안녕하세요 제가 이번에 가지고온 주제는 지난번에 이어서 YOLO 시리즈 입니다. 특히나 이번에 소개드릴 논문은 가장 최신인 YOLOX 이므로 관심이 있으신 분들은 한 번 쯤 읽어보시기 바랍니다.
먼저, 바쁘시고 YOLO시리즈에 크게 관심이 없는 분들을 위해서 핵심부터 말해보겠습니다. YOLOX에서 가장 핵심적인 변화는 바로 head를 Decouple했다는 점 입니다. 이게 무슨소리냐면, 욜로 모델이 있으면 FPN 구조로 기존에는 grid를 형성하고 해당 grid cell마다 bbox에 대한 정보와 object인지 아닌지를 나타내는 확률값과 class에 대한 확률값이 들어 갔습니다. 그런데 이러한 것들을 한개의 grid맵에서 하는게 아니라 decouple화 하여 여러개로 나누어서 수행한다는 것이 바로 핵심입니다. 그 외에도 테크니컬한 요소들이 상당히 많은데 이는 아래 설명들에서 다루겠습니다.
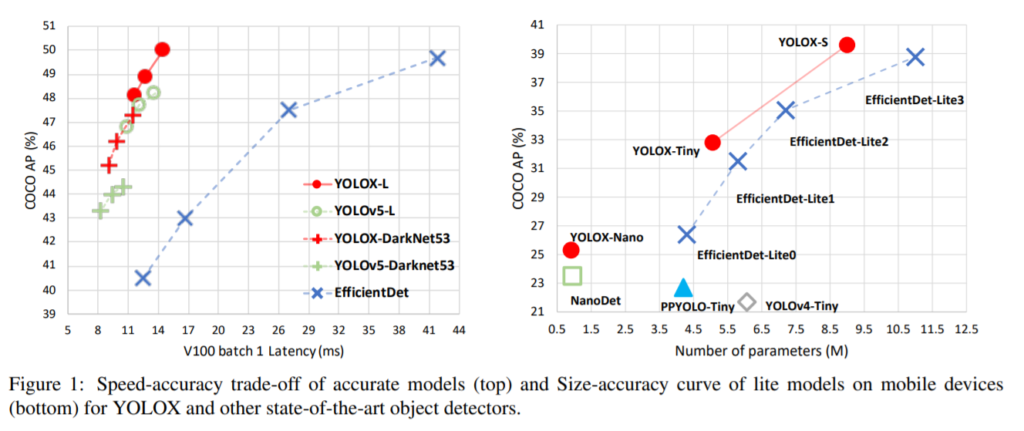
성능에 자신이 있었던지 해당 논문은 1페이지에 대문짝 만하게 해당 그래프를 명시해두었습니다. 실제로도 성능과 속도 모두 잡은 진보된 모델임을 알 수 있습니다. 더 적은 파라미터를 쓰고 더 좋은 성능을 낸 샘입니다.
다들 아시겠지만 욜로시리즈는 원저자가 더이상 욜로시리즈를 개발하지 않습니다. 심지어 컴퓨터비전에서도 손을 떼었다고 들었는데요. 원저자는 yolov1~v3이후로 더이상 업데이트를 안하고 있으며, yolov4화 v5 그리고 이번에 리뷰하는 논문인 x는 모두 다른저자에 의해서 연구가 진행되었습니다. 대부분의 아키텍처들이 원저자가 마지막으로 남긴 yolo-v3를 기반으로 조금의 변형을 넣어서 성능개선을 하는식으로 발전을 이루어왔습니다.
그래서 해당 논문을 이해하려면 yolo v1~v3에 대한 이해가 필요합니다. 제가 리뷰해둔글이 있으니 찾아서 읽어보시거나, 구글링하면 좋은 자료들이 많이 나오니 한번 살펴보시기를 추천드립니다.
