오늘 리뷰할 논문은 역시나 Self-supervised Depth Estimation 논문입니다.
Abstract
기존의 Depth Estimation 방법론들은 학습에 사용할 수 있는 데이터의 종류에 따라 분야의 경계를 명확히 해왔습니다. 예를들어 Lidar를 학습에 사용할 수 있으면 Supervised or Semi Supervised라고 명칭했으며 이미지만을 사용하는 Self-supervised의 경우 또 Stereo image와 Video frame에 따라 구분을 두었죠.
저자는 이러한 Self-supervised 방법론에서 Stereo와 monocular image(여기서는 video frame을 사용하지는 않는 듯 합니다.)의 상호관계를 적절히 이용하면 두 방법론 모두 성능이 좋아질 수 있다는 것을 밝히며 Stereo image와 mono image를 동시에 활용하는 방법론을 제안합니다.
아 참고로 이 논문에서의 Stereo 방법론은 학습 때 Stereo 영상으로 loss를 계산하는 그런 방법론이 아니라 입력 자체가 좌우 영상 함께 들어가는 그런 방법론인 것 같습니다.
논문이 하고자 하는 방법론의 핵심은 다음과 같습니다.
- Stereo 이미지를 활용해 Self-supervised 방식으로 먼저 네트워크를 학습시킵니다.(StereoNet)
- 그 후 논문에서 제안하는 Occlusion-aware distillation 모듈을 통해 Occlusion map을 생성하여 non-occluded 영역에서 StereoNet으로 예측된 Depth map을 보강합니다. 이렇게 보강된 Depth map은 단일 영상 깊이 추정 네트워크인 SingleNet을 학습시키는데 사용합니다.
- 마지막으로 저자가 또 제안하는 Occlusion-aware Fusion Module을 사용하여 주어진 occlusion map으로 StereoNet과 SingleNet이 추정한 깊이를 융합함으로써 최종적인 Depth map을 생성합니다.
Overall Framework
먼저 제안하는 방법론의 전체 파이프라인에 대해서 살펴보겠습니다.
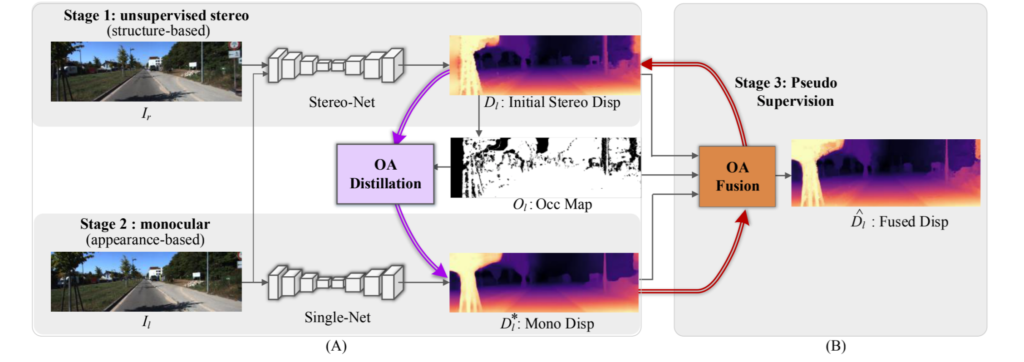
일단 학습 단계는 크게 3단계로 구성되어 있습니다. 첫번째 단계에서는 일반적인 Self-supervised 방식으로 stereo image를 matching시켜 Stereo-Net을 학습시키는 것입니다. 조금 더 간략하게 설명하면 추정된 Disparity map으로 오른쪽 영상을 왼쪽 영상으로 warping시켜서 실제 왼쪽 영상과 warping된 왼쪽 영상과의 photometric loss를 계산하는 것입니다.
