제가 이번에 소개해드릴 논문은 TPH-YOLOv5라고 불리는 논문이며, 2021년 ICCV Workshop에서 발표된 논문입니다. 해당 논문은 최신 YOLO 시리즈를 이용하여 드론에서의 detection에 대하여 다루고 있습니다.

드론에서의 디텍션은 자율주행차량과 같은 ground에서의 디텍션과는 다릅니다. 위의 그림을 보시면 아시다시피 그 대표적인 차이가 바로 검출할 대상물체의 크기입니다. 그러므로 해당논문에서는 COCO데이터셋과 같은 인스턴스의 크기가 큰 경우에 최적화 되어있는 YOLO를 그대로 사용하지 않고 추가적인 수정을 많이 하였습니다. 제가 직접적으로 드론에서의 디텍션에 관심이 있다기보단, Small object를 찾기위해 취하는 테크니컬한 부분에서 영감을 얻을 수 있지 않을까 해서 읽게되었습니다.
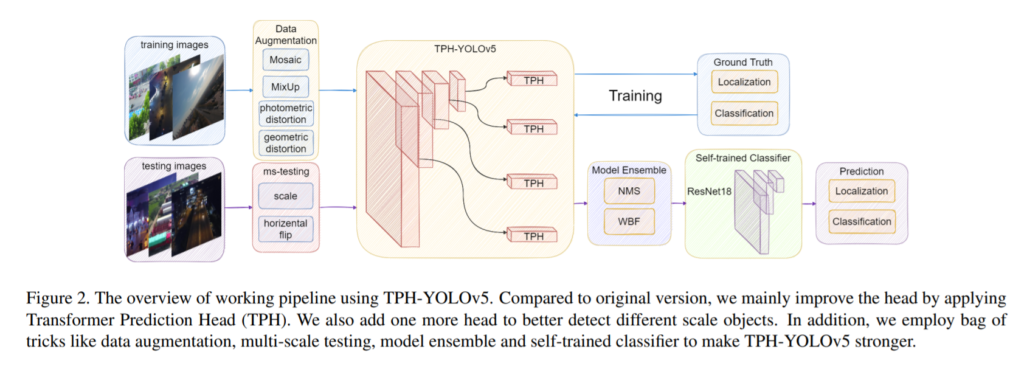
전체적인 아키텍쳐입니다. 한개의 논문에 굉장히 많은 것들을 소개하고 있어보이는데, 각각의 컴포넌트가 모두 논문에서 제안하는 방법은 아니고 여러가지 논문에서 제안한 방법들을 모아둔 것 입니다. 내용이 굉장히 많긴한데 부분적으로보면 대부분 마이너한 것들이라 실제로 이해하는데는 큰 어려움이 없을 것 입니다.
일단 위의 아키텍쳐에서 튜닝전 욜로와의 차이점은, ms-testing , WBF, Head 1개추가, self-trained classifier 등이 있습니다. 좀 많긴한데 하나씩 차근차근 설명해드리겠습니다.
ms-testing이란 6개의 서로다른 스케일의 input이미지와 horizontal flip 을 사용하여 다양한 input에서의 detection 결과를 뽑아내고, 해당 결과들을 NMS처리하여 최종 결과를 뽑는 방법입니다. 일종의 앙상블이라 생각하면됩니다.
위에서 나온 결과를 총 5개의 모델에 반복적으로 사용하여 5개의 예측값을 뽑고, 5개의 예측값에 추가적으로 WBF처리를 하였습니다. NMS를 엄청 여러번하고 마지막에 WBF도 하는게 좀 신기하네요. 이러한 방식으로하면 성능은 극대화 시킬지언정 속도는 엄청 느리겠네요.
여기서 WBF는 해당 논문에서 설명되어있지 않아 ref논문에 들어가 보니 컨셉적인 측면에서 이해가 되었습니다.
