예전에 읽고 정리하지 않는 논문을 가져왔습니다. 비디오 검색과 관련 있는 논문을 최근 읽고 있는데, 해당 논문은 비디오에서 시공간 특징을 학습을 위한 방법론에 관련된 내용입니다.
Introduction
다양한 목적을 위해 비디오를 분석하고 이해할 필요가 있어졌고, 이러한 이해를 위해서는 좋은 video descriptor가 필요하다는 내용으로 시작합니다. 이러한 video descriptor는 4가지 조건(generic, compact, efficient to compute, simple to implement)을 만족해야한다고 합니다. 그리고 이미지 feature에 관한 방법론들이 많긴 해도 비디오의 특성과는 맞지 않았기 때문에 논문에서는 deep 3D ConvNet을 이용해서 시공간적 특성을 학습했다고 합니다. 이 논문의 conturibution 3개를 정리하면 아래와 같습니다.
- 실험적으로 C3D가 apperance와 motion을 동시에 잘 탐지한다는 것을 보여줌
- 실험적으로 3x3x3 convnet을 쓰는게 좋다는 것을 보여줌
- 이렇게 뽑은 feature로 linear model과 함께 쓰는 것이 성능이 좋았음 (compact & efficient to compute)
Learning Features with 3D ConvNets

2D는 처음 conv layer에서 시공간적 정보가 완전하게 뭉개지기 때문에 3D는 시공간적 정보를 2D에 비해 더 잘 탐지할 수 있고, 그 차이는 위 그림에서 확연하게 볼 수 있습니다. 기존의 방법론(Large-scale video classification with convolutional neural networks)에서는 처음 3개의 conv layer에서 3D conv와 averaging pooling을 사용했는데, 성능은 좋긴 했지만 여전히 시공간적 정보를 3개의 conv layer 이후에 상실하는 문제가 있었습니다.

그래서 이 논문에서는 C3D가 좋다는 것을 설명을 한 뒤에 실험 결과와 함께 성능으로 보여줍니다. 실험에 사용한 C3D 구조는 위 그림에서 확인할 수 있습니다. 단순하게 위 구조만 실험한 것은 아니고, ablation study의 일한으로 아래의 구조도 같이 실험했습니다.
- depth-d : temporal depth가 1,3,5,7로 고정된 4개의 network
- increasing : temporal depth가 증가(3-3-5-5-7)인 구조
- decreasing : temporal depth가 감소(7-5-5-3-3-)인 구조
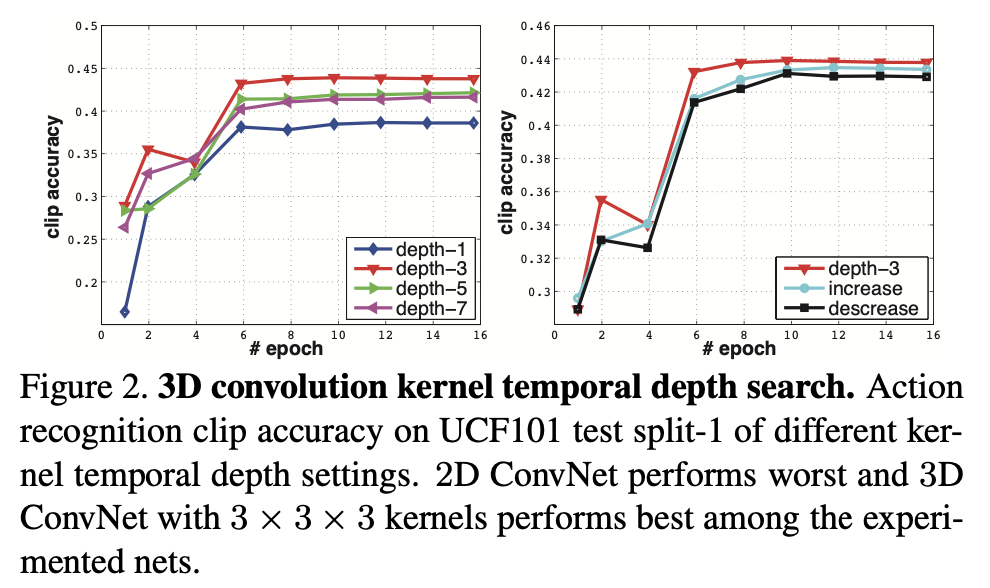
위에서 고려한 모든 실험 결과를 고려했을 때, 3x3x3 커널 사이즈를 가지는 구조가 가장 성능이 좋았음을 확인할 수 있었습니다.
