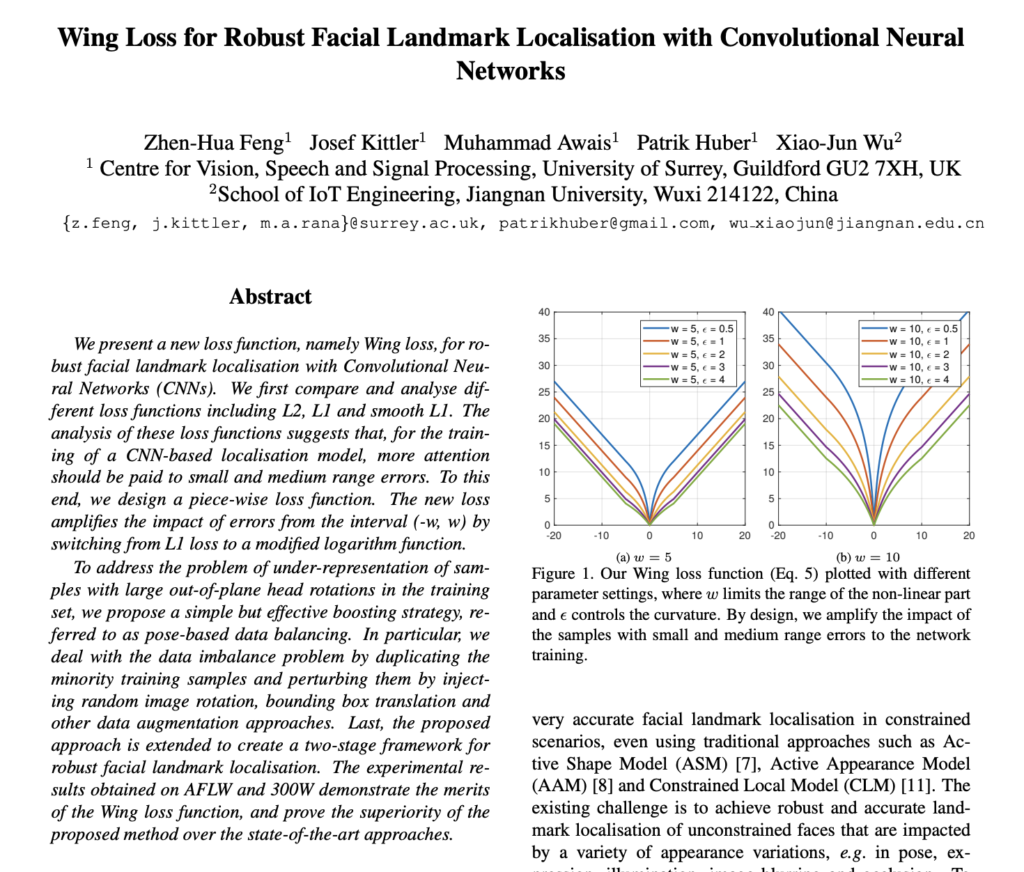
Facial Landmark Localization / Face Alignment 는 얼굴 이미지에서 미리 정의된 Landmark point-set 의 좌표를 찾는 것을 목표로 합니다. 다른 2D Landmark Localization 연구의 대부분에서는 L2 Loss를 사용하지만, L2 Loss는 outlier에 민감하다는 단점이 있습니다. 따라서 해당 논문에서는 Facial Landmark 를 고려한 새로운 Loss를 제안합니다.
CNN-based facial landmark localisation
다들 익숙하시다시피 CNN-based 의 Model에서는 적절한 네트워크 및 Loss를 설계하여 Loss를 최소화하며 학습을 진행합니다. 여기서 loss란 prediction과 GT 사이의 차이를 측정하는 사전에 정의된 손실 함수입니다. 그리고 이를 최적화하기 위해 확률적 경사 강하(SGD)와 같은 최적화 알고리즘을 사용하기도 합니다.
본 논문에서는 facial landmark localisation에서 다양한 Loss 함수를 실험적으로 분석하기 위해 CNN-6이라는 간단한 아키텍처를 사용하여 train/test 를 빠른 속도로 실험할 수 있었습니다. 또한 성능 향상을 위해 facial landmark localisation에서 처음으로 ResNet 을 사용하엿다고 합니다.
