이번 ICCV에서 visible-Infrared 관련 연구들을 찾다가 조금은 다른 분야이지만 그래도 새로운 방법을 제공하고 있고, 이러한 방법이 저희 연구에도 적용될 수 있을것이라고 생각돼 읽게됐습니다.
Github : https://github.com/mangye16/Cross-Modal-Re-ID-baseline
Paper : https://openaccess.thecvf.com/content/ICCV2021/papers/Ye_Channel_Augmented_Joint_Learning_for_Visible-Infrared_Recognition_ICCV_2021_paper.pdf
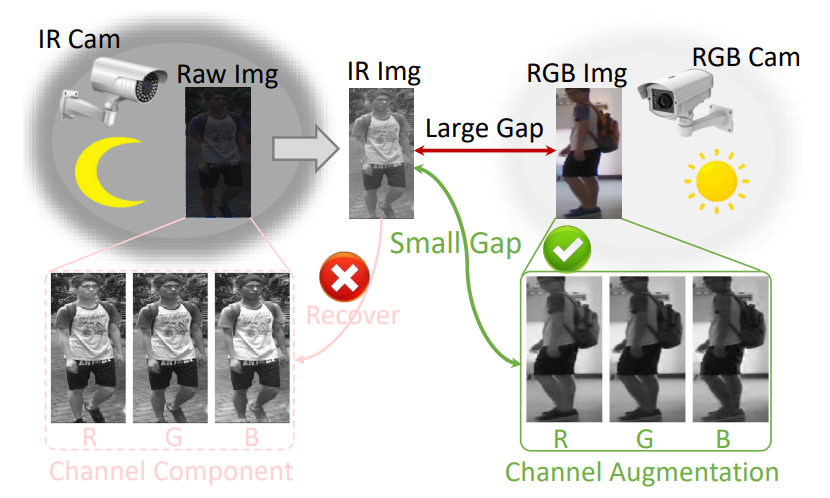
해당 논문은 IR Cam에서 취득된 Infrared 이미지와 RGB Cam에서 취득된 RGB 이미지 속 인물이 동일 인물인지 아닌지 Recognition하는 문제로, Infrared 영상 관련 연구 중 현재 가장 실용도가 높은 연구가 아닐까 생각합니다. (실제 매년 이쪽 연구는 계속 논문이 발표되고 있습니다.) 이번 ICCV2021에 동일한 주제로 IPIU에서 자주 뵐 수 있었던 연세대 함범섭 교수님 연구실에서도 논문을 제출하였는데, 해당 논문보다는 오늘 리뷰할 논문이 성능도 높고 아이디어도 간단하여 저희 연구에도 쉽게 적용해볼 수 있을거라고 생각돼 본 논문을 선택하였습니다.
제가 생각한 해당 논문에서의 간단하면서도 핵심이 되는 아이디어는 ‘Channel Exchangeable Augmentation’ 입니다. 해당 방법은 어떤걸까요?
위에 그림처럼 일반적으로 infrared 이미지는 1채널, RGB는 3채널의 영상을 이룹니다. 많은 연구들이 1채널의 infrared 이미지를 가지고 3채널의 RGB영상을 만들려고하지만 실제 이는 쉽지 않습니다. 해당 논문에서는 이러한 것을 해결할 수 있게 하기위해서 RGB영상을 R,G,B 3채널의 영상으로 보고, 각 채널에 대해서 독립적으로 Recognition task를 수행할 수 있도록하는 augmentation을 제안합니다. 이를 수식으로 확인하면 더욱 명확해지는데,
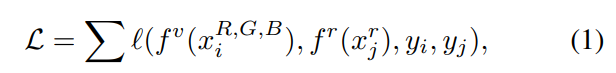
기존 연구에서 Loss르 계산하는 방식을 보면 f가 feature 를 extractor하는 네트워트라고 할때, 일반적인 연구는 3채널의 RGB 영상에서 feature를 추출하고, infrared 이미지에서 feature를 추출하고 이를 라벨과 함께 loss를 계산합니다. 하지만 해당 논문에서는 RGB의 3채널 영상을 아래와 같이 3채널 모두 동일한 R or G or B로 랜덤하게 변경하는 방법을 제안합니다.