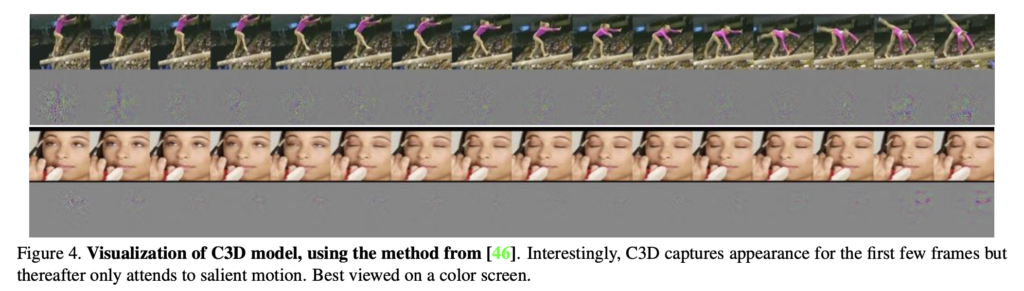
학습이 끝나면 C3D는 다른 비디오 분석에서 feature extractor로서 사용될 수 있으며, 이걸 C3D video descriptor라고 부릅니다. 시각화 결과와 논문의 설명을 바탕으로 확인해보면, C3D 모델이 기존의 2D convnet과 다르게 움직임과 형태에 집중하는 것을 확인할 수 있습니다.
Experiments
Action recognition
평가는 UCF101으로 진행되었는데, C3D로 feature를 추출하고, multi-class linear SVM으로 분류하였습니다. C3D descriptor는 3가지 네트워크(C3D trained on I380K, C3D trained on Sports-1M, C3D trained on I380K and fine-tuned on Sports-1M)로 실험함.
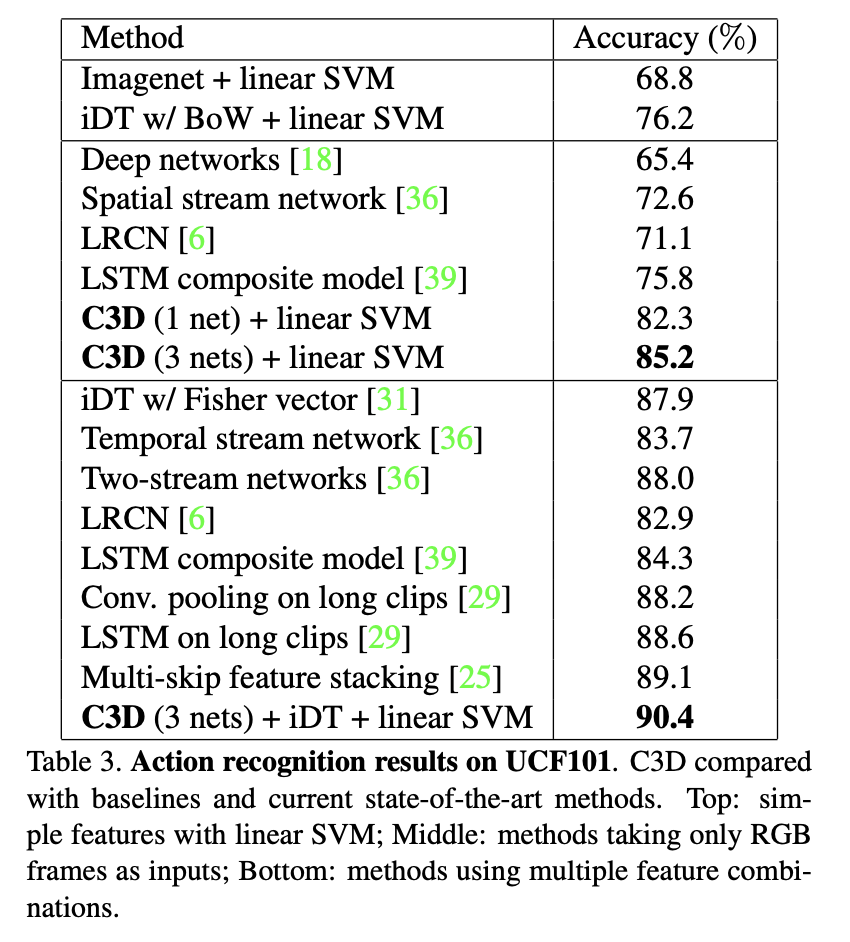
UCF101로 한 실험으로 C3D는 움직임과 외형 정보 둘 다 잘 탐지하는 것을 확인할 수 있었고, iDT와 상호 보완적인 관계라는 것을 확인할 수 있었습니다.