Wing Loss
CNN-based Facial Landmark Detection이기 때문에 적절한 Loss를 설계하는 것 역시 성능에 주요한 영향을 미칩니다. 기존 방법에서는 대부분 L2 Loss를 사용하면서 Loss 와 관련된 실험 및 분석이 많이 부족합니다. 따라서 이번 장에서는 L2 Loss 뿐만 아닌 다른 Loss 함수를 사용하여 비교 및 분석을 진행합니다. 그리고 더 나아가 기존에 정의된 Loss 가 아닌 Facial Localization의 정확도를 향상시킬 수 있는 새로운 Loss인 Wing Loss를 제안합니다.
(1) Analysis of different loss functions
여러 손실함수 비교 분석에 앞서 사용되는 Loss 들은 다음과 같이 정의됩니다.
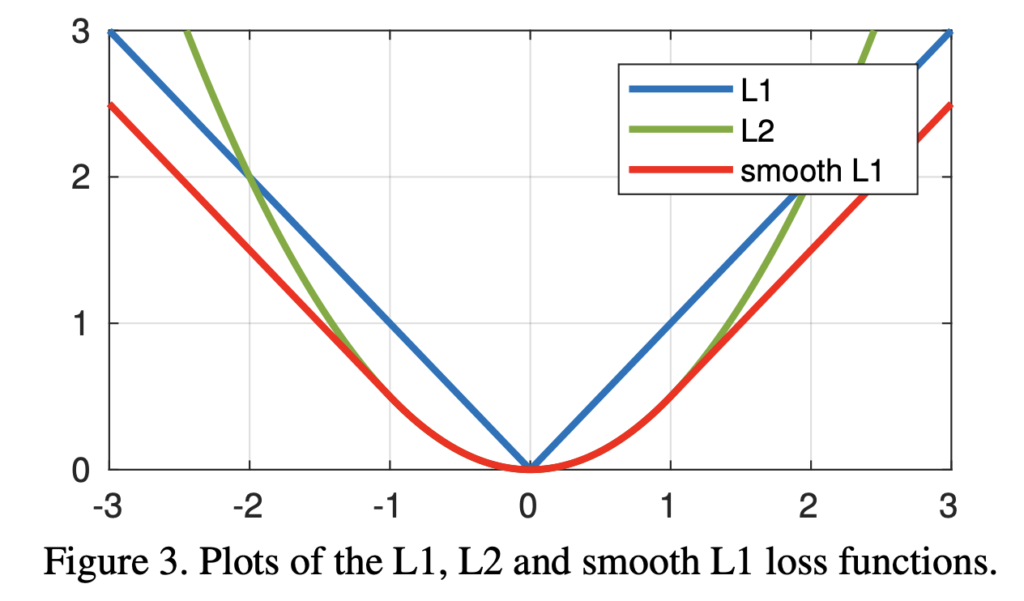
- L1 loss
L1(x) = |x| - L2 loss
L2(x) = \frac{1}{2}x^2 - The smooth L1 loss :
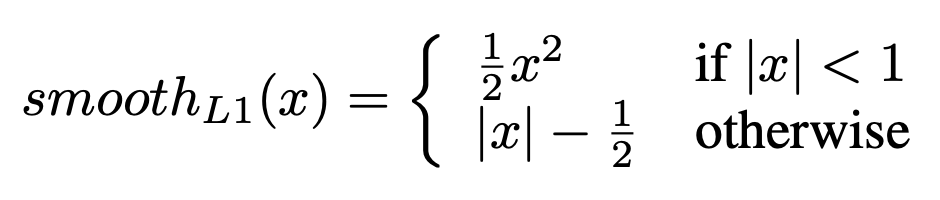
각각의 Loss 를 비교하기 위해 AFLW-Full 데이터셋을 사용합니다. 이 데이터셋은 train: 20,000 / test: 4,386 개가 존재하며 19개의 랜드마크로 구성됩니다. 그리고 비교 실험에는 3가지 모델을 사용합니다. (해당 모델은 L2 Loss를 사용함)
- CCL (CVPR 2016) : Random Forest 기반의 multi-view Cascaded Compositional Learning