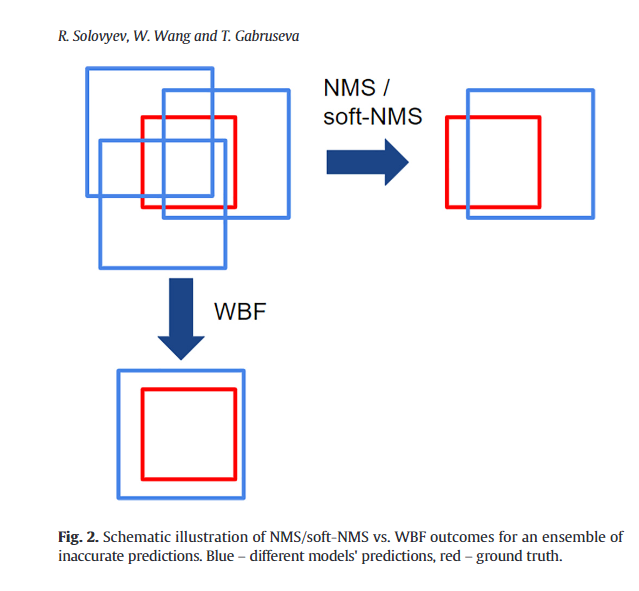
위의 그림은 WBF가 NMS와 어떻게 다른지 잘 보여줍니다. 기존의 NMS는 한개의 BBOX만이 살아남았지만, WBF는 일종의 앙상블과 같다고 생각하시면 됩니다.
즉 해당 방법론에서는 NMS를 엄청 여러번하고, WBF로 최종 Prediction값을 도출합니다.
또한 차이점으로 일반적인 욜로시리즈와는 다르게 head를 4개를 사용합니다. 이는 small object에 대한 검출을 위함 이라고 합니다. 직관적이므로 설명은 생략하겠습니다.
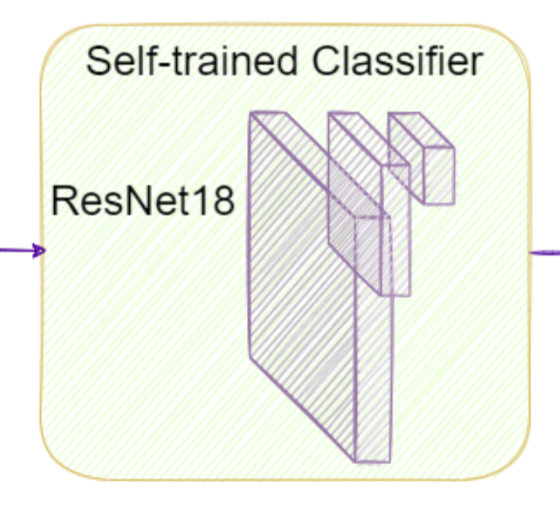
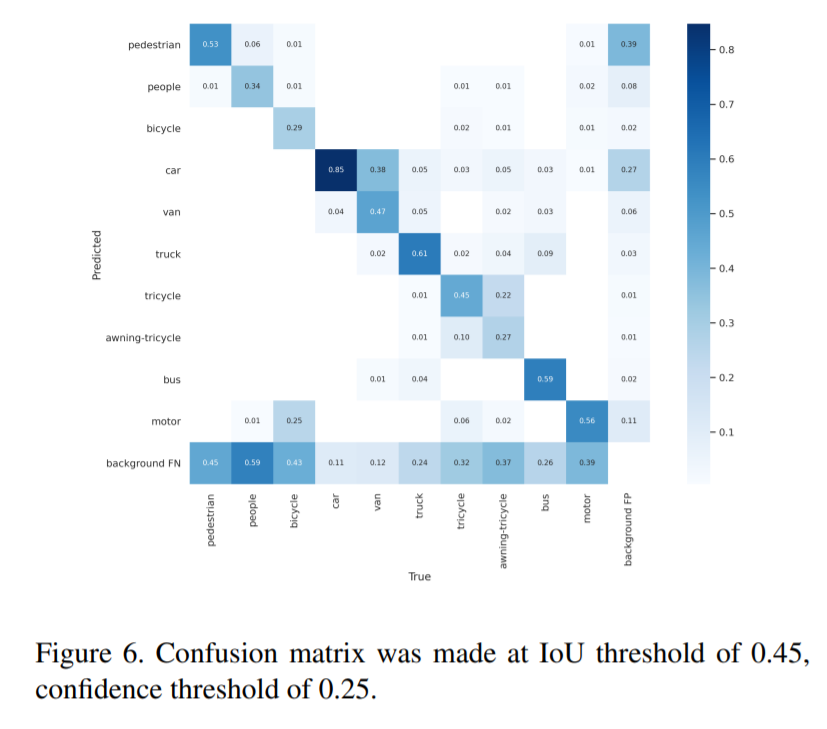
또한 인스턴스 크기가 너무작아서 디텍션 결과의 classification 이 poor하였고, 이를 개선하기위해 detection된 영역을 crop하고 64*64로 리사이즈하여 다시 classification하는 방식을 사용하였습니다. 그리고 이를통해 confusion matrix에서tricycle, awning-tricycle등 일부 물체에 대한 classification 성능이 올라간것을 확인했습니다.