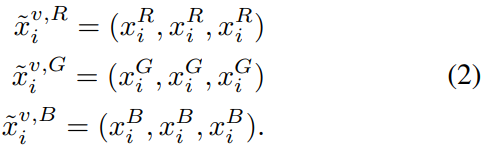
즉, 기존 R,G,B 모두가 모여서 3채널의 이미지였던 것을 R,R,R 혹은 G,G,G 혹은 B,B,B 와 같이 랜덤하게 R,G,B 중 하나의 채널만 선택하여 Loss를 수정하는 ‘Random Channel Exchangeable Augmentation(CA)’이라는 방법을 제안합니다. 그리고 이 방법은 기존 제안된 방법 및 Data agumentation 에도 코딩적으로 문제없이 통합이 가능한 특징을 가지고 있습니다. 이러한 CA를 통해 나오는 영상을 확인해보면 다음과 같습니다.

이러한 CA는 간단하면서도 핵심이 되는 해당 논문의 아이디어 입니다. 저자는 이를 통해서 RGB의 각채널과 infrared 이미지를 가장 명확히 매칭시킬 수 있다고 이야기합니다. 따라서 앞서 설명했던 (1)번의 수식이 해당 논문에서는 다음과 같이 변경되며, 앞서 말씀드렸지만 해당 방법은 기존의 네트워크에도 바로 적용이 가능한 방법입니다.
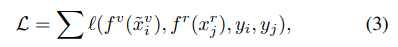
(1) 수식과 비교하였을때 RGB 채널을 모두 이용하여 Feature를 추출하던 것과 다르게 본 논문에서는 랜덤으로 1채널을 선택하여 feature를 추출하거나, 혹은 가끔씩은 모든 채널을 모두 이용하여 RGB feature를 추출하기도 한다고 합니다. (랜덤으로 선택)
What is CA doing?
본 논문은 ICCV에서 발표된 논문이고, 앞선 방법은 쉽게 사용할 수 있는 방법이라 해당 방법만 가지고 성능을 향상시켰다고 논문을 작성하고, 논문이 억셉되기에는 부족함이 있다고 느껴질 수 있습니다. 해당 논문에서는 자신들이 제안하는 CA 즉 channel exchangeable augmentation 방법이 어떠한 작용을 하는지 분석적으로 논문에서 나타내고 있습니다.
가장먼저 저자는 자신들의 CA 방법이 color variations에 robustness한 학습이 가능하다느 것을 증명하기위해 pairwise positive similarity score와 negative similarity score distribution를 다음과 같이 시각화 합니다.
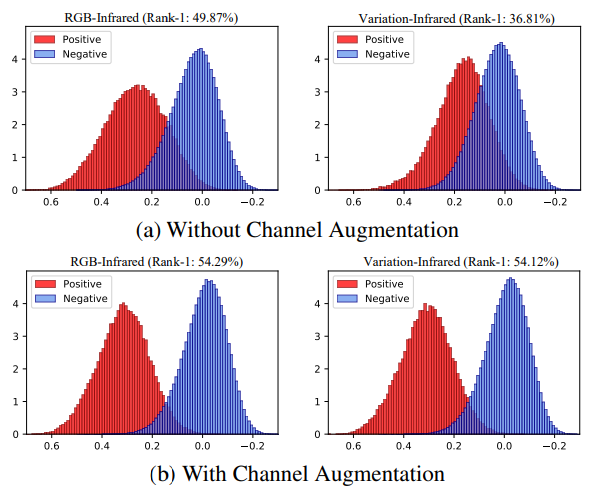
위의 그래프에서 x축은 cosine similarity sccore를 y축은 a normalized value for each quantized similarity bin of 10000 randomly selected positive/negative matching pairs를 나타냅니다. 또한 variation이란 RGB 영상에 랜덤하게 grayscale transformation 또는 channel augmentation을 적용한 것을 의미합니다. 즉 다시 설명하면 CA를 적용했을때 RGB 영상과 Variation 영상을 infrared와 비교하면 동일한 경향성을 나타내므로 robusness하다고 할 수 있습니다. 이러한 실험을 통해 저자는 다음과 같은 결론을 얻을 수 있었다고 합니다.
- Channel augmentation enhances the invariance for the positive matching pairs
- Channel augmentation also introduces a larger difference for the negative matching pairs
- The proposed channel augmentation greatly improves the representation robustness against color variations
두번째로 CA방법이외에 저자는 ‘Channel-Level Random Erasing’이라는 방법도 제안합니다. 해당 방법은 이름에서 알 수 있듯, 채널레벨에서 Random으로 Erasing을 하겠다는건데요. 아래 그림을 보시면 바로 이해할 수 있습니다.

해당 방법은 많은 연구에서 사용하고 있는 방법이기때문에 따로 설명하진 않겠습니다. 이러한 방법은 partial occlusions, imperfect detections와 같은 noise에 대해서도 강인성을 향상시켜준다고 합니다.
