논문 소개
○ 한줄 소개
해당 논문은 robust learning과 learning sufficiency 라는 두가지 요건을 잡기위한 방법이다. 기존의 논문들은 이러한 trade off 관계의 두 문제를 해결하기 위해 loss를 개선하곤 했다. 그러나 loss를 변형시키는 이러한 접근 방식은 overfitting을 해결하기 위해서는 underfitting을 야기하곤 했다. 해당 논문은 loss의 수정 없이 hypothesis class를 제한하므로써 두 대응되는 문제(robust learning과 learning sufficiency)를 한번에 해결했다.
○ 해당 Task에 대한 기존 연구 방향
Task: Noisy Labels(outliers)가 있는 데이터로 학습 시 충분한 학습으로 overfitting이 되거나, 과한 일반화를 통한 불충분한 학습이라는 두 상태를 주의해야 한다. 해당 논문은 Noisy Labels을 이용한 학습이 잘 되도록하는것을 과제로 한다.
- 이론적으로 Noisy에 강인한 loss를 설계하기 (MAE, RCE) → 학습에 어려움을 겪게 하여 underfitting 문제 발생.
- ambiguous sample에 충분한 학습을 하도록 loss 설계하기 (CE, focal loss) → noisy labels에 overfitting 문제 발생.
- noisy label에 robust하면서 clear one에는 충분히 fit 하도록 (GCE, SCE)→ symetric loss와 CE간의 trade-off를 갖음.
기존의 방법들은 symmetric condition(robust, learning sufficiency)을 만족시키기 위해 새로운 loss를 설계하는 방식이였다. 해당 논문은 loss를 새로 설계하지 않고 network의 output을 제한함으로써 symmetric condition을 만족시키는 학습 방법을 제안한다.
배경 지식
아래 method를 이해하기 위한 배경지식이다. 이는 robust learning에서 사용되는 용어라고 한다.
Risk Minimization.
모델 학습 시 cost를 최소화하는 것처럼 risk를 최소화 하는 방향으로 학습한다. 두 개념의 유사성을 인지하면 더 빠르게 이해할 수 있다.
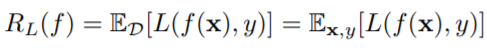
Noise Tolerance.
기존 Risk Minimization 식을 기반으로 아래와 같이 변형하면 일반적으로 Noise Tolerance(noise에 과적합 하지 않고 용인하며 학습하는 것)를 갖을 수 있다.
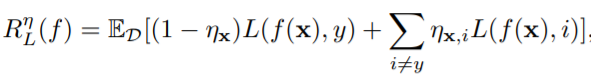
Symmetric Loss Function.
다음의 loss function을 risk minimization 하므로써 일반적으로 Noise Tolerance를 보장할 수 있다.
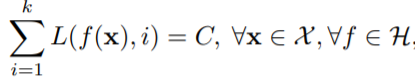
Method
- Noise Tolerance via Output Permutation
논문에서는 모델의 output vector 형식에 제한을 두어 Noise Tolerance를 가졌다. 제한하는 방법은 다음과 같다.
· · · 고정된 output V에 대해 순열 메트릭스 P를 곱하여 v에 대한 순열조합 Pv를 만든다 Pv=[V_pi1, V_pi2 …] (수식1)
· · · 각 순열의 요소와 gt간의 loss를 계산한다. (수식2)
· · · 이를 통해 (수식3)의 효과를 얻을 수 있다. network의 output인 u가 Pv의 형태로 제한되고, symmetric loss function의 형태와 같아지면서 risk miimization을 통한 noise tolerance를 보장할 수 있다.
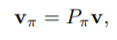
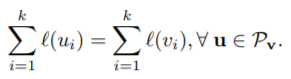
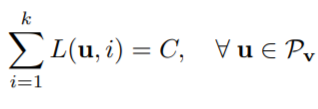
- Robust Learning via Sparse Regularization
논문에서는 모델의 output v를 0과1로 이루어진 one-hot vector로 제한하였다.학습을 위해 one-hot vector 형식을 그냥 적용하지 않고, one-hot vector로 묘사하기 위해 sparse regularization 방식(network output sharpening+ l(n) norm regularization)을 제안하였다고 한다.
· · · Network output Sharpening
모델의 output을 더욱 one-hot vector 형식과 유사하게 만드는 과정이다. 이를 위해 softmax function 수식을 이용하였다고 한다. output sharpening이전 l2 정규화로 [-1, 1] scale을 갖는 z값을, [0, 1] scale의 σ로 변환한다.
