

오늘은 Video Copy Detection 관련 데이터 셋 중 가장 유명한 VCDB 논문에 대해 리뷰하겠습니다. Video Copy Detection 이란 Query 비디오와 시각적으로 유사하여 copy라고 불릴만한 temporal segment를 보유하고 있는 비디오를 DB에서 찾아내고 비디오 내의 temporal segment 위치도 찾아내는 task로 Retrieval + Localization의 성향을 지니고 있습니다. 해당 task를 위한 데이터 셋은 비디오 pair 사이에서 copy된 부분을 annotation하여야 했기에 cost가 매우 높은 편에 속했고, 이러한 이유로 본 논문 이전에는 주로 Query 비디오에 정해진 몇개의 변환을 적용해 데이터 셋을 생성했었습니다. 그러나 이런 방식은 주로 현실에서 발생하는 copy와 간극이 존재했기에, 직접 annotation을 진행한 VCDB 데이터 셋이 제안되었습니다.
1. VCDB
1.1 Database Collection

우선 28개의 Query text를 정하고 이를 video-sharing website인 Youtube와 MetaCafe에 검색하여, 각 Query text 별로 약 20개의 video를 선택하였습니다. Query text는 주로 넓은 영역을 포괄할 수 있는 commercials, movies, music videos, public speeches, sports 분야에서 정해졌습니다. 이렇게 총 528개의 비디오가 선택되어 core dataset으로 명명하였으며, core dataset 내에서 같은 Query text에 해당하는 비디오 pair를 생성하여 annotation을 위한 6000개의 candidate pair로 정하였습니다. ( {20 \choose 2} * 28 ~ 6000 ) 그리고 보다 현실적인 데이터 셋 시나리오를 위해 core dataset과 겹치지 않는 100000개의 비디오를 다운 받아 distraction set으로 선정하였습니다.
1.2 Annotation
앞서 생성한 candidate pair를 기준으로 annotation을 하였으며, copy된 temporal segment를 annotation 하는 일은 해당 task에 대한 이해가 필요했기에 Amazon 같은 곳에 crowdsourcing을 맡기지 않고 해당 task에 숙련된 part-time annotator 7명이 진행하였습니다. 또한 한 Query text 내의 비디오 pair에서 annotation된 temporal segment는 같은 Query text 내의 다른 비디오 pair 에서도 발생될 수 있기에 이를 기반으로 annotation tool에서 추천하여 annotation 시간을 줄일 수 있었다고 합니다.
1.3 Statistics