저자는 이렇게 학습되는 Stereo-Net의 경우 왼쪽 영상과 오른쪽 영상 속 패치들 사이에 구조적 대응 관계를 학습하는 것이라고 판단하였습니다. 그래서 저자는 Stereo-Net을 통해 구조 기반 학습이라고 명칭하였습니다.
두번째 단계로는 단일 영상만으로 깊이를 추정하는 Single-Net을 학습하는 것입니다. Single-Net을 학습시킬 때 당연히 일반적인 monocular Depth Estimation과 같이 인접한 Video Frame을 사용하는 것으로 판단하였는데 그게 아니라고 하네요.
저자는 기존의 방식들과 달리 occlusion-aware Distilation을 통해 스테레오 매칭 브랜치의 예측값을 보다 정확히 만들고 뿐만 아니라 Occlusion map을 생성함으로써 Supervised 형식으로 monocular depth를 학습시킨다고 합니다.
Occlusion이 있는 영역 내에서 어떠한 대응되는 픽셀들이 없다고 할 때 StereoNet에서 추정된 Depth map은 부정확할 가능성이 큽니다. 당연하게도 좌 우 영상이 모두 대응되는 무언가를 보고 있다고 했을 때 비로서 학습이 잘 될텐데 occlusion이 생겨서 둘을 비교할 수 있는 영역이 없게 되버리면 이게 warping이 잘 되었는지를 판단할 수 없기 때문이죠.
하지만 monocular image로 depth를 추정하는 SingleNet의 경우 하나의 영상 그 자체만으로 Depth를 예측하기 때문에 좌우 영상 사이에 occlusion이 발생한다 하더라도 큰 상관 없이 보다 일관성있는 Depth map을 추정하게 될 것입니다.
저자는 이러한 두 학습 방식에 영감을 얻어 Occlusion-aware Fusion 기법을 제안합니다. 해당 방식은 occlusion map으로부터 stereo와 monocular branch들이 추정한 결과를 fusion하는 방식이며 또한 이렇게 fusion된 depth map은 다시 StereoNet에 pseudo label로 사용됩니다.
Self-Supervised Stereo Branch
각 스테이지 별로 보다 자세하게 알아봅시다.
먼저 첫번째 단계에서 저자는 보다 기존에 3D 컨볼루션을 사용하는 것이 아닌, 가벼운 방식의 unsupervised stereo disparity estimation 방법론인 PWCNet 방식을 채택했다고 합니다.
저도 PWCNet에 대해서 잘 알지는 못하지만 입력으로 좌우 영상이 들어간다는 점, 그리고 Unsupervised 방법론이라는 점으로 보았을 때 Optical Flow와 같이 네트워크는 좌우 영상의 관계를 학습하면서 깊이 맵을 추정하고 이렇게 추정된 깊이 맵으로 좌 또는 우 영상을 warping하여 학습하는 것 같습니다.