Action Similarity Labeling
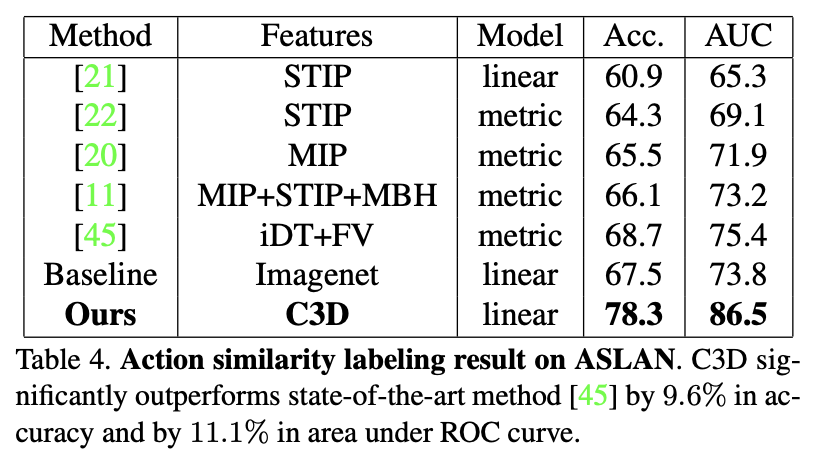
역시 C3D가 가장 좋은 성능을 내었음. 이 부분에서의 핵심은 최근의 방법론들이 강력한 encoding methods와 복잡한 학습 모델을 쓰는 반면에 C3D는 간단한 구조를 쓰는데 성능이 잘 나온다는 점이 주요 내용이었습니다.
Scene and Object Recognition
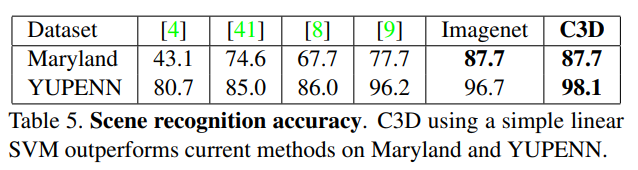
YUPENN과 Maryland 데이터셋을 사용했는데, 일단 데이터 특성(1인칭 뷰)이 다르기 때문에 성능이 잘 안나올 수도 있었는데도 성능이 잘 나와 놀라웠다고 합니다.
Runtime Analysis
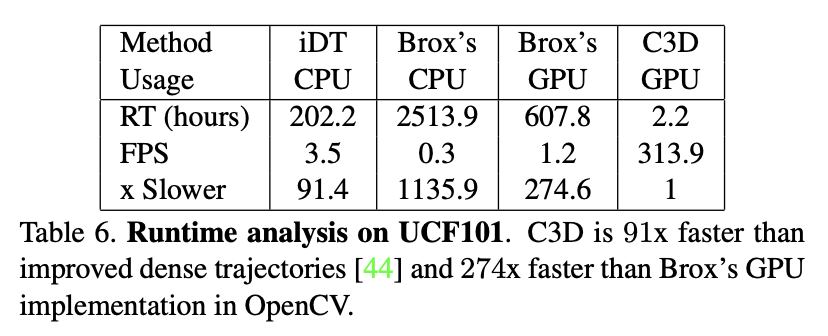
사실 성능보다도, 실행 속도가 엄청 빠른 것이 인상 깊은 부분이었습니다.