Cross-modality Metric Learning
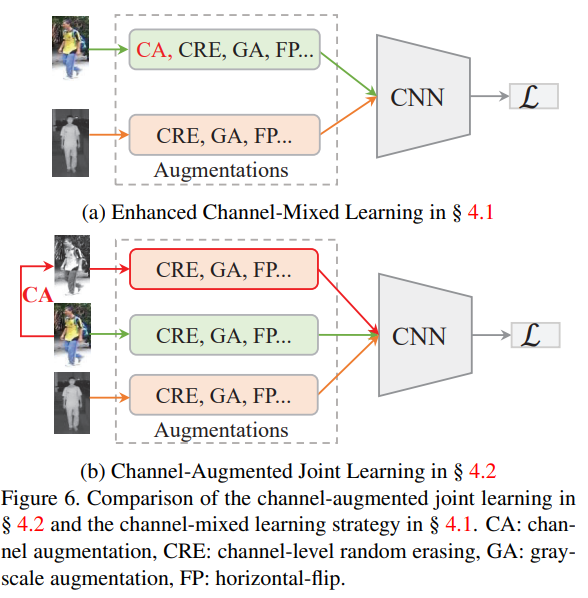
기존 연구에서는 Cross-modality metric learning을 위해 RGB,infrared feature 가 유사해지도록 bi-directional triplet variants를 cross-modal positive and negative pair에 적용했다고 합니다. 하지만 저자는 이러한 방식은 각 모달라티의 cross(inter)-modality variations은 도움이 되지만 intra-modality variations에는 효과적이지 못하다고 이야기합니다. 저자는 intra- and cross-modality variations를 다루기 위해서 channel-mixed learning strategy와 Channel-Augmented joint learning을 제안합니다. (두 방법은 본인들의 CA가 합쳐지면서 기존의 방식에서 개선되는 동시에 joint learning의 경우 CA를 통해 만든 새로운 영상도 함께 학습시키는 학습 방식을 의미합니다. )
Experimental Results
VI-ReID 분야에서는 SYSU-MM01, RegDB 데이터셋이 가장 유명한 퍼블릭 데이터셋으로 이 둘 데이터세을 기준으로 성능을 겨루고 있습니다. 본 논문도 이 둘 데이터셋에 성능을 리포팅하였고 SoTA를 달성합니다.
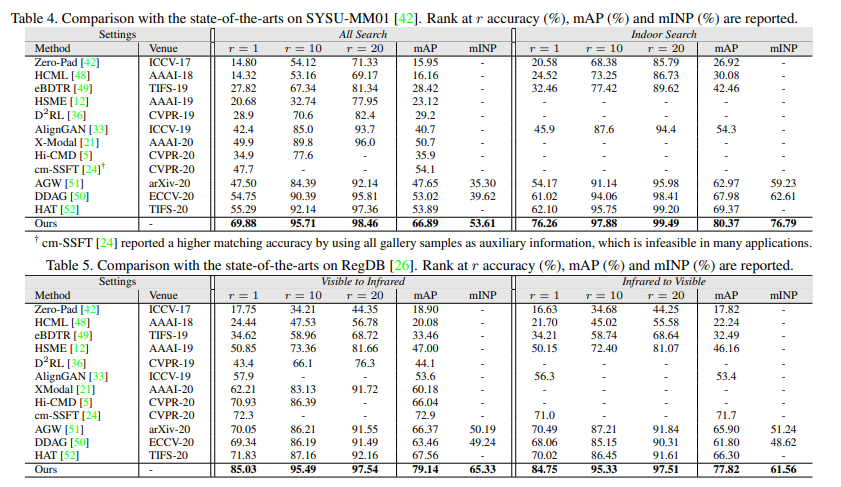
참고로 앞서 설명드린것처럼 이번 ICCV2021에 함께나온 연세대 함범섭 교수님 연구실에서 나온 논문의 테이블을 함께 살펴보면 해당 논문이 얼마나 높은 성능을 나타냈는지 확인할 수 있습니다.