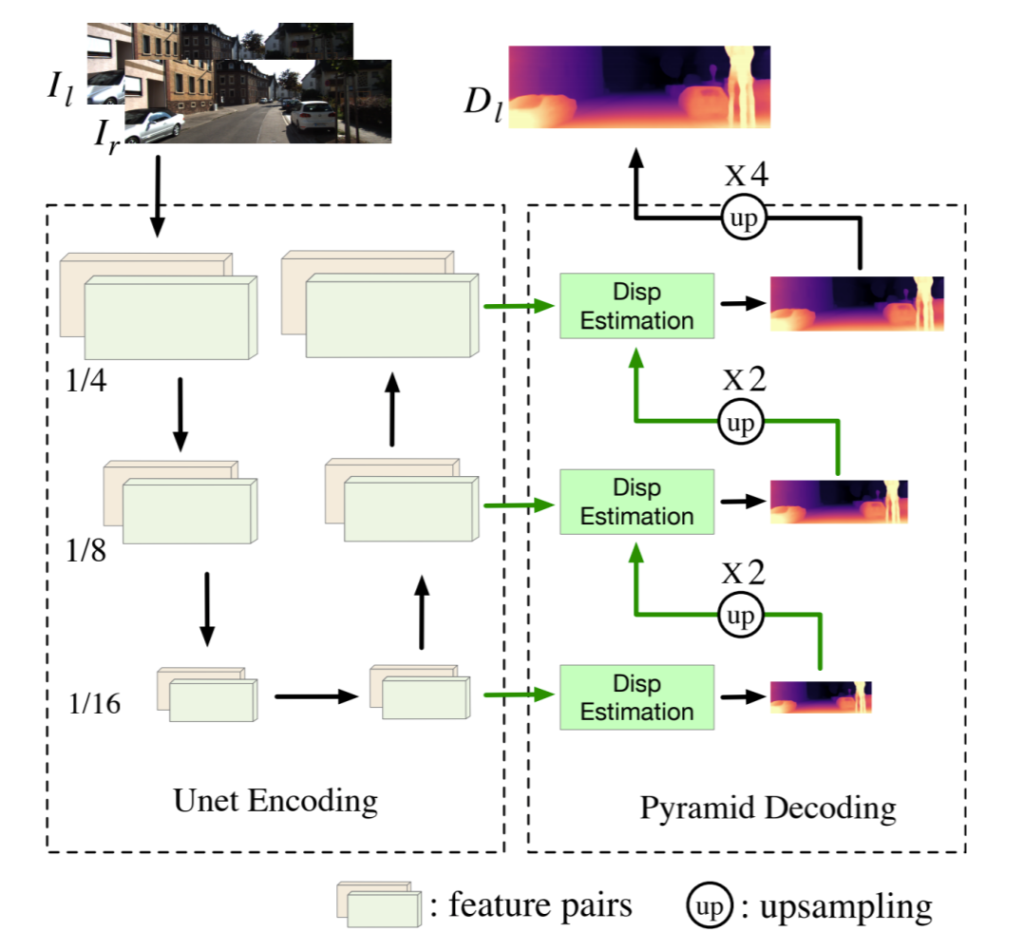
그림2에 StereoNet의 구조가 나타나있습니다. 그냥 평범한 U-Net 구조의 네트워크를 가지고 있는데 간략하게 설명드리면 좌,우 영상 각각이 Unet 인코더~디코더를 거쳐 paired한 feature map을 생성하고 이렇게 생성된 feature map으로Multi scale로 Disparity를 생성합니다. 이 때 참고하실만 한 점은 이전 단계에서 생성된 Disparity map과 그 앞에 단계의 feature map을 fusion함으로써 다음단계의 Disparity map을 만든다는 것이겠네요.
저자는 더 깊은 feature map이 higher-resolution disparity map을 생성하는데 있어 필수적으로 생각하였기에, pyramid encoding stage를 Unet 구조로 바꾸었다고 합니다. Pyramid encoding 구조가 Unet이랑 무슨 차이가있는지는 잘 모르겠네요..? 같은걸로 알고 있었는데 흠..
아무튼 이렇게 구조를 바꾼 것이 성능 향상에 좋은 영향을 끼쳤다고 합니다.
StereoNet이 학습하는 방식은 계속해서 말씀드리지만 warping된 image를 통한 photometric loss로 학습합니다. 물론 좌우 영상은 서로 보는 시야각도 다르고 occlusion도 존재하기 때문에 학습에 사용되는 픽셀들은 시야각에서도 벗어나지 않으며 occlusion이 아닌 픽셀들만 사용하게 됩니다.
occlusion map을 구하는 과정은 다음과 같습니다.
