제가 기존에 리뷰하던 face 랜드마크 탐지 방법과는 약간 다른 방법론입니다. 기존에는 68개의 얼굴의 랜드마크 위치를 예측했다면, 이 방법론은 단일 얼굴 이미지로 3D shape 을 예측하는 방법론입니다.
들어가기 전에…
Face Alignment 는 제가 계속 리뷰하고 있는 Face Landmark Detection/Localization 과 같이 사용되는 용어입니다. 얼굴 인식, 3D Reconstruction, Face animation 등 여러 얼굴 관련 Task에 있어 필수적으로 선행되어야 하기 때문에 정확한 Face Landmark 의 위치를 찾아 정렬하는 것이 중요합니다. 이 주제가 아직도 친숙하지 않은 분들이 있을 것 같아 해당 연구의 중요성을 적었보았습니다…
Dense Face Alignment

Introduction
먼저 본 논문에서는 기존에 연구되고 있던 68개의 랜드마크는 너무 sparse 하다고 문제점을 제기하며, Dense 한 3D face shape 으로의 랜드마크를 추정해야 한다고 주장합니다. 따라서 Dense 한 3D Shape을 구하기 위해 표준 3D 얼굴 모델을 사용하며, 2D 얼굴 이미지와 모델 간 대응관계를 구해 3D face shape을 추정하는 것이 본 논문의 목표입니다. 다시 말해, 본 논문에서는 고밀도의 3D face model을 2D image에 fit 하는 3d-model-fitting-based dense face alignment 방법에 대해 설명합니다.
그러나 3d-model-fitting-based dense face alignment를 사용하기 위해선 두 가지 challenge가 존재합니다. 1) 3D model 로 맞추는데 사용할 GT가 없다라는 것과 2) 동시에 여러 데이터셋으로 학습하는 것이 어렵다는 것입니다. 먼저, 기존 데이터셋은 대개 68개의 랜드마크로 레이블링 되어 있으며, 3D 모델링에 대한 GT를 제공하고 있는 데이터셋은 없습니다. 두번째로 데이터셋마다 서로 다른 개수의 랜드마크를 가지는 등 서로 다른 레이블링으로 인해 학습 시 여러 데이터셋을 동시에 학습하는 것이 어렵습니다.
따라서 이 challenge를 해결하기 위해 CNN을 사용하여 얼굴 이미지를 3D 얼굴 모델로 fitting 되도록 학습시키는 방법을 사용합니다.
DeFA (Dense Face Alignment)
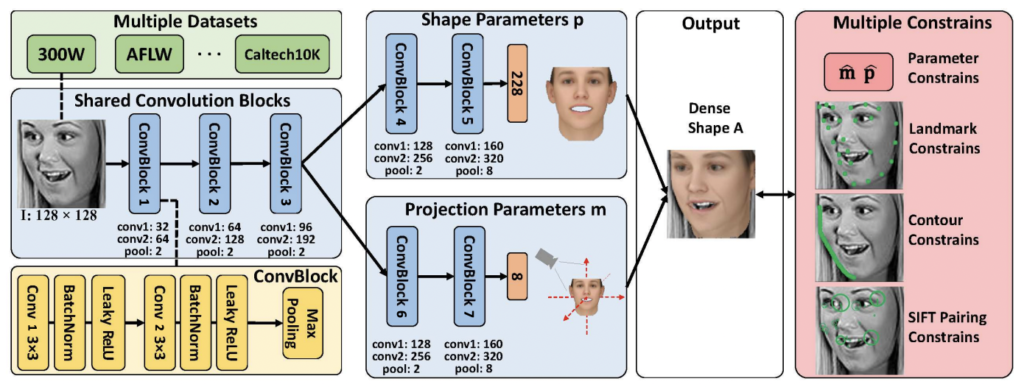
해당 논문에서 주장하는 방법론인 Dense Face Alignment (이하 DeFA)의 아키텍처는 상단 그림과 같습니다. CNN 단일 얼굴 이미지를 입력으로 Dense한 3D shape을 fitting 시키기 위해 CNN을 사용합니다. 이 때, CNN을 학습시키기 위해 여러 제약조건(Landmark fitting constraint, Contour fitting constraint, SIFT pairing constraint)을 설정하여 3D shape을 표현합니다. 아래 그림은 세 가지의 제약 조건을 모두 표현하여 나타낸 것입니다. 지금부터 각 제약 조건에 맞춰 3D 얼굴 표현을 어떻게 하였는지 리뷰해보도록 하겠습니다.

