매번 Self-supervised monocular depth estimation만 가져오니 지루한 것 같아서 이번에는 변화구로 밤에도 Depth를 촬영하기 위한 방법론을 가져와 봤습니다. Domain Adaptation 방법론을 이용해서 낮과 밤의 feature가 유사해지도록하는 방법입니다. 사실 다들 이렇게 하면 논문이 될 것이라 생각하지만 하지 않았던 방법론들 중 하나인 것 같습니다. 심지어 ICCV이니… ㅋㅋ 생각한건 실천해야할 것 같습니다.

위 그림과 같이 낮영상을 이용해서 학습한 모델을 통해 밤영상을 inference 할 경우 b와 c 같이 성능이 나오지 않게 됩니다. 이 논문은 domain adaptation을 활용해서 e와 같이 어느정도 depth을 예측 할 수 있도록 만들었습니다.
이 논문의 contribution은 다음과 같습니다.:
- domain separate 방식을 통해 All day depth estimation을 진행합니다. illumination에 상관없이 texture 정보를 통해서 밤에도 낮과 같은 성능을 보여주는 framework을 제안합니다.
- 영상을 두가지 도메인으로 분리하기 위한 orthogonality and simiilarity losses를 제안합니다.
- Oxford RobotCar 데이터셋에서 SOTA를 보여줍니다.
Method
- Architecture
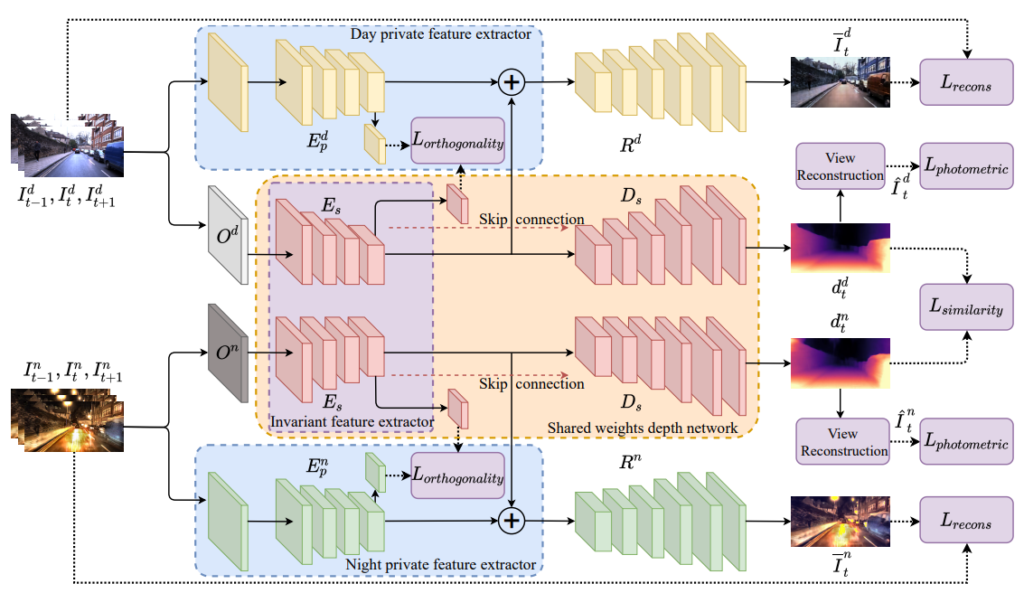
전체 아키택쳐는 다음과 같습니다. 영상을 recontruction 하는 private domain 과 영상의 texture 정보를통해서 깊이를 추정하는 invariant domain으로 나눠집니다. private 도메인은 영상의 illumination을 추출하기 위해서 존재하며 invariant feature와 합쳐서 recontruction하게 되며 이때 invariant feature 는 낮과 밤이 공유됩니다.
식으로 보면 아래와 같으며 recontruction image는 invariant feature와 private feature가 합쳐져서 만들어집니다.
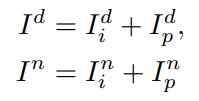
낮과 밤의 private 를 추출하는 네트워크는 독립적으로 각 시간대의 illumination 정보를 추출하며, invariant extractor는 두 시간대가 동일한 네트워크를 하용하며, 두 시간대의 texture 정보를 담습니다. 이러한 설계를 통해서 낮과 밤 동일한 texture feature를 생성해 동일한 depth를 추정할 수 있도록 합니다.
