해당 논문은 NeurlPS’2020에 공개된 논문으로 FixMatch와 같이 발표되었다. 두 논문 모두 Google 에서 발표되었다. FixMatch는 CIFAR-10과 같은 작은 데이터셋에서 Semi-supervision의 새로운 모델의 가능성을 보였고, 해당 논문은 큰 네트워크를 이용해 Unlabeled data를 Pretrained Dataset으로 이용하는 방법을 소개했다. 저자 Ting Chen은 이전 SimCLR의 저자이며 해당 논문에서 SimCLRv2를 제안하였다.
Abstract
논문에서 말하길, few labeled data와 large amount of unlabeled data를 가장 효과적으로 사용하는 것은 unsupervised pretraining이라고 한다. unsupervised pretraining이란, ground truth가 없는 unlabeled data로 모델을 task-agnostic 하게 먼저 학습시키는 것이다. 논문에서는 큰 모델(deep and wide)을 pretraining과 fine-tuning하고, 이를 Teacher, Student모델을 이용하여 전이학습 하여 실험하였을때 ImageNet과 ResNet-50 등의 데이터셋에서 높은 예측 정확도를 보인다.
Method
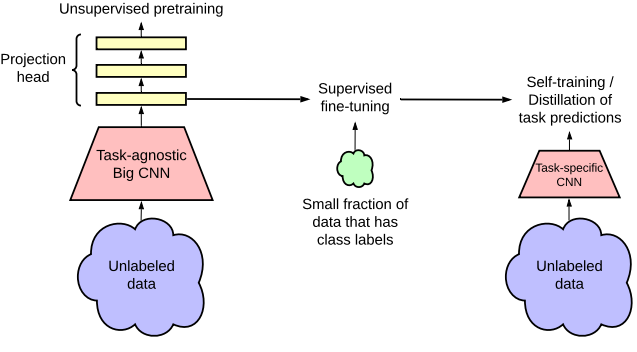
제안하는 방식은 Unlabeled Data를 두가지 방식으로 사용한다. 먼저 왼쪽처럼 초기 Unsupervised Pretraining (Task-agnostic)을 위하여 사용하고, 이후 오른쪽처럼 Task-Specific한 학습에서 Self-Training(Distillation)을 위해 사용한다.
- Self-Supervised Pretraining 과정
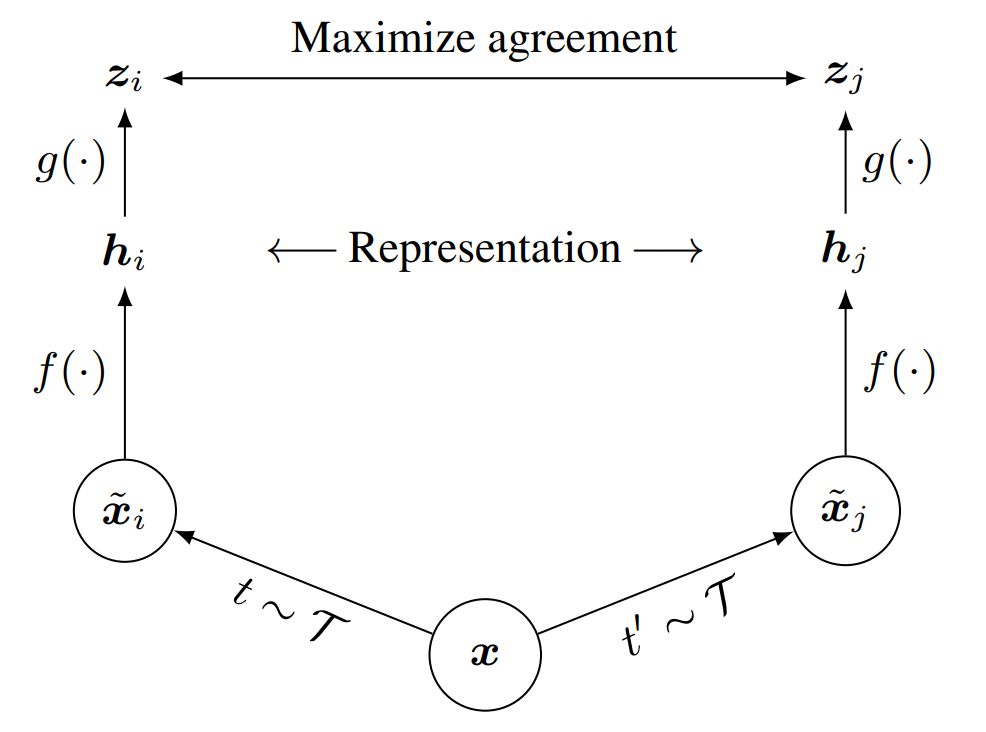
SimCLRv2에서도 이전과 같이 Contrastive Loss를 이용한다. 위의 SimCLR의 그림에서와 같이 만약 zi와 zj가 같은 이미지 content(x)를 갖는다면 이는 유사도가 커 loss가 최소화 될 것이다.