1) 3D Face Representation
이번 장에서는 3D Face 표현을 위한 수식에 대해 나타냅니다.
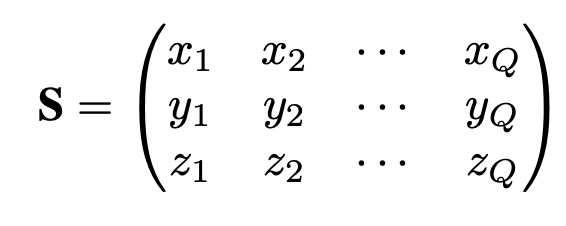
- S : Q개 vertices 의 3D 위치를 포함하는 3D Face representation.
- Q : 해당 논문에서 53,215개의 vertex를 가지는 3D face representation으로 표현
얼굴을 3D로 나타내기 위해, 3D Face Shape인 S를 3DMM(A morphable model for the synthesis of 3D faces)을 따라 3D shape bases의 집합으로 표현합니다. 이는 아래 수식을 사용하여 3D 얼굴 표현S를 계산할 수 있습니다.
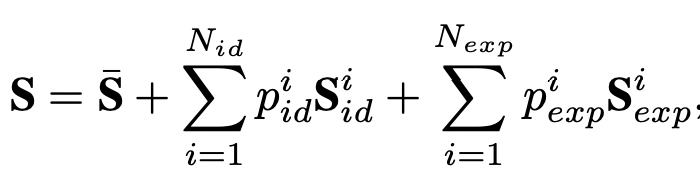
- \bar{S} : the mean shape
- S_{id} : 식별할 수 있는 shape base. 199개로 구성되며 다음과 같은 정보를 표현 (ex) tall/short, light/heavy, and male/female
- S_{id} : 여러 표현을 담당하는 shape base. 22개로 구성되며 mouth-opening, smile, kiss 등과 같은 표정을 표현
- p_{id}, p_{exp} : 대응하는 가중치
또한 N개의 vertices의 하위 집합 U는 이미지 위에서의 2D 랜드마크 위치에 해당합니다.
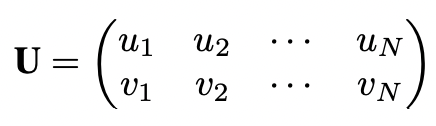
이때, weak perspective projection을 고려하여, 3D face shape을 바탕으로 2D 얼굴의 dense shape을 추정할 수 있습니다. projection matrix는 6개의 자유도를 가지며, scale, rotation, translation의 변화를 모델링 할 수 있습니다. 따라서 변형된 dense face shape A는 다음과 같이 표현할 수 있습니다.
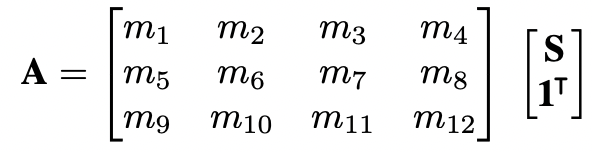
이 때, A는 U를 달성하기 위해 2D 평면에 orthographically하게 투영될 수 있습니다. 따라서 z 좌표 변환(m_{12})은 고려하지 않아도 되고 0으로 할당됩니다. 여기서 orthographic projection 은 행렬 Pr 로 표기됩니다.