2. Loss
2.1 recontruction loss
단순히 아키택쳐만 위와 같이 설계할 경우 설계된 의도대로 동작하지 않습니다. 각각의 모듈에 설계한 목적을 넣기 위해서 Loss를 설계했습니다. 먼저 private 와 invariant feature가 합쳐진 feature를 이용해 각각의 feature에 의미를 부여해주기 위해서 recontruction loss를 설계해줍니다. 동일한 모델을 통해서 예측된 invariant feature는 텍스쳐를 담고 있고 독립적인 네트워크에서 추정된 feature인 private에 illumination 정보를 담도록 합니다. 그렇게 합쳐진 영상과 실제 영상을 비교하는 loss를 다음과 같이 구성합니다.
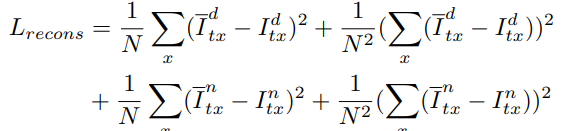
2.2 Similarity Loss
또한 invariant feature가 낮과 밤 동일한 feature를 담을 수 있는 loss를 설계했습니다. 두 feature로 부터 추정된 inverse depth 가 같아지도록 하는 loss 이며 식은 다음과 같습니다.
2.3 Orthogonality Loss
invariant feature와 private feature는 다른 정보를 담고 있어야되기 때문에 두 feature가 다르도록 하는 loss를 두가지 방식으로 추가합니다. 첫번쨰 방식은 각 feature를 1×1 conv를 태운후 1 -D vector로 만든 후 orthogonal loss를 계산합니다. 다음 방식은 style transfer 에서 사용되는 gram matrix를 사용합니다. 각 feature를 gram matrix로 만든 후 1-D vector로 만든 후 orthogonal loss를 계산하고 두 loss를 더하면 됩니다.
Experiments
밤 영상과 낮 영상의 pair를 맞추기 위해서 CycleGAN을 이용해서 밤영상을 생성한 후 학습을 합니다. 데이터셋은 KITTI는 밤데이터가 없기 때문에 Oxford RobotCar를 사용했다고 합니다.
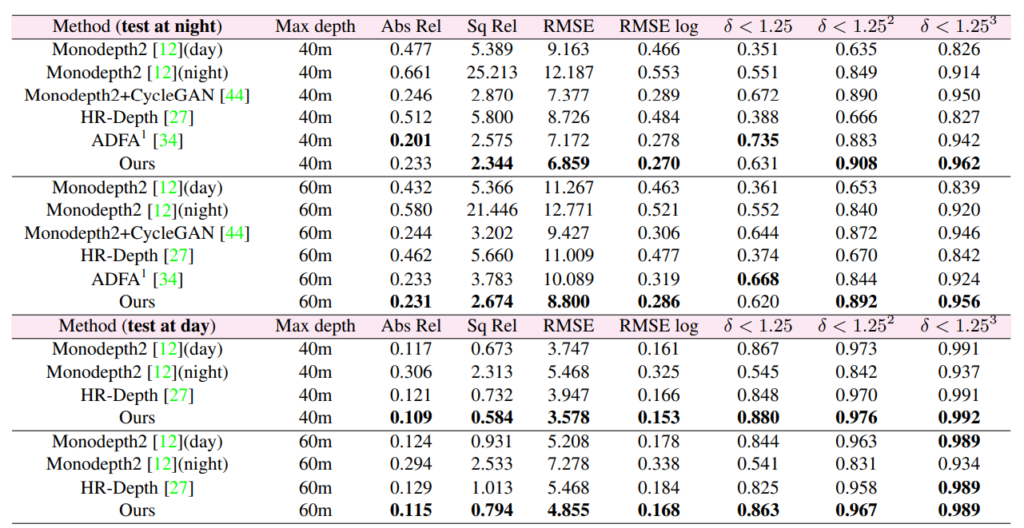
그랬을때 밤에서 성능을 보면 확실히 밤에서 평가를 했을때 monodepth 보다 성능이 높은 것을 볼 수 있으며 다른 Domain shift 방법론을 사용한 것보다 성능이 높은 것을 볼 수 있다. 또한 낮에서 평가했을 때도 다른 방법론 보다 좋은 성능을 보인다. 사실 요기가 의아한데 왜 낮에서는 성능이 더 좋은 것일까가 의문이다. 낮에서 성능을 높이기 위한 무엇을 한게 아닌데…. 흠…

정성적으로 봐도 정확한 결과를 확인할 수 있다.