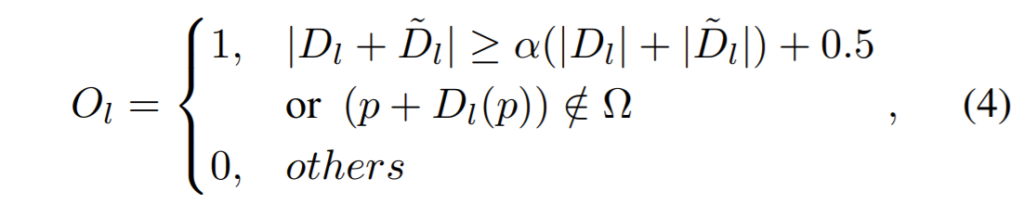
D, \hat{D}는 각각 Disparity map과 warped Disparity map을 의미합니다. 여기서 0.5는 occlusion map을 연산할 때 sub-pixel의 정확도를 보완하고자 사용된 값이며 옴 표식은 image boundary를 의미합니다.
이렇게 추정된 occlusion map을 사용하면 최종적인 photometric loss가 계산이 됩니다.
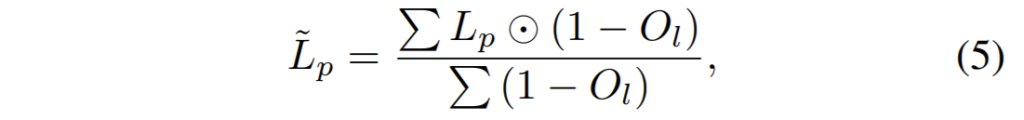
Distilling Monocular Branch
다음으로 2단계에 해당하는 monocular branch를 학습하는 방법에 대해 알아봅시다. 일반적으로 SingleNet도 stereo image를 통하여 깊이 추정을 학습합니다만 StereoNet과 차별점이라고 한다면 SingleNet의 경우 입력이 왼쪽 영상만 들어가고, StereoNet은 좌,우 영상이 함께 들어간다는 점입니다.
그래서 당연하게도 더 많은 입력을 사용하는 StereoNet이 비교적 더 정확한 Disparity map을 생성하게 되기에 StereoNet의 Disparity map을 Pseudo label로 사용해서 Singlenet을 supervised 방식으로 학습하면 될 것 같습니다.
하지만 StereoNet의 한가지 문제가 존재하는데 이는 바로 좌,우 영상에 occlusion이 발생한 지역에서는 부정확한 Depth map이 생성된다는 것이죠. 그래서 저자는 단순히 StereoNet에서 추정된 Disparity를 target으로 SingleNet을 학습시키는 것이 아닌, StereoNet에서 학습하는데 사용한 Occlusion map을 똑같이 적용하여 Occlusion mask가 처리된 Disparity map을 SingleNet의 GT로 사용한다는 것입니다.
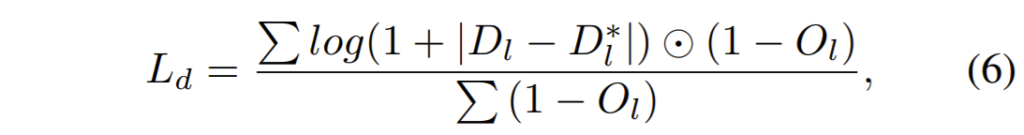
D^{*}_{l}는 SingleNet에서 추정한 왼쪽 영상의 Disparity map이며 저 별이 안붙은 것은 StereoNet의 Disparity map이겠죠. 그리고 뒤에 element-wise product를 통해 Occlusion mask가 적용된 모습입니다.
Distilling Stereo Branch
마지막으로 3단계에 대한 설명입니다.
위에서도 한 말이지만, StereoNet이 SingleNet보다 일반적으로 더 좋은 성능을 보입니다. 하지만 좌우 영상에 occlusion이 발생하여 동일한 대상으로 보이지 않는 부분에서는 좋지 못한 결과가 나온다고 했었죠.