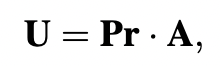
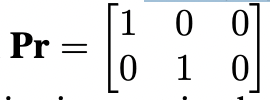
투영 행렬의 특성이 주어졌을 때, 투영 행렬의 정규화된 세 번째 행은 정규화된 처음 두 행의 외부 곱으로 표현될 수 있습니다.
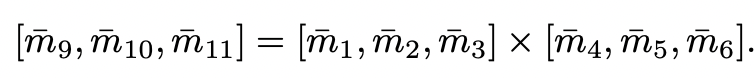
따라서, 임의의 2D 얼굴의 dense shape은 projection parameters m = [m1, ···, m8] \in \R^8의 처음 두 행과 shape basis coefficient p = [p_{id}^1, ..., p_{id}^{199}, p_{exp}^1, ..., p_{exp}^{29}] \in \R^{288}에 의해 결정됩니다. dense 3D shape에 대한 학습은 m과 p의 학습으로 바뀌는데, 이로 인해 차원 측면에서 훨씬 더 쉽게 다루는 것이 가능합니다.
2) CNN Architecture
1)장을 통해 2D 얼굴 이미지를 dense 3D shape으로 표현하기 위해 projection parameter $m$과 shape parameter $p$를 구해야한다는 것을 증명하였습니다. 따라서 입력 이미지 $I$로부터 $m$과 $p$ 로 매핑되는 $f(\theta)$를 학습하는데 CNN을 사용합니다.
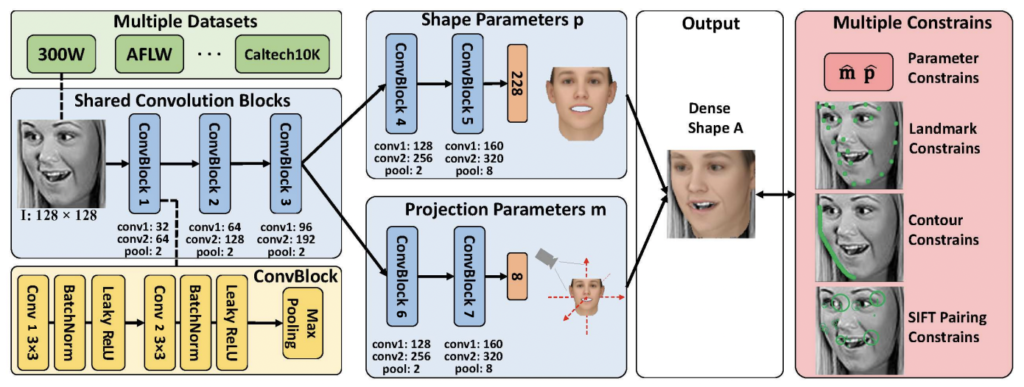
그림을 통해 CNN의 구조를 확인할 수 있습니다. CNN 모델은 m과 p를 각각 구하는 서로 다른 두 개의 branch를 가집니다. 두 branch는 처음 세 개의 convolution block을 공유하는데, 이를 Shared Convolution Block이라합니다. 이 세번째 블록 이후에는 두 개의 개별 conv. block을 사용하여 각각 특징을 추출하고, 두 개의 fully connected layer를 사용하여 최종 shape을 출력합니다.
이 때, 상단 그림 노란색 부분을 보면 각각의 ConvBlock은 두 개의 conv layer와 하나의 max-pooling 레이어를 가지며, 각 conv/FC 하나의 BatchNorm/Leaky ReLU 레이어가 따라오는 구조입니다.
3) Loss Function
Loss 함수는 앞서 언급한 여러 가지 제약조건이 포함되어 설계됩니다.
