
안녕하세요! 두 번째 리뷰입니다. 이 논문은 ViSiL (Video Similarity Learning architecture) 을 소개하는 논문입니다. 일반적으로 비디오 간의 시공간적 관계 (Spatio-Temporal relations)는 이전의 Video Retrieval 접근 방식에서 손실됐었는데, ViSiL 을 사용하면 정제된 frame-to-frame 매트릭스에서 video-to-video similarity 를 계산할 수 있어 intra-frame / inter-frame relations, 즉 시공간적 관계를 고려할 수 있다고 하네요! 그럼 리뷰 시작하겠습니다!
Introduction
인터넷을 통해 비디오를 공유하는 서비스가 인기가 있어짐에 따라, 웹 상에 있는 비디오 컨텐츠의 양이 전례 없는 규모에 이르렀습니다. 특히 최근 유행하고 있는 Short-form 영상 서비스인 Instagram Reels, Youtube Shorts, TikTok 등만 생각해봐도 하루에 엄청난 양의 비디오 컨텐츠들이 올라오는데, 그 외의 서비스까지 포함한다면 엄청난 컨텐츠가 업로드 되고 있겠죠! 아무래도 데이터가 늘어나다 보니, 컨텐츠를 기반으로 video retrieval 을 하는 것이 점점 더 어려워지고 있습니다. Video retrieval 이 사용되는 분야에는 video filtering, recommendation, copyright protection