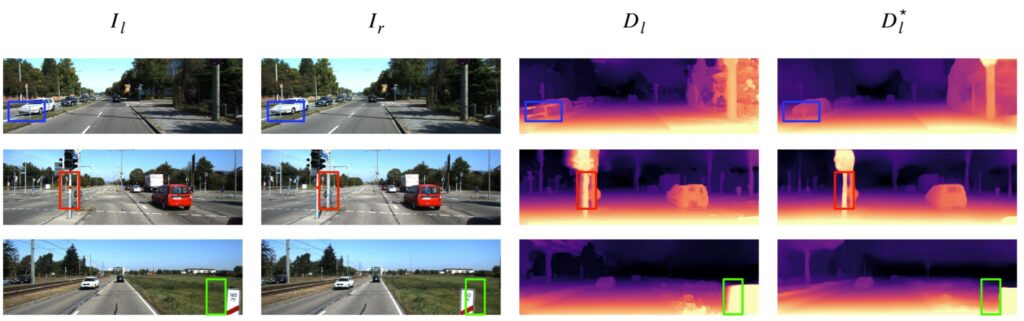
그림3을 보시면 조금 더 한눈에 이해할 수 있습니다. 각각의 열은 순서대로 왼쪽 영상, 오른쪽 영상, StereoNet의 결과, SingleNet의 결과를 정성적으로 보이고 있습니다. 좌, 우 영상이 baseline 차이로 인하여 시각이 달라지고 이로 인해 occlusion이 발생하게 될 경우 생성된 Disparity map이 smooth하지 못하거나, blur한 현상을 확인할 수 있습니다.
반면 SingleNet의 경우 영상 자체를 보고 Depth를 추정하다보니 비교적 선명하게 추정하고 있습니다.
이러한 결과를 통해 저자는 StereoNet이 일반적으로는 더 성능이 좋지만, occlusion이 발생하는 등의 상황에서는 SingleNet이 더 좋기 때문에 이 둘을 상호관계로 보고 학습하면 두 네트워크 모두 성능이 향상된다고 판단한 것이죠.
그래서 StereoNet의 성능을 더 향상시키고자(StereoNet의 성능향상은 곧 SingleNet의 성능 향상을 의미합니다.), 두 네트워크에서 추정된 Disparity map을 fusion시키는 Occlusion-aware Fusion module을 제안합니다.
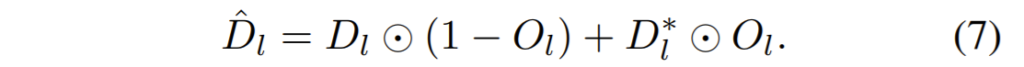
위에 수식을 통해 Fusion된 Disparity map을 생성하게 됩니다. 상당히 간단한데, Occlusion 영역이 아닌 부분에서는 StereoNet이 더 좋으니 해당 부분을 사용하겠다는 것이며, Occlusion이 있는 영역의 Depth는 SingleNet에서 생성된 Depthmap을 사용하겠다는것으로 보이네요.