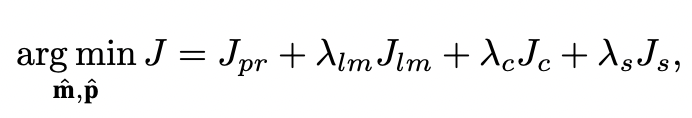
- J_{pr}: Parameter Constraint (PC)
- 예측 parameter와 GT parameter 간 오차를 줄이도록
- J_{lm}: Landmark Fitting Constraint (LFC)
- 추정된 2D 랜드마크와 U_{lm} 라벨링 2D 랜드마크(GT) 간의 차이를 최소화
- J_{c}: Contour Fitting Constraint (CFC)
- 추정된 3D shape의 윤곽선(contour)과 입력 이미지의 윤곽 픽셀 사이의 간격을 줄이도록
- J_{s}: SIFT Pairing Constraint (SPC)
- 두 얼굴 이미지의 SIFT feature point pair가 동일한 3D 점에 대응되도록
3)-(1) J_{pr}: Parameter Constraint (PC)
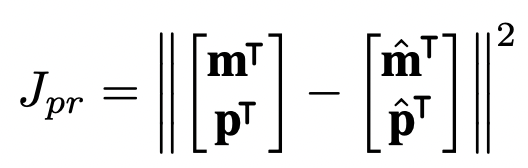
예측 parameter \hat{m}, \hat{p}와 GT parameter m, q 간 오차를 줄이도록
3)-(2) J_{lm}: Landmark Fitting Constraint (LFC)
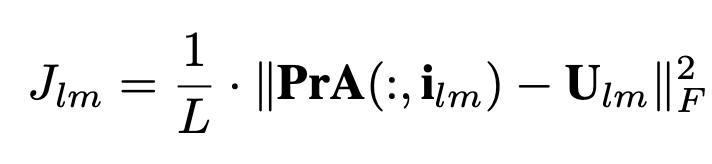
- 추정된 2D 랜드마크와 U_{lm} 라벨링 2D 랜드마크(GT) 간의 차이를 최소화하도록
- F : Frobenius Norm, L : 사전 정의된 랜드마크의 수
- 앞서 예측한 \hat{m}, \hat{p}를 이용하여 shape A를 계산하고, Projection matrix Pr을 이용하여 A(:, ilm)로 3D 랜드마크를 추출이 가능하며, A(:, ilm)를 2D 평면으로 projection을 할 때 LFC loss를 상단 수식처럼 정의가 가능합니다.
3)-(3) J_{c}: Contour Fitting Constraint (CFC)
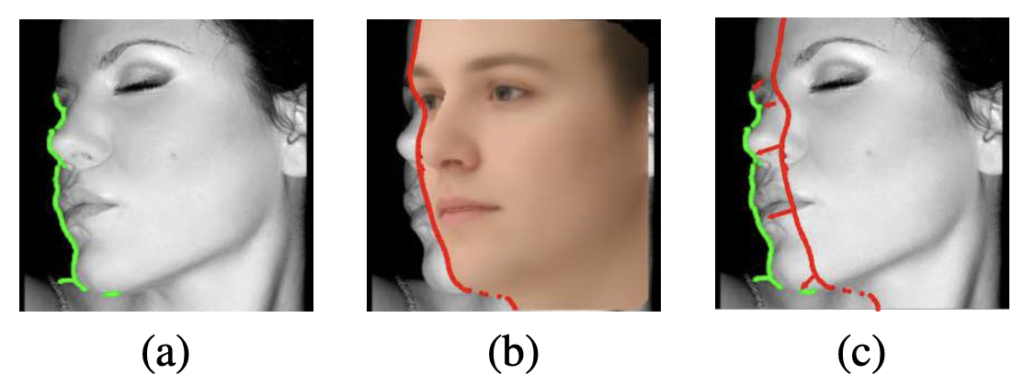
Contour Fitting Constraint는 dense 3d shape의 투영된 외부 윤곽선(실루엣)과 입력 얼굴 이미지에 대응하는 contour pixel 사이 오류를 최소화하는 것을 목표로 합니다. (외부 윤곽선은 배경과 3D 얼굴 사이의 경계라고 이해하면 좋을 것 같네요.) AFLW와 같은 데이터셋에서는 self-occlusion으로 인해 실루엣에 레이블링된 랜드마크가 부족한 경우가 있는데, 이런 경우 해당 조건이 유용하게 적용됩니다.