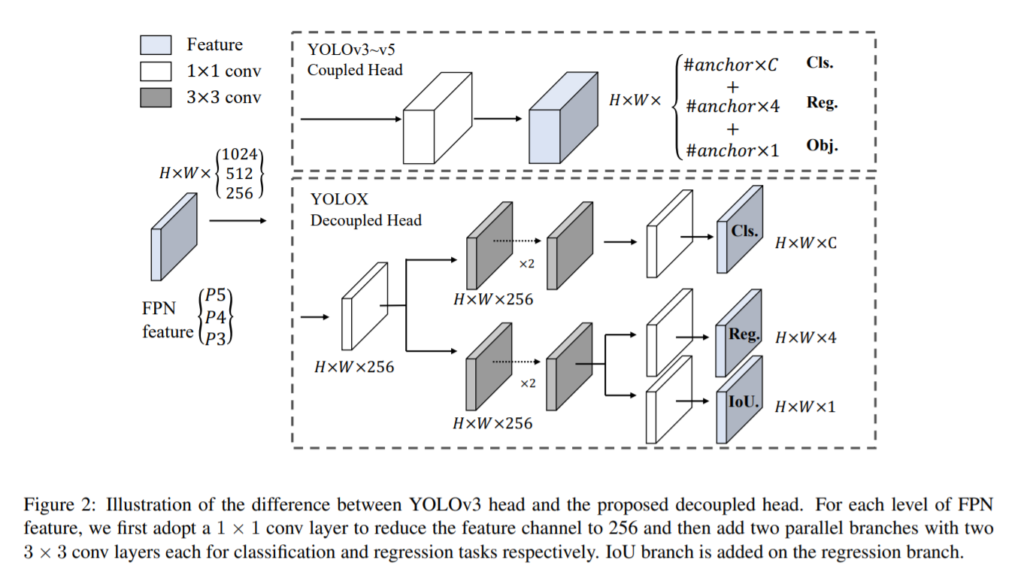
자 이제 본격적으로 아키텍쳐에 대한 소개부터 시작해보겠습니다. 아키텍쳐는 yolo v3를 기반으로 하였다고 명시해두었습니다. 그래서 바뀐부분만 위의 그림에 나타내었습니다. 맨위에 yolo v3~v5는 Coupled Head를 사용하였지만, 해당 논문에서는 해당 부분을 decouple하여 decoupled head를 사용하였습니다. 말 그래로 한개의 grid cell에서 모든 작업을 수행하였었던것을 나누어서 수행한다는 뜻 입니다. 이때, 차원을 줄이기 위해서 NiN (1by1 convolution)을 사용합니다. NiN기법은 SSD나 Halfway, 최신 SOTA근처 방법론들에서까지도 범용적으로 사용되는 대표적인 채널차원 줄이는 방법이기에 설명은 생략하겠습니다.
어찌됐든 핵심은 위의 그림처럼 기존에 coupled되어있던 head를 decouple했다는점하여 bbox Regression과 IoU 부분을 따로 두었다는 점 이고, 해당 IoU부분에서는 IoU loss를 추가적으로 사용합니다.
즉 기존에는 grid map에서 Channel 정보에 x, y, w, h, o, cls1, cls2 … 이런식으로 normalize된 상태에서 bbox에 대한 coordinate 정보가 coco format으로 들어가고, object 인지 아닌지를 나타내는 score인 o와 class의 갯수만큼의 prob값을 channel정보에 담고 있습니다. 그러나 decoupled된 해당 논문에서 제안하는 아키텍쳐에서는 이와 같은 정보가 분리되어 있으며, object인지 아닌지를 나타내는 score가 없고 IoU를 나타내는 값이 있습니다. 이유에 대해서는 아래에서 다시 설명하겠습니다.