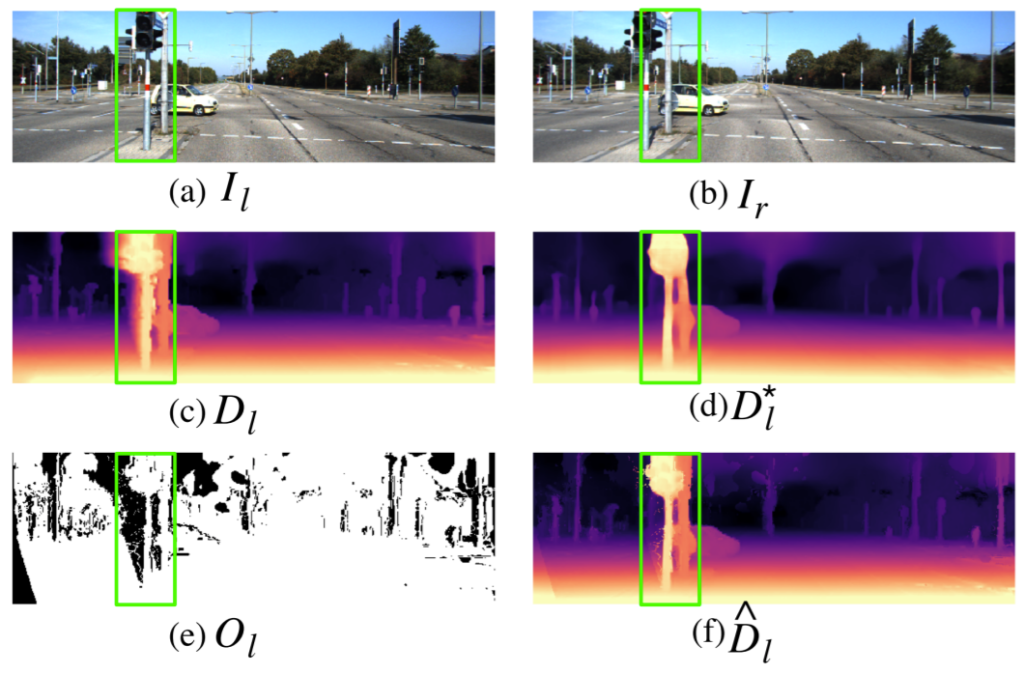
그림4를 살펴보시면 기존 StereoNet의 Sharp한 깊이맵과 occlusion 영역에서는 보다 smooth한 singlenet의 깊이맵을 동시에 취득하여 선명한 Depth map을 만들었다고 하네요. 중간중간에 노이즈가 있는 것이 조금 마음에 안들지만… 이렇게 fusion된 depth map을 다시 StereoNet에 Supervised 방식으로 재학습시킴으로써 StereoNet의 정확도를 더 보완하게 됩니다.
Experiments
먼저 Stereonet의 정량적 결과부터 살펴보시죠.
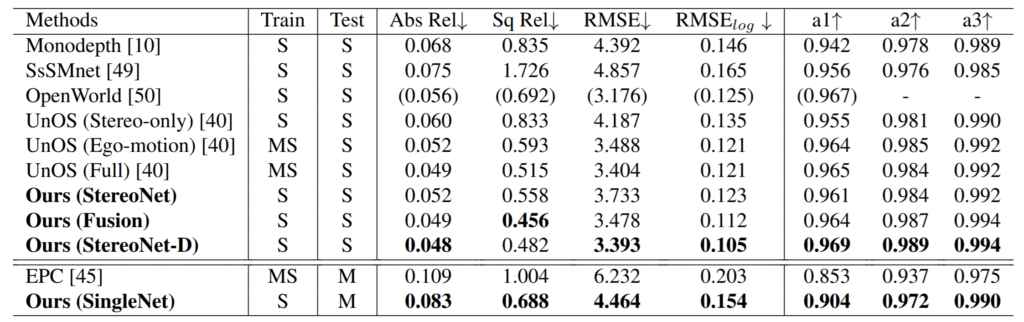
StereoNet은 1번째 stage만 학습시켰을 때 결과를 의미하며, StereoNet-D가 Fusion된 Disparity map으로 재학습시킨 결과를 의미합니다. 확실히 Stereo 방법론들은 monocular 방법론들과 비교하였을 때 성능 차이가 확연히 다르네요..