따라서 이 CFC 조건을 활용하기 위해서는 다음과 같은 세 단계를 거쳐야 합니다.
- 2D 이미지에서 실제 Contour를 detect
- 추정된 3D shape A 에서의 contour vertex를 나타냄
- 실제 contour 와 예측된 contour 사이의 대응 관계를 확인 및 fitting error 역전파
1번째, 2D 얼굴 이미지의 윤곽선 U_c을 검출하기 위해 기존에 존재하던 에지 검출기인 HED를 사용합니다. 상단 그림 (a)가 HED를 통한 윤곽 검출 결과입니다. (해당 단계는 학습을 시작하기 전에 사전에 진행이됩니다.) 300W, AFLW-LPFA와 같은 데이터셋에서는 추정한 contour를 추가 레이블로 사용할 수 있습니다.
2번째, 추정된 3D shape A의 contour는 boundary vertices인 A(:, i_c)로 나타낼 수 있습니다. (LFC와 마찬가지로 A는 예측된 \hat{m}과 \hat{p}로 계산할 수 있습니다) 상단 그림 (b)가 바로 추정된 3D shape에서의 윤곽선입니다.
3번째, 이 조건을 평가하기 위한 GT인 U_c와 A(:,i_c) 사이의 point-to-point 매핑이 필요합니다. 이를 위해 2D 영상의 윤곽 픽셀을 3D shape 윤곽선의 가장 가까운 점과 일치시킨 다음 최소 거리를 계산하는 방법을 사용합니다.
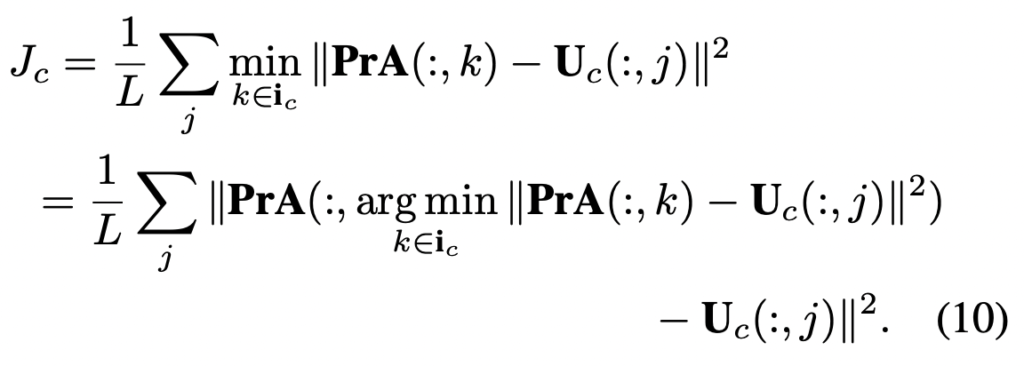
3)-(4) J_{s}: SIFT Pairing Constraint (SPC)
SPC는 가장자리, 주름과 같이 미리 정의된 랜드마크 이외의 중요한 얼굴 point가 동일하도록 dense shape의 예측을 정규화합니다. 본 논문에서는 SIFT desciptor를 사용하여 얼굴 쌍 내의 significant points를 탐지하고 표현합니다. 얼굴의 쌍은 다른 포즈와 표정을 가진 사람일 수도 있고, 아래 그림에 나타난 자르기, 회전, 3D 확대 같은 확대된 이미지가 될 수도 있습니다. 얼굴의 pair가 많을수록 이 조건에 대한 가중치가 커진다고 합니다. i, j의 한쌍이 주어질 때, 먼저 두 개의 얼굴 이미지에서 SIFT 포인트를 감지하여 일치시키고, 일치하는 SIFT 포인트를 U_s^i, U_s^j 이라고 합니다.