아래 그림은 똑같이 프레임워크이긴한데 전체 프레임워크의 구조를 좀 더 구체적으로 보여줍니다.
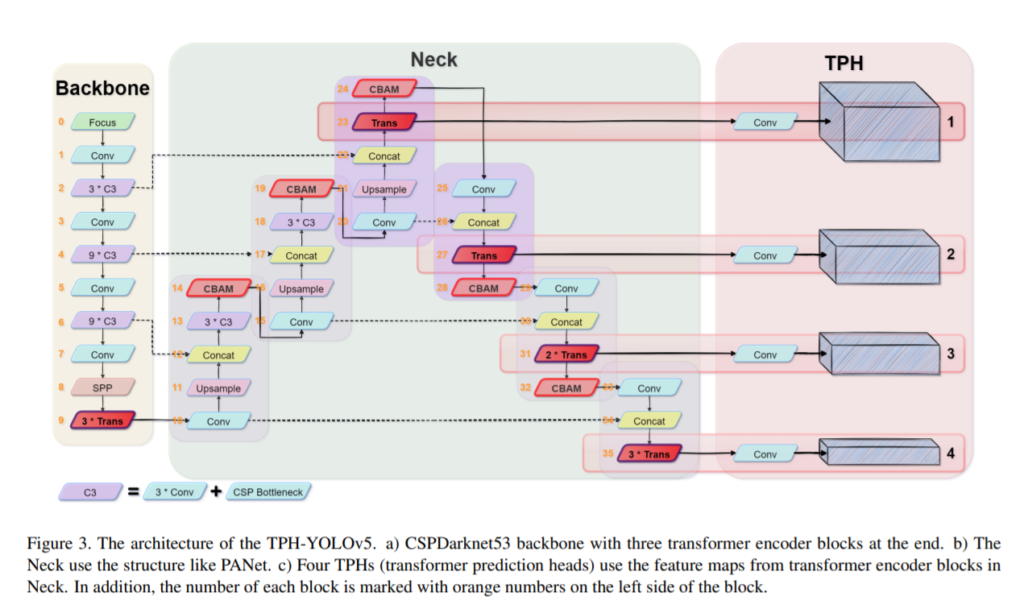
다른 디텍션 방법론들과 마찬가지로, 프레임워크는 피쳐를추출하는부분과 Backbone과 Neck, Head로 나뉘어져 있습니다. 위의 그림에서 Head는 TPH 에 해당하는 부분으로 기존의 Head와는 다르게 transformer를 사용하였기에 Transformer prediction heads라고 명칭하였습니다.
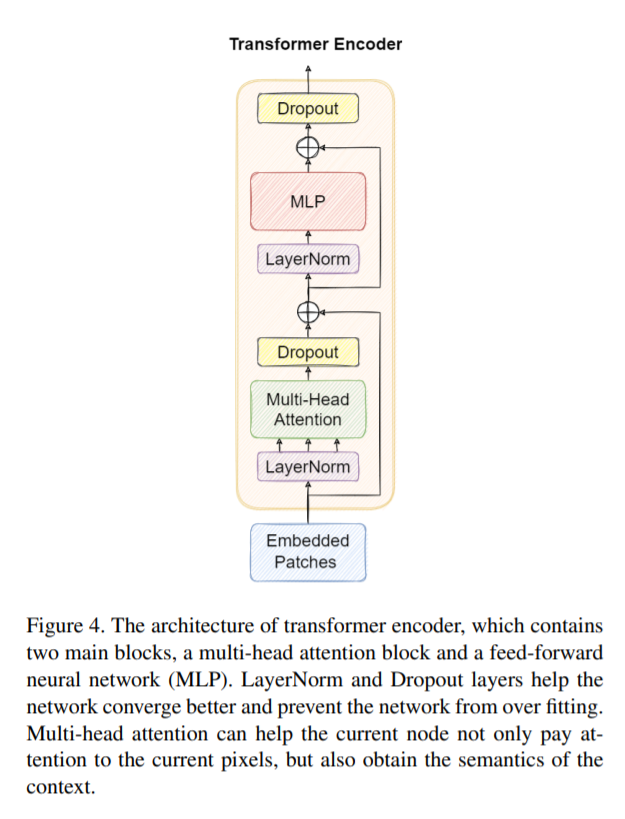
또한 위처럼 간단한 구조의 transformer를 CNN블록을 대신하여 사용하였습니다. 저자가 말하기를 “we believe that transformer encoder block can capture global information and abundant contextual information.” 라고 하였는데, 과연 진짜로 글로벌한 정보를 더 잘 인지할지 모르겠네요. 어찌됐든 CNN 블록 일부를 transformer로 대체하였을때, 더 좋은 성능이 나왔습니다. 그리고 특히나 드론 데이터셋의 특성상 instance끼리 오밀조밀하게 뭉쳐져 있거나 occluded된 경우가 많은데 이러한 환경에서 transformer 블록을 섞어주는게 성능개선 효과가 있었다고 합니다.