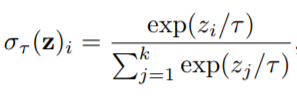
· · · l-p norm Regularization (p >=1)
이는 risk minimization에 적용되었으며 모델의 sparsity output을 촉진시키기 위해 적용되었다.
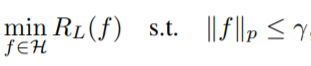
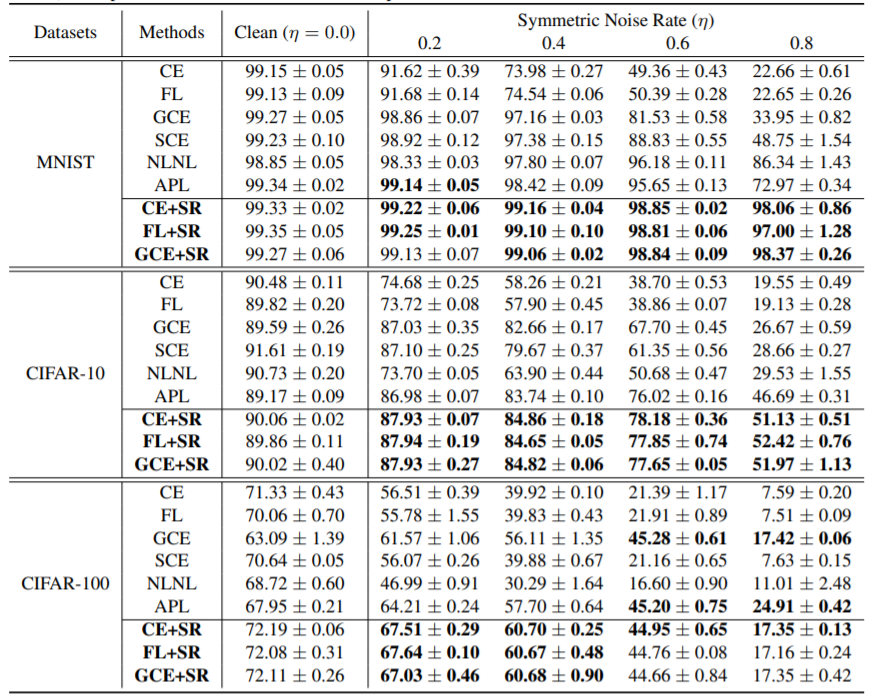
결과
실험은 MNIST와 CIFAR-10, CIFAR-100에서 진행되었다.
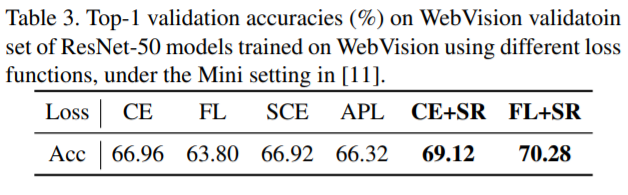
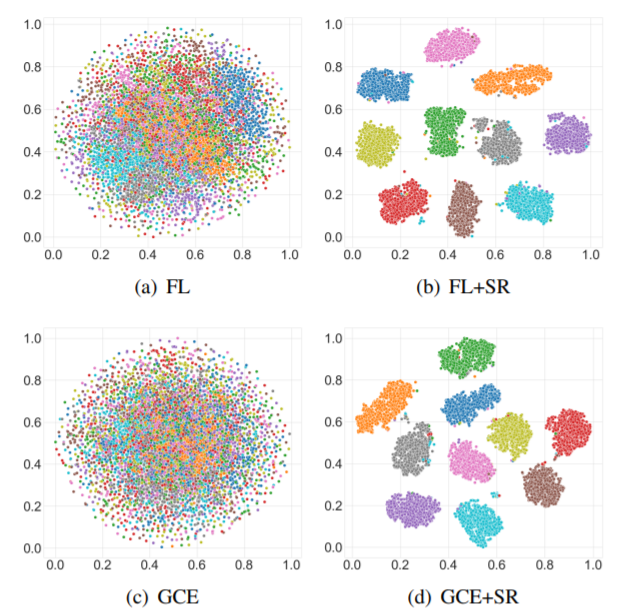
real-world noisy dataset인 WebVision에서도 성능 향상을 보였다.