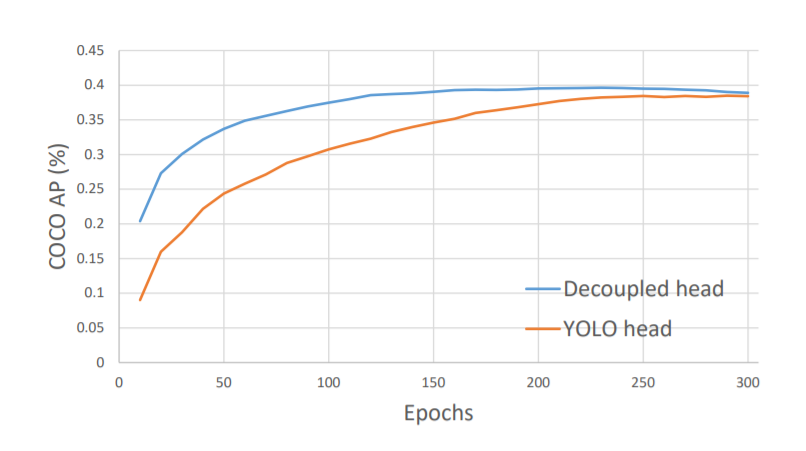
그래서 이렇게 decouple된 head를 사용하는 것 만으로도 위와 같은 성능 향상이 있었습니다. 뭔가 수렴했을때는 비슷한거 같긴한데 그래도 전반적으로 성능향상이 있는거 같기는 하네요.
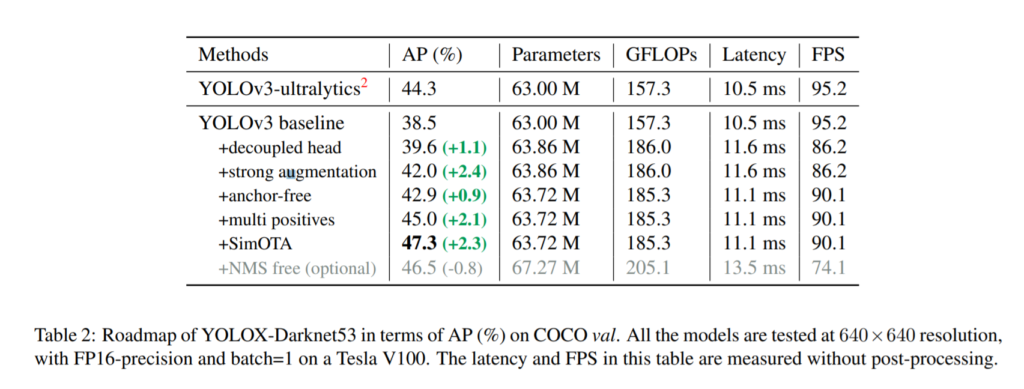
위에서 제가 설명한 decouple head말고도 엄청 많은 모듈들이 추가가 되었습니다. 위의 성능에 대한 ablation study 결과표를 보시면 그 방법론들에 대한 이름들이 나와 있습니다. 이렇게 baseline인 yolov3에 엄청 많은 실험을 하여 성능을 최대로 끌어올리는 식으로 최대성능을 끌어냈습니다. 그리고 yolov4를 python으로 원복한 오픈소스중에서 가장 성능이 좋다고 알려진 ultralytics와 비교를 하였고, 모든 모듈들이 추가되었을때 약 3프로정도 성능이 더 높았습니다.
그럼 이제 strong augmentation, anchor-free, multi positives, SimOTA에 대해서 알아보겠습니다.