- TR-DRN (CVPR 2017) : Two-stage Re-initialisation Deep Regression Network
- DAC-CSR (CVPR 2017) : cascaded shape regression 기반의 다중 뷰 방법론
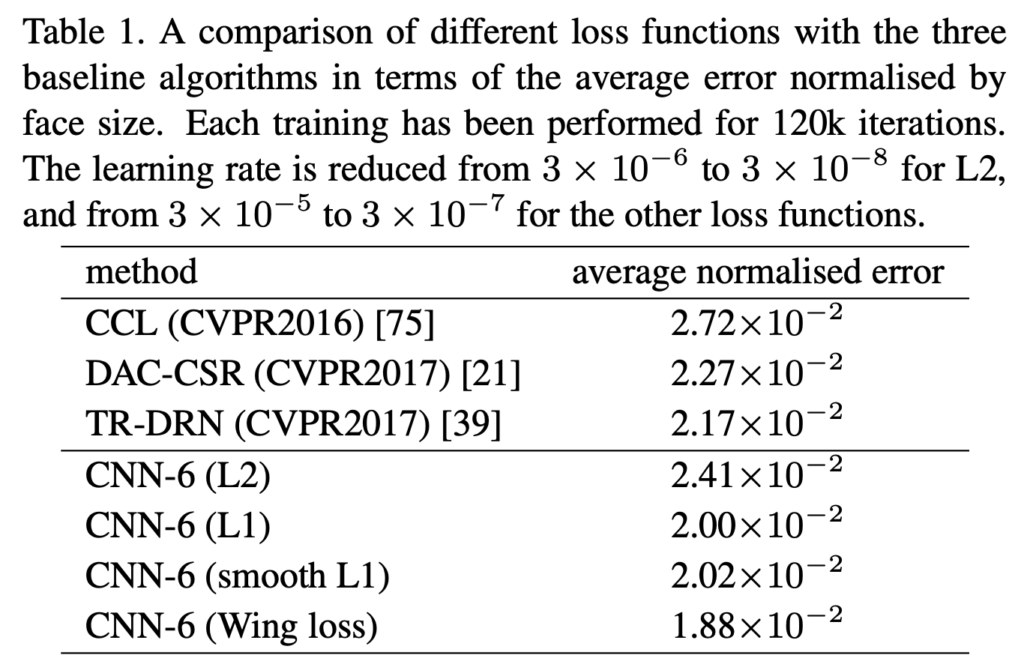
세 가지 다른 손실 함수를 사용하여 AFLW에서 CNN-6 네트워크를 학습한 결과는 아래 표에서 확인할 수 있습니다. 간단한 모델인 CNN-6을 사용해도 CCL(기계학습 기반)보다 좋은 성능을 가집니다. 뿐만 아니라 단순한 모델임에도 불구하고 정확도 측면에서 대개 사용되는 L2보다 L1 그리고 smooth L1 이 더 높고 기존 SOTA 역시 능가하게 됩니다.
(2) The proposed Wing loss
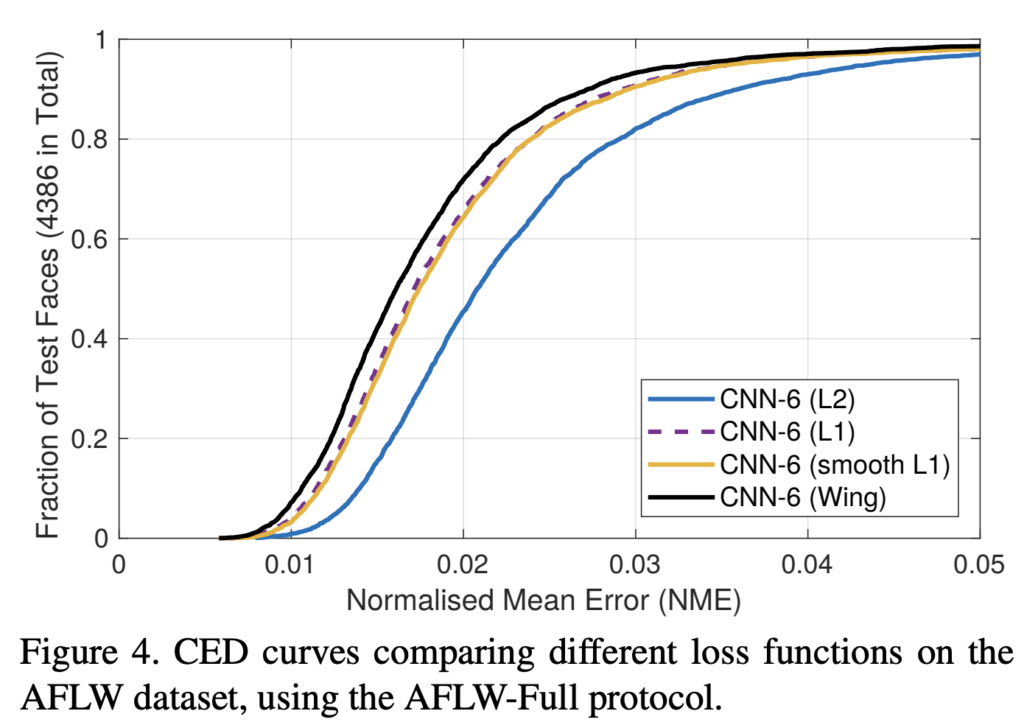
아래 그림 CED(Cumulative Error Distribution) 곡선을 통해 Loss 에 대한 CNN-6 네트워크 결과를 비교할 수 있습니다. NME가 클 때에는 모든 손실 함수가 잘 수행되지만, 작거나 중간 범위의 에러에는 성능 차이가 발생합니다. 다시 말해, 작거나 중간 범위의 오류를 개선해야한다고 해석할 수 있습니다. 이 목표를 달성하기 위해 본 논문에서는 Facial Landmark Detection을 위한 새로운 손실함수인 Wing-Loss 를 제안합니다.