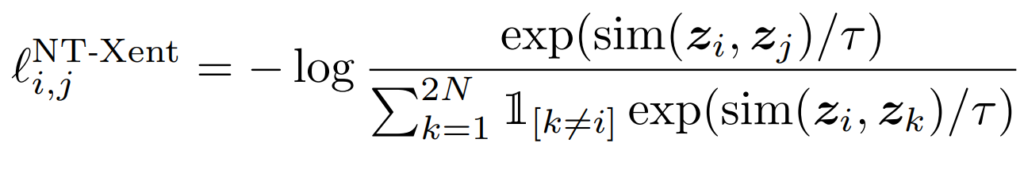
- FIne Tuning
Self-Supervised Pretraining은 지정된 과제 없이 유사도를 이용해 Feature Representation 향상을 위해 학습하는 것이라면 FIne Tuning은 Task-specific을 목적으로 한다. 해당 과정에서는 g 모델을 사용하지 않고 encoder 모델인 f모델만을 사용해 Feature Representation을 진행한다. 해당 이니셜은 위 SimCLR의 그림 기준이다. 즉 projection head의 모든 part를 사용하지는 않는다. - Self-Training
전이학습 과정은 Teacher 모델이 생성한 labels로 작은 모델을 Supervised 학습하며, 이때 Unlabeled Data도 사용된다. Teacher 모델이 일종의 Psuedo Label을 생성하는 것이다. 전이학습을 위한 Loss 구성은 다음과 같다.
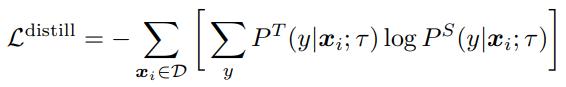
실험
실험에서 우선 기본적인 Linear Classification on Representation 실험을 진행하였다. 이는 모델의 Feature Representation 성능을 비교하기 위한 실험이다. Self-evaluation 형식으로 진행되었다.
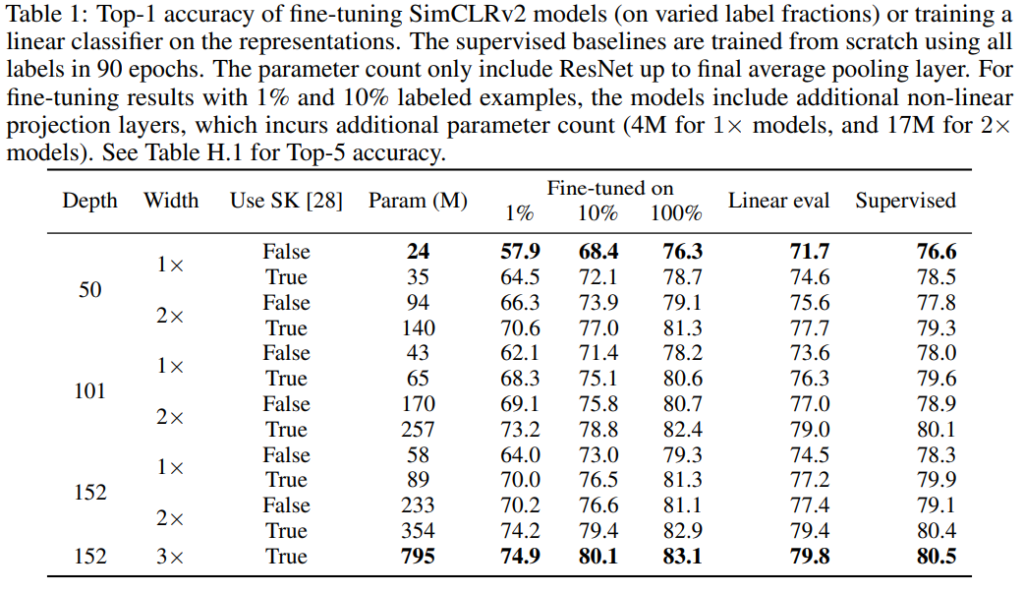
둘째로는 Unspervised Pretraining시 모델 크기에 대한 영향을 실험하였다. 해당 실험을 통해 Semi-supervised 에서는 모델의 크기가 꽤 영향을 미침을 확인하였다.