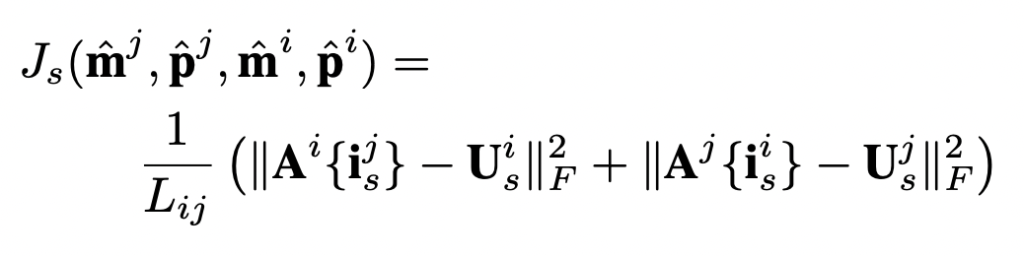
Experimental Result
다음 4개의 데이터셋에 대하여 모델을 평가하였습니다.
- AFLW-LFPA
- AFLW2000-3D
- 300W
- IJBA
Experiments on Large-pose Datasets
Large-pose에 대해 DeFA를 평가한 결과는 아래 테이블과 같습니다. AFLW2000-3D 데이터셋에서 큰 향상을 보였는데, 그 중 특히 yaw [60\degree, 90\degree]에서의 성능이 28% 향상되었다고 합니다.

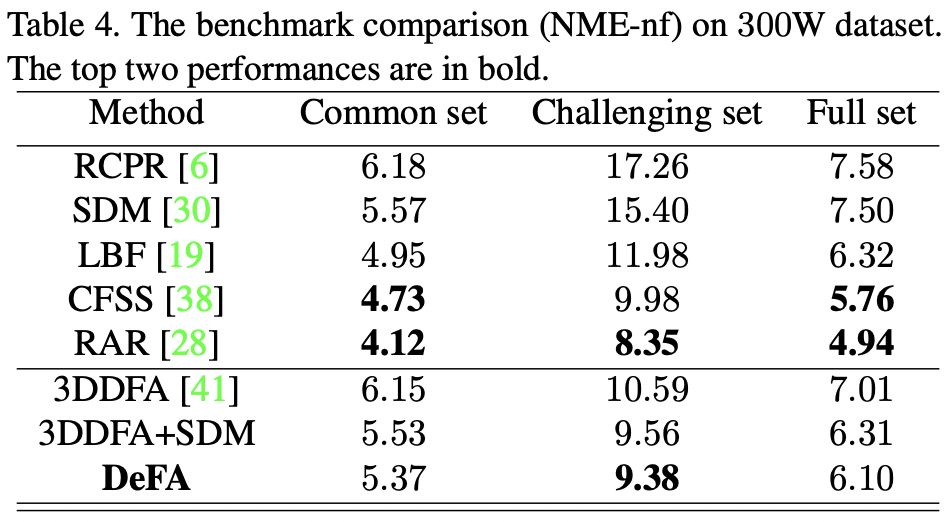
Experiments on Near-frontal Datasets
Large-pose 에 대한 실험 말고, 가장 높은 성능을 기록하고 있는 정면 얼굴에 대한 성능 역시 리포팅하였습니다. 이를 위해 300W 데이터셋 DeFA를 평가하였고 성능은 아래 테이블과 같습니다. 아래 테이블을 확인해보면 위에 5개의 방법론은 정면 이미지를 위해 설계된 방법으로, 300W-거의 정면 데이터셋에 대해서는 높은 성능을 보이는 방법론입니다. 따라서 정면이 아닌 이미지에는 낮은 성능을 보이며 다양한 pose 에 대하여 General 한 성능을 낸다고 하긴 어렵습니다. 반면 3DDFA를 포함한 아래 3개의 방법론은 Large-pose 를 고려하여 만든 방법론이기 때문에, DeFA가 전체 성능에서 SOTA를 달성하지는 않았지만, 아래 기록된 성능에서는 Fine Tunning 없이도 3DDFA+SDM으로 fine tunning된 버전을 능가하는 성능이 나왔다고 합니다.