아래 L1 및 L2의 기울기의 크기는 각각 1과 |x|로 optimal step size는 |x| 과 1이어야 합니다. 두 경우 모두 최소값을 찾는 것은 간단하지만, 여러 지점의 랜드마크를 동시에 최적화하려고 할 때에는 복잡해집니다. 두 경우 모두 큰 오류에 집중되어 업데이트되기 때문입니다. L1의 경우, 기울기의 크기는 모든 점에 대해 동일하지만, step size는 더 큰 오류에 의해 불균형적으로 영향을 받습니다. L2의 경우, step size는 동일하지만 gradients는 큰 에러에 의존하게 됩니다. 따라서 두 경우 모두 상대적으로 작은 에러를 보정하기는 어렵습니다.
이런 작은 에러의 영향은 ln x와 같은 대체 손실 함수를 사용하면 보완할 수 있습니다. 왜냐하면 1/x이라는 기울기는 에러가 0에 가까워질수록 증가하기 때문입니다. optimal step size는 x^2입니다. 여러 점의 영향을 종합할 때, gradient는 작은 값을 가지는 오류에 더 큰 영향을 미치지만, step size는 큰 값을 가지는 오류에 더 큰 영향을 받습니다. 이렇게 하면 크기가 다른 오류 사이의 영향을 받는 그 균형이 맞춰지게 됩니다.
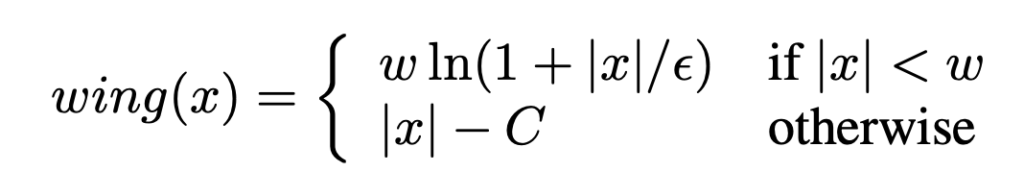
그림 4에서 볼 수 있듯이, wing-Loss는 L2, L1, 그리고 smooth L1보다 정확한 성능을 가집니다. wing-loss는 NME를 2 × 10-2에서 1.88 × 10-2로 감소시킬 수 있었고, (표 1)에서 얻은 결과보다 6% 낮으면서 기존 SOTA인 TR-DRN)보다 13% 낮은 결과를 보입니다.
다시 정리하면 Wing-Loss의 key-idea는 작고 중간 크기의 오류가 있는 샘플이 Train에 기여하는 영향력을 높이는 것이며, 이를 통해 성능 향상을 가져올 수 있었습니다.
리뷰 잘 읽었습니다.
얼굴과 관련된 연구에서는 유사한 생김새를 구분 해야 하기 때문에 모델의 구분력을 강인하게 하기 위해 loss 식들을 많이 제안하는 것 같네요.
Wingloss가 ln(x+1)을 도입하면서 작은 에러 값에서보다 강인하게 작동한다는 것은 이해가 갑니다.
하지만… 수식을 보면 w가 작은 에러값이 생성 될 수 있는 x를 판단하는 변곡점에 해당하는 것으로 보입니다. 근데 w에 대한 설명이 없어 이해가 잘 안됩니다.
|x|가 w보다 작을 때는 C 값에 상관없이 자연 로그를 취하는 건가요? 그럼 w가 에러값을 대체하는 걸로 보이는데…
|x|-w < 0 으로 조건식을 변경해보면 w가 C를 대체하는 것으로 볼 수 있고, w가 하이퍼 파라미터면... 각 케이스에 대해 어떻게 고려되는건지... 상황상 w를 learnable parameter인데... 음... 설명 부탁 드립니다. 그리고 입십론은 그냥 하이퍼 파라미터인가요?