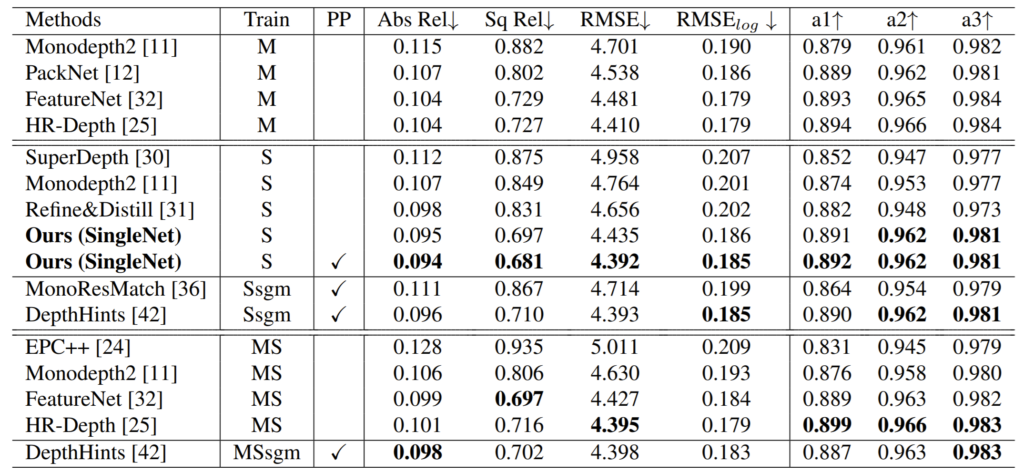
다음으로 단일 영상을 입력으로 하는 monocular 방법론들과의 비교 결과입니다. 표1에서의 Ours(SingleNet)과 달리 pair한 비교를 위해서 1, 2 stage만을 적용하였다고 하네요.
결과로 봤을 때 Abs_Rel와 Sq_Rel이 상당히 큰 격차로 이기고 있는 모습입니다. 근데 사실 해당 방법론의 성능이 뛰어나다고 해서 다른 방법론들보다 더 좋다고 말을 하기 애매한게, 일단 네트워크의 backbone이 Resnet50을 사용하고 있다는 점과 입력 해상도가 1024 x 320이라는 점입니다.
이게 왜 중요하냐면 다른 Stereo 방법론들은 잘 모르겠지만 Monocular 방법론들의 경우 Resnet-18 backbone을 주로 사용하며 입력 해상도 역시 해상도가 더 높아지면 모든 메트릭에서 성능이 향상될 수 밖에 없는게 사실입니다. 그러한 관점에서 볼 때 해당 방법론이 정말로 우수해서 성능이 좋은건지 의심이 되는 부분이네요.
또한 해당 표에는 없지만 2020? 2021? CVPR에 나왔던 PLADE NET이라고 있는데 해당 방법론은 KITTI에서 Abs_Rel 0.092, Sq_Rel 0.626, Rmse_log 0.175로 저자가 제안하는 방법론보다 훨씬 더 좋은 결과를 보이고 있습니다. 그것도 입력 해상도 640×192임에도 불구하구요.
그렇다고 Ablation Study에서 Backbone이 Resnet-18일 때와 Input Resolution을 640×192로 하였을 때 어떤지에 대한 결과 리포팅도 없으며 자신들의 실험 세팅에 대해 논문에서만 잠깐 언급할 뿐 테이블에서는 마치 공정한 평가에서 자신들이 제일 좋은 SOTA 방법론이다 인것처럼 표기하는 모습이 조금 아쉬운 논문이었습니다.
결론
실험 부분에서 다소 해당 논문을 까내리는 듯? 했지만 그래도 아이디어는 좋은 것 같습니다. 입력 자체를 Stereo 이미지로 활용한 StereoNet의 Depth map을 Pseudo Label로 사용해서 학습했기 때문에 warping할 때만 Stereo 이미지를 활용하는 다른 stereo training 방법론들보다 성능이 당연히 좋을 수 밖에 없었을 것입니다. 그치만 학습할 때 스테레오 이미지를 활용한다는 점에서는 모두 공통점이기 때문에 저자가 제안하는 방법론이 조금 더 의미를 가졌을 지도 모르겠네요.(동일한 input과 backbone으로 비교한 것이 맞는지 의심스럽지만 흠..)
학습 방식이 굉장히 특이하네요 . 기존에 알던 방법이랑 매우 다른 느낌… 뭔가 Stereo 방식은 원래 저렇게 싶네요. 공부할게 참 많군요