Annotation을 마친 후, 총 9236 개의 partial copy pair가 생성되었으며 pair내 temporal segment 간의 주된 변환 관계는 36%가 “insertion of patterns”, 18%가 “camcording”, 27%가 scale 변화, 2%가 “picture in picture”가 존재했습니다. VCDB 이전에 정해진 몇개의 변환으로 구성된 simulated 데이터 셋과는 경향성이 달랐으며, 특히 “insertion of patterns” 변환 은 simulated 데이터 셋에서는 거의 볼 수 없으나 현실에서는 TV show의 logo와 같이 많이 볼 수 있는 변환이기에 VCDB 데이터 셋은 보다 현실 상황에 유사한 데이터 셋이라 볼 수 있습니다. 그리고 Fig 3의 (a)에서 볼 수 있듯이, 모든 pair의 약 80퍼센트 정도가 하나의 partial copy를 보유하고 있습니다. 그리고 Fig 3의 (b)에서 볼 수 있듯이, partial copy의 길이는 10초 미만이 약 32퍼, 10초 이상 20초 미만이 약 28퍼, 20초 이상이 40퍼의 비율로 존재합니다. 마지막으로 Fig 3의 (c)에서 볼 수 있듯이, partial copy가 parent video에서 차지하는 비율은 주로 20퍼 미만이 많았으며, 거의 partial copy가 parent video를 나타내는 80퍼 이상 100퍼미만의 비율도 꽤 높은 경향을 나타냈습니다.
1.4 Baseline System
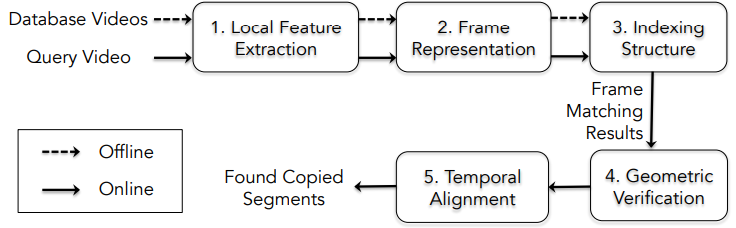
본 논문이 제안한 VCDB의 성능을 측정하기 위해 Baseline system을 Fig 4와 같이 구성하였습니다. 해당 논문이 제안되던 시기는 CNN이 유명해지기 이전의 시기이기 때문에 모두 Handcrafted 방식의 모듈로 구성되어 있습니다. Fig 4의 첫번째와 두번째 모듈을 위해 비디오의 각 프레임 별로 SIFT를 추출하였으며, BoV feature를 생성하였습니다. 생성된 feature를 세번째 모듈에서 “Hamming embedding and weak geometric consistency for large scale image search” 논문의 방식에 따라 Hamming space(0과 1로 구성된 공간)로 embedding하였습니다. 네번째 모듈에서는 SIFT를 기반으로 매칭하여 frame-level의 correctness를 판단하였으며, 다섯번째 모듈에서는 correct라고 판단된 후보들에서 두가지 방식을 활용해 Temporal alignment를 활용하였습니다. 이는 각각 flow optimization 을 해결하기 위해 제안된 “Scalable detection of partial nearduplicate videos by visual-temporal consistency” 논문의 방식과 Temporal Hough Voting이며, 두 가지 방식에 대한 비교 실험을 진행하였습니다.
2. Experiments
실험을 위한 평가 지표로는 segment-level precision (SP) 과 recall (SR)을 활용하였습니다. SP는 |correctly retrieved segments|/|all retrieved segments|, SR은 |correctly retrieved segments|/|groundtruth copy segments| 로 정의되며, temporal segment 내의 한 프레임이라도 GT와 겹친다면 correct한 Positive로 선정하였다고 합니다. Positive 선정 방식에서 tIoU 기반의 thresholding을 하지 않은 이유는 한 프레임이라도 겹치는 조건이 copy detection에 보다 적합하기 때문이라고 합니다.
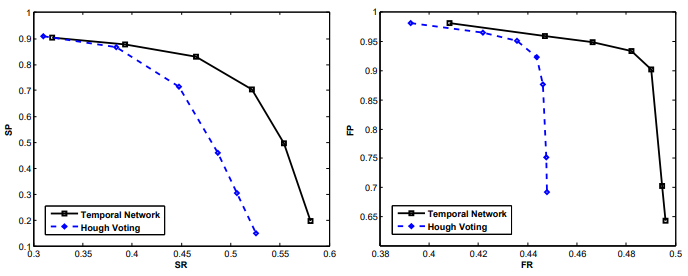
Fig 5의 왼쪽 그래프는 VCDB 데이터 셋(core dataset only)에서 두 가지 Temporal alignment 방식의 성능을 segment-level에서 비교한 결과이며 오른쪽 그래프는 frame-level의 성능을 비교한 결과 입니다. Flow optimization 기반의 temporal alignment 방식이 더 높은 성능을 보였다는 것을 확인할 수 있습니다.
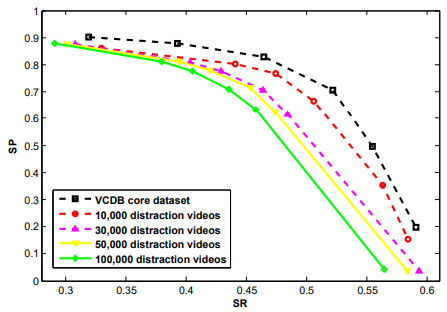
Fig 6은 core dataset에 노이즈에 해당하는 distraction video를 추가하였을 때 SP와 SR에 대한 성능입니다. 노이즈가 추가되었음에도 불구하고 성능이 크게 떨어지지 않은 것으로 제안된 베이스라인의 현실과 유사한 데이터에서 강인성을 보였습니다. 이는 제안된 베이스라인이 frame-level의 시각적 유사도 비교 시스템이고, 거의 시각적으로 동일한 부분을 찾아내어야하는 copy detection이기 때문에 semantic한 정보를 판단할 필요가 없어 보이는 강인성으로 판단되어집니다.
3. References
[1] http://www.yugangjiang.info/publication/eccv14-VCDB.pdf
이미 core dataset이 현실 상황과 유사한 데이터셋이라면 distraction video기 꼭 필요 하지 않아 보이는데, distraction video가 어떤 역할을 하기 위해 있는지, noise를 어떻게 첨가하는지 궁금합니다…!
Database에서 Query와의 유사도로 ranking을 매기는데, Database에 distraction video가 들어가게 되면 ranking을 매길 때 노이즈로 포함되어 Retrieval 자체의 난이도를 높이게 됩니다. 보통 현실에서 사용자가 Query를 던지고 이와 관련이 없는 비디오들도 포함된 Database에서 유사도 ranking을 반환해주기 때문에 distraction video가 있을 때도 현실과 유사한 상황이라고 할 수 있습니다. Core dataset 에서 매겨진 segment-level의 annotation은 annotation-level에서, 그리고 Distraction video가 노이즈로 추가된 것은 Database-level에서 현실 상황과 유사하다고 생각하시면 되겠습니다.