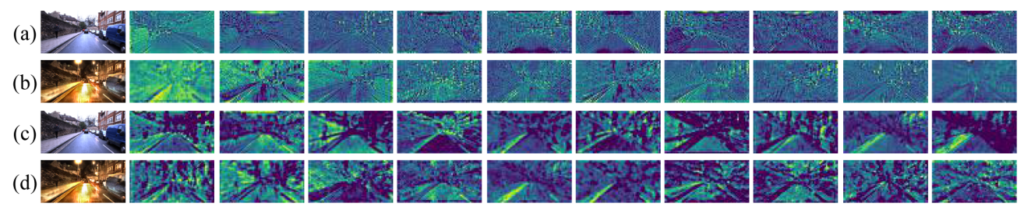
invarinat feature가 얼마나 유사한 가를 보여주어 similarity loss의 효능을 보여주는 figure인데 음… 내눈에는 비슷한지 모르겠다.
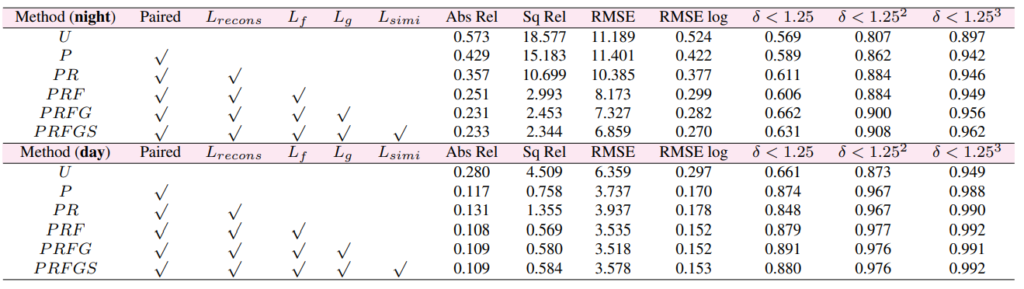
마지막으로 ablation study 인데 recontruction loss와 Lf,Lg가 꽤 좋은 성능 향상을 보임을 알 수있다.
말씀해주신 내용에서 ‘CycleGAN을 이용해서 밤영상을 생성한 후 학습’라고 이야기하셨고, 결국 CycleGAN을 통해 만들어낸 pair의 영향을 많이 받을 것 같습니다. GAN의 문제 중 하나가 모델이 실제는 없는 texture를 만들어내는 경우인데 이러한 경우 depth estimation에 큰 영향을 미칠 것 같습니다. 이러한 부분에 설명은 없는지 궁금합니다.
또 지금 설명에서 밤영상을 만든다고 하셨는데, 중간에 정성적 결과를 실제 논문에서 확인해보니 ‘Fake Day Images’라고 설명하고 있습니다. 그러면 ‘밤->낮’, ‘낮->밤’에 대해서 실험을 모두 진행한걸까요?
Fake day를 만든건 Fake Day를 Monodepth2의 인풋으로 넣었을때 성능을 측정하기 위해서 한 것 이고, 이방법론에서는 따로 사용하진 않습니다. 첫번째 질문같은 경우는 따로 다루지는 않았던것 같습니다
실험 결과에서 사용한 데이터셋을 잘 몰라서 질문드립니다. 학습을 할 때, 동일한 장소의 낮과 밤의 데이터를 모두 확보해서 이를 통해 동일한 texture feature를 생성해 동일한 depth를 뽑아낸다는 것 같은데요. 그럼 실제로 낮 데이터가 없이, 학습하지 않은 장소에서 밤 데이터만을 가지고 depth를 찍어도 성능이 더 좋게 나온다는 뜻으로 해석할 수 있는것인가요?
넵