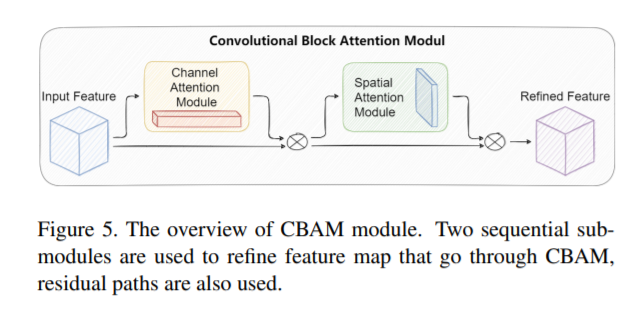
다음으로는 Attention 모듈로 사용한 CBAM입니다. 사실 CBAM은 이번에 KCCV학회에서도 잠깐 들었던 내용이기도 하고 다른 논문에서도 언급되는걸 몇번본적이 있어서 익숙하긴 했는데 정확히 어떻게 Working하는지는 잘 알고있지 못했습니다. 그리고 해당논문에서도 위처럼 생략이 좀많아서 원래 CBAM논문에 들어가보았습니다.
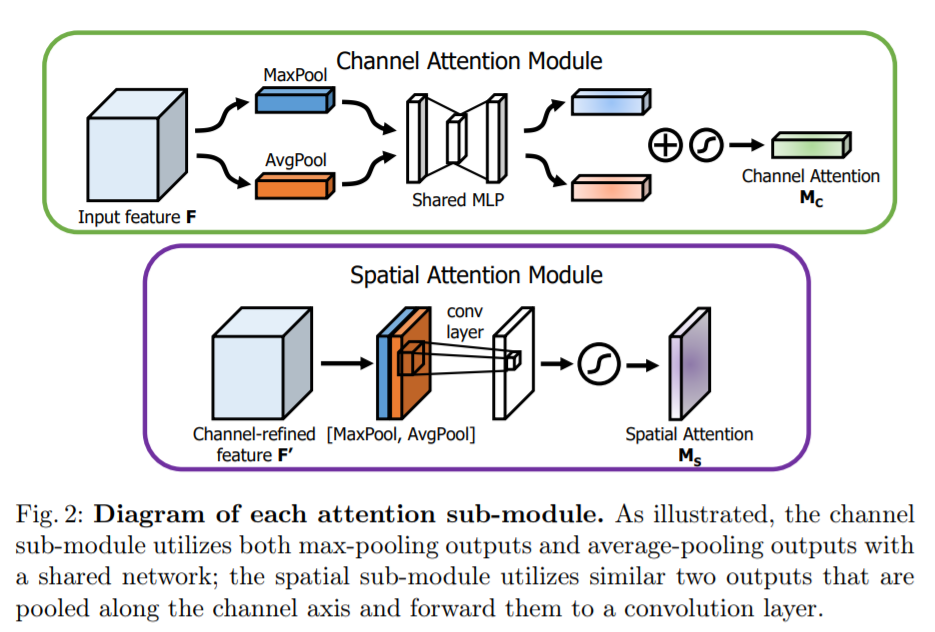
위와 같은 원리로 Working하는걸 알 수 있었는데요, 이는 최근 KAIST SOTA근처 논문들에서 많이 사용하는 Attention모듈들과 매우 흡사합니다. 다만 저는 멀티스펙트럴기반에서의 attention 기법에 익숙해서 그런지 싱글모달리티인 상황에서의 attention은 좀 낯서네요. channel-wise하고 spatial하게 attention을 주었다는 관점에서는 매우 흡사합니다.