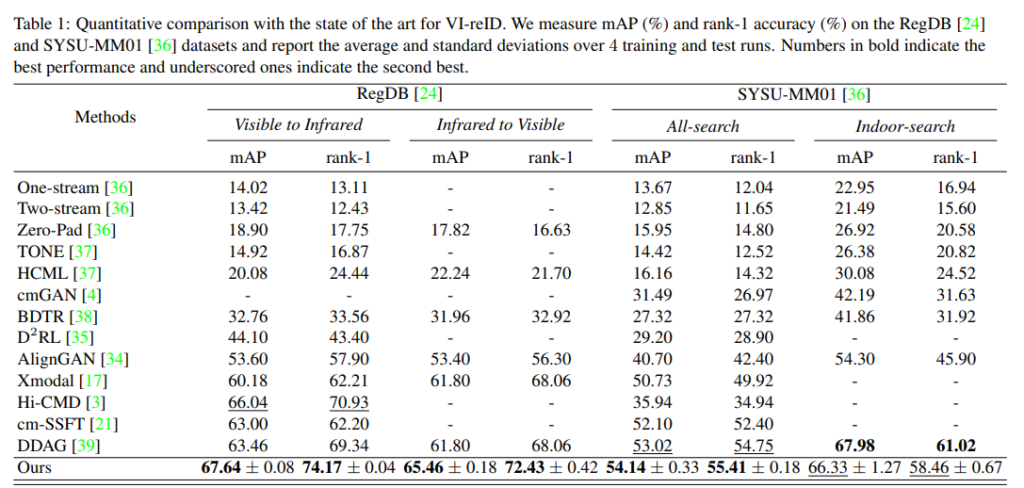
또한 해당 논문은 Vi-ReID 분야 뿐만아니라 Face recognition 분야에서도 성능다음과 같이 성능향상을 가져왔습니다.
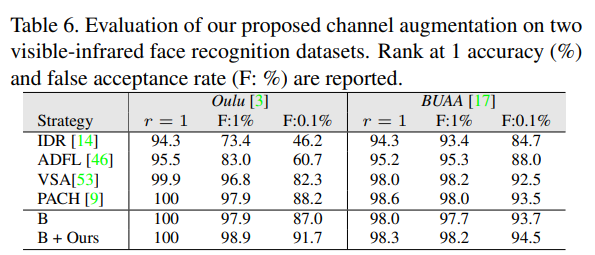
기타 Ablation study등을 통해 자신들의 방법이 단순하지만 강력함을 이야기합니다.

결론
해당 방법론은 NIR에서 실험을 진행했지만 FIR에서도 적용하면 성능향상되는지 확인해보는것도 좋을 것 같습니다.
리뷰 잘 읽었습니다.
리뷰 내용 중 그림6이 이해가 잘 되지 않네요. 그림6에서 말하는 (a)와 (b)는 각각 어떤 차이인가요? 동시에 사용했다는 것인지, 아니면 기존의 방법론들은 (a)라면 저자가 제안하는 방식은 (b)라는 것인지 잘 모르겠네요.
(a)와 (b)모두 제안하는 방법이며, ablation study의 테이블을 보시면 가장 마지막에 joint learning을 적용한것 (J표시가 있는것)이 가장 좋은 성능을 나타냅니다. 두 방법의 차이로는 (a)의 경우 RGB와 infrared만의 비교로 모델이 recognition을 수행한다면 (b)의 경우 RGB, infrared, CA한 영상 모두를 통해 intra-inter loss를 결합해 학습할 수 있습니다. 그래서 가장 좋은 성능을 나타낸것이구요. 즉 (a)의 업그레이드(?)가 (b)라고 생각하시면 됩니다.
IR와 컬러 영상의 차이가 간단한 영상 처리로도 좁혀진다니, 정말 흥미로운 연구 내용인 것 같습니다.
해당 태스크에 대한 지식이 부족해 내용 중 Cross-modality Metric Learning에서 Joint learning에 해당하는 내용이 이해가 가지 않습니다. 제가 아는 joint learning은 다른 태스크를 결합하여 학습하는 방법인데… 이쪽으로 생각을 맞추고 봐도 잘모르겠습니다..
기회가 된다면 읽어보시는것도 추천드리며, 준비해서 다음 세미나때 이야기드리겠습니다.
person re-identification 을 thermal 카메라를 도입해서 밤에도 가능하게 한 논문이라고 이해했습니다. data aug는 그냥 repeat함수를 사용해서 한거라 이해하면 될까요?
저희가 알고있는 long wave를 갖는 Thermal 카메라와 다르게 해당 논문에서 사용하는 infrared camera는 Near wave를 갖으며, 따로 카메라에서 빛이 나갑니다. repeat 함수는 어떤걸 이야기하시는지 모르겠으나, 해당 저자가 공개한 코드를 보시면 쉽게 작성되어있어 충분히 확인해보실 수 있을것이라고 생각합니다.