먼저 Strong augmentation은 기존 yolo 시리즈 들에서도 많이 사용되는 방법들입니다. 다만 augmentation을 강하게 주었다고 하여 strong augmentation이라고 명명하였습니다. 저자가 실험을통해 yolo-tiny 같은 파라미터 갯수가 적은 경우에는 augmentation을 약하게 주는게 오히려 좋은 성능을 보인 반면에 yolo-large같은 경우에는 그 반대의 케이스가 나왔습니다. 저자는 최종적으로는 backbone의 parameter가 큰것을 사용하였기 때문에 결과론적으로는 strong augmentation을 사용하였습니다. Object detection에서 최신 유행하는 Mosaic, MixUp 과 같은 augmenation들을 사용하였고, 300에포크를 학습하는 과정에서 마지막 15에퐄은 해당 augmentation기법들을 제거한 상태로 튜닝하여 최종 성능을 뽑았습니다. 이렇게 strong-augmentation을 사용함으로써 모델을 학습시키면 ImageNet pre-train을 하는 이유가 별로 없다고 판단이 되어서 scratch 부터 학습을 했다고 합니다. epoch수가 높은것도 아마 그 이유 때문인거 같습니다.
다음으로는 anchor-free에 대해서 설명해보겠습니다. 사실상 굉장히 간단한 방법으로 anchor-free를 만들었습니다. 기존의 yolo시리즈들은 물체의 w, h를 다 추출하고 해당 w, h 를 클러스터링하여 9개의 center좌표를 뽑아내고 해당 좌표를 anchor box의 size로 사용하였습니다. 해당논문에서는 이러한 과정을 생략하고, head에 calculation 부담을 줄이기 위해 anchor free로 바꾸었습니다. anchor free로 바꾼 방법은 사실 굉장히 간단합니다. 기존에서는 3개의 grid map를 뽑고 grid맵 마다 한개의 grid cell에서는 3개의 anchor boxes를 만들었습니다. 이러한 3개의 anchor boxes의 개수를 1개로 줄여서 directly regression하는 방식으로 anchor-free 형태로 바꾸었습니다.
또한 기존 yolo 시리즈는 object의 centre가 있는 prediction들 중에서 IoU를 기준으로 1개의 anchor box를 positive로 설정을 하고 나머지는 loss term에는 관여를 하나 prediction으로 사용하지는 않는 그런 특성이 있습니다. 이와 마찬가지로 해당논문에서도 center좌표 주변 3×3 셀에 속하는 영역을 포함하는 prediction을 positive로 두고, 나머지 는 gradient 계산을 하여 loss term에만 관여하는식으로 사용합니다.
마지막으로 simOTA는 해당 저자들이 연구한 OTA를 간략화 한 것입니다. OTA란 Advanced label assignment 방법으로 좀 더 label을 부여하는 방식에 있어서 진보된 방법을 택한다는 것 인데요. 자세한건 직접 reference논문을 읽어봐야 할거 같긴한데 이번 리뷰에서는 해당 내용은 본 논문에서 소개하는 depth정도로만 다루겠습니다. 어찌됐든 Advanced label assignment을 위해서는 아래처럼 4가지 요소가 있는데요.
- 1). loss/quality aware
- 2). center prior
- 3). dynamic number of positive anchors for each ground-truth (abbreviated as dynamic top-k)
- 4). global view
이를 모두 고려하면 약 25%정도 속도가 더 걸렸다고 하여 이를 단순화하고 비슷한 속도를 낼 방법을 찾다가 결정한게 바로 simOTA입니다.
simOTA 에서는 dynamic top-k strategy를 사용하여 해당 4개에 대한 고려를 모두 하지 않고 근사하는데요. 아마도 이런방법을 택한 이유는 top-k를 사용하는게 영향이 젤 크기 때문인거 같습니다.
즉 prediction이 있으면 prediction의 centre값이 같은 grid cell안에 속하는 prediction중에 gt와의 오버랩을 비교하고 그중에 가장 높은 k개의 prediction을 positive로 나머지는 negative로 설정을 합니다.