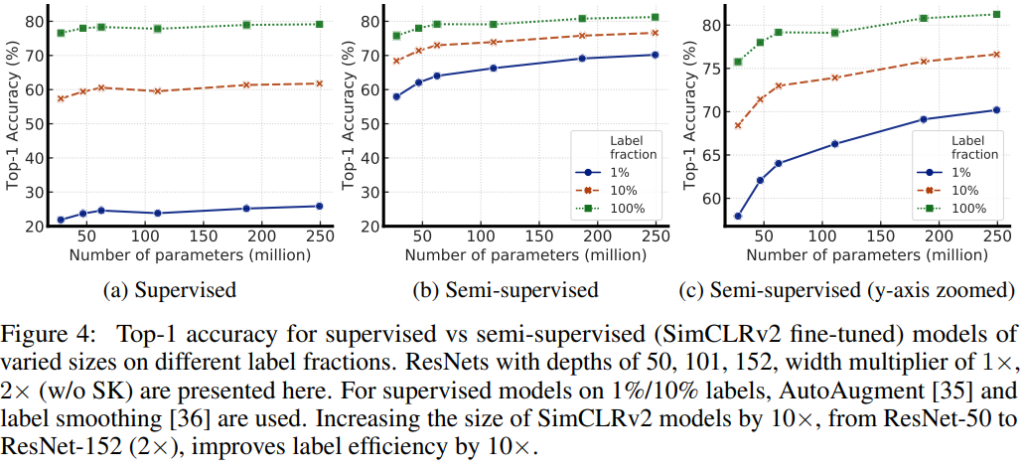
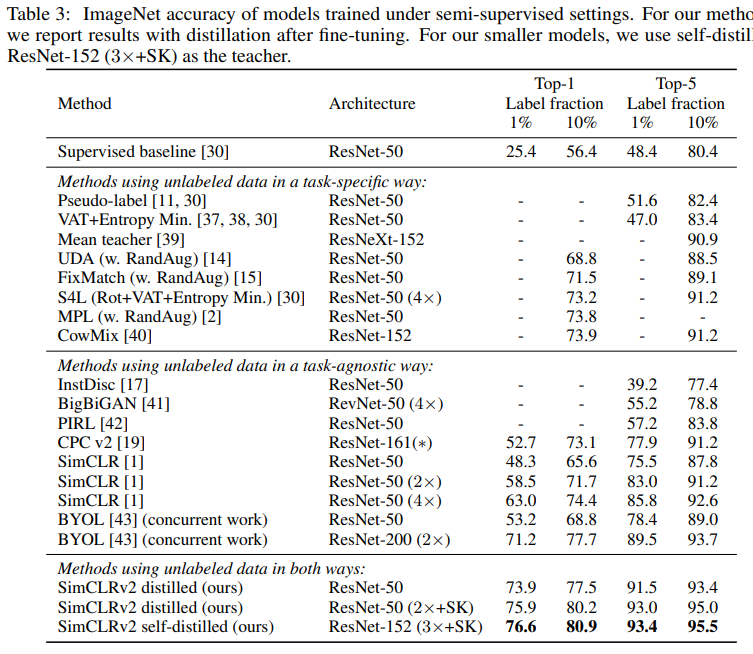
다양한 Self-evaluation 실험 이외에도 많은 SoTA모델과 비교하여 높은 성능을 보임을 증명하였다.
마무리
지난번 리뷰의 FixMatch는 Unlabeled Data에서 Labeled Data를 직접 생성하고 추출하였다면 해당 논문은 Unlabeled Data로 모델을 PreTrain 하여 높은 성능을 보이는데에 이용하였다(물론 이후 전이학습을 진행하였으나, FixMatch와 다르게 Teacher Student 구조를 이용한다.).