원리는 그리 복잡하지않고, MaxPool과 AvgPool한걸 element-wise로 더해준다음 MLP를 태워주고 나온 1d Vector를 나눠서 sigmoid를 태운다음 원래의 값에 곱해주는 방식입니다. 기존에 제가 리뷰했던 Attention Fusion for One-Stage Multispectral Pedestrian Detection에서 사용하는 attention 방식과 거의 동일합니다. 다만, 멀티스펙트럴인 경우에는 각 모달리티의 가중치를 구하는데 싱글모달리티인 경우에는 뭔가 background와 foreground에 대한 가중치의 느낌이 강한거 같네요.
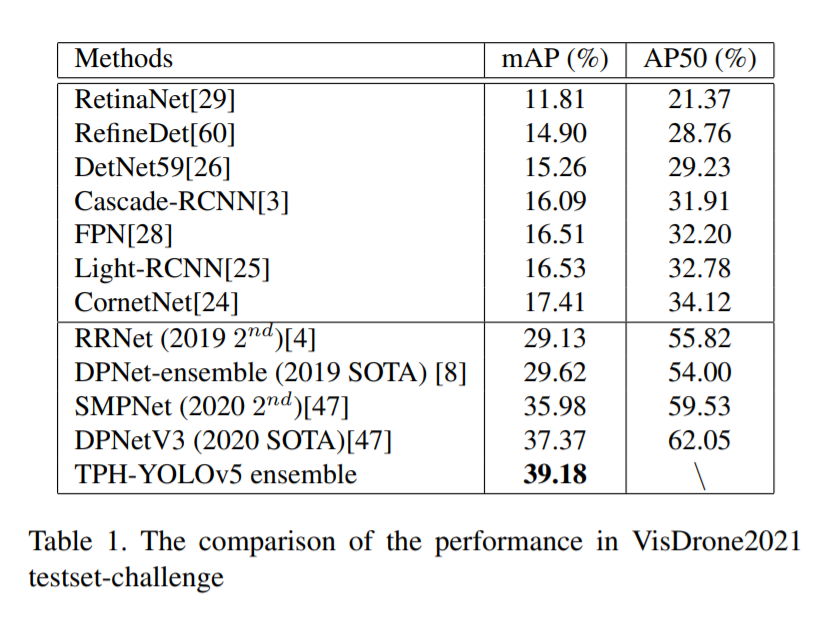
이렇게 엄청 많은 방법론들을 모두 종합했을때 mAP기준 VisDrone2021 데이터셋에서 좋은 성능을 달성했습니다,
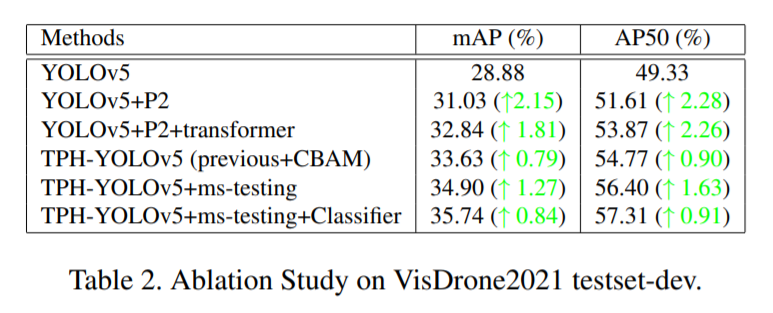
Ablation study에서는 각 모듈들이 성능에 어느정도 영향을 미치는지 보여줍니다.
뭔가 영혼까지 끌어모아 성능을 끌어올린다는 느낌이 강했었는데, 역시나 챌린지의 일환이었나보네요. 2020년에 비해서는 2퍼센트정도 오른 성능을 기록했는데, 2021에서는 5등으로 마무리한거같네요. 1등이라는 0.25점 차이라는데, 저자는 이에대해 리더보드 제출횟수 제한이 좀 더 많았다면 ensemble 기법을 사용할 때 좀더 성능을 끌어올릴 수 있엇을거라 언급합니다. 개인적으로는 글쎄요?…
뭔가 사용한 방법이 너무 많아서 방법들을 리스트하는식으로 서술한거 같은데 이해가 안되시는 부분이있으면 댓글로남겨주세요.
글에서 언급하였듯 속도적인 측면에 대해서 리포팅은 없나요? 드론에서 사용되려면 속도가 중요한 요소가 될것 같아 질문드립니다.
네 아쉽게도 없네요. 챌린지의 일환이라 속도는 고려하지 않은듯합니다. 앙상블을 5개를 하니 당연히 속도는 불리했을테고 불리한것을 리포팅할 이유도 없었겠지요.