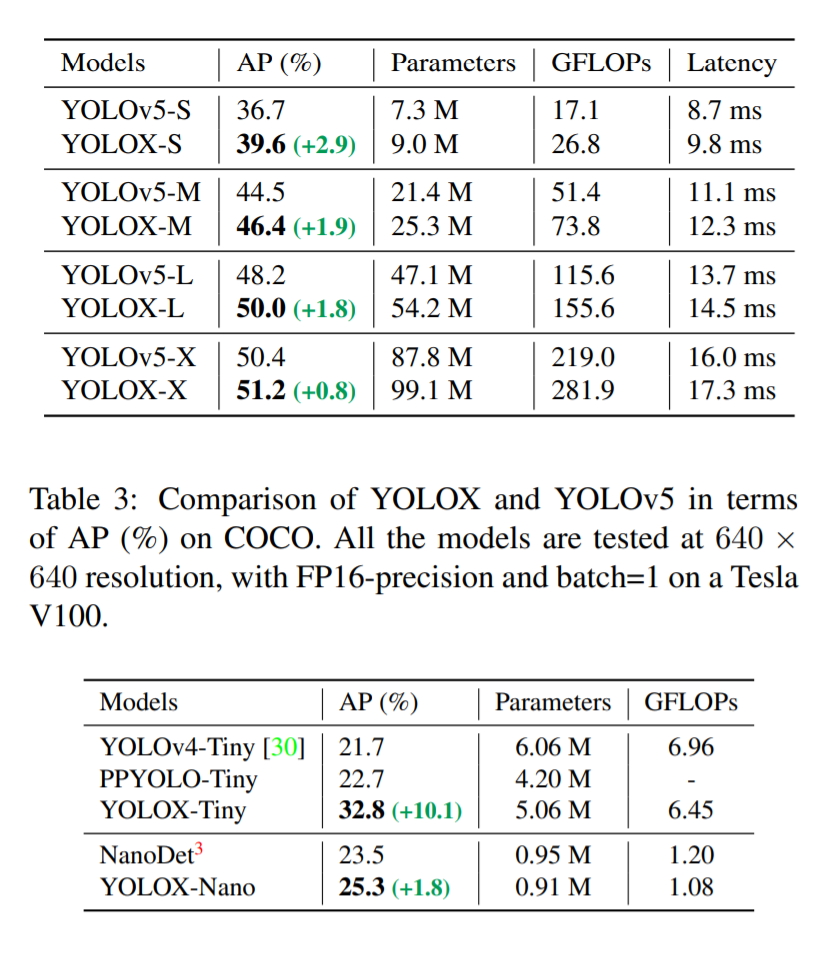
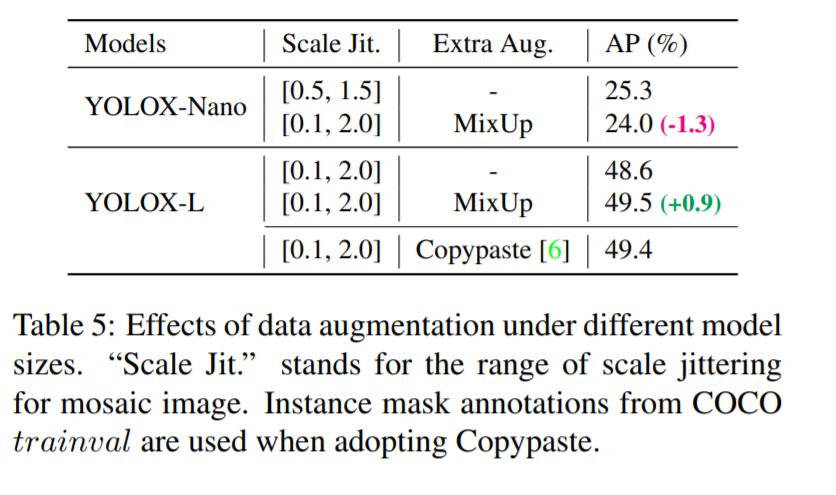
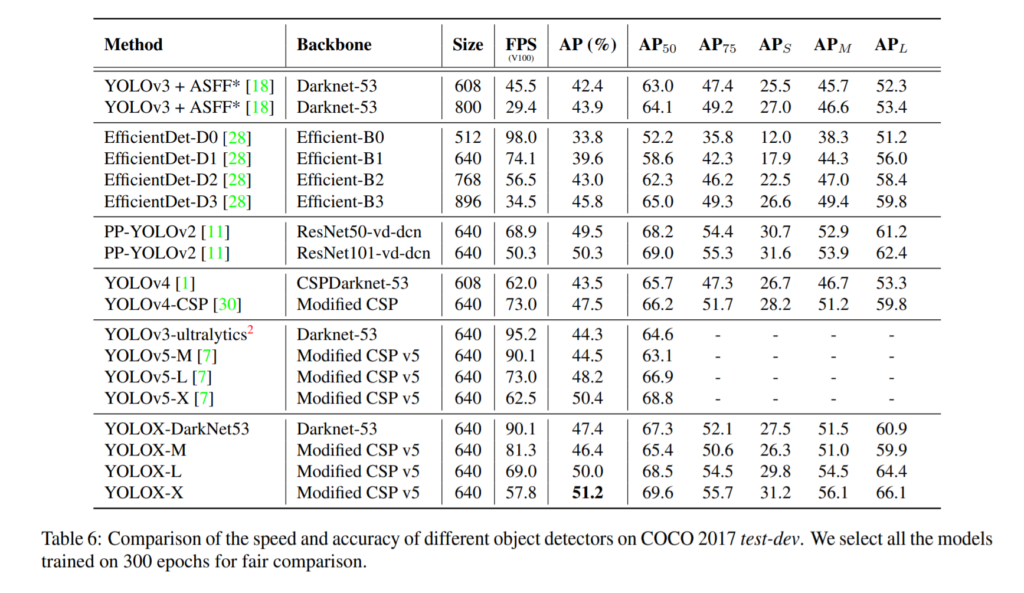
실험이 굉장히 많은데요. 욜로시리즈 들을 읽으면 느끼는게 굉장히 테크니컬한 방법들이 많이 들어간다는 것 입니다. 그냥 최근에 유행하는 좋은 것들을 다 짜깁기 시켜두었단 느낌을 많이 받습니다. 원저자가 yolo v3를 출시하면서 최신 기법들에 대한 실험을 엄청 많이 진행하여 성능을 극대화 시켰었는데, 이를 베이스라인으로 추가적인 최신기법들에 대한 실험을 통해 yolo v4~X까지 진보해온거 같습니다. 이번 yolo-x에서도 실험이 굉장히 많고 구체적이다는 것을 느끼게 되네요.
- 흥미로웠던점은, Head를 Decouple화 하였다는점
- Anchor Free만드는게 생각보다 간단하게 구현된단점
- 백본의 파라미터 개수에 따라서 augmentation 정도를 다르게 설정했단점
- augmentation이 강하게 적용되었을때는 ImageNet Pre-trained 모델을 불러오는 것 보다 scrach부터 학습하는게 더 좋은 결과를 가지고 왔단점
- 마지막 에폭 15는 augmentation없이 학습했단점
으로 요약할 수 있을거 같습니다.
이상 리뷰 마치겠습니다. 질문은 댓글로 남겨주세요.
안녕하세요 김형준님 yolo v1~v3 리뷰에 이어서 yolo x 에 대한 형준님의 리뷰를 읽게 되었습니다.
논문 첫 페이지에 첨부된 성능표에서 yolo x는 Table 2의 방법론을 모두 더했을 때의 성능인가요? 또한 head를 decoupling 한 것이 어떻게 더 빠른 수렴 속도를 낼 수 있었는 지가 궁금합니다. 또한 앵커박스의 개수가 줄어들면 검출 성능이 떨어질 수도 있을 것 같은데 줄이고서도 더 향상 시킬 수 있었던 이유도 궁금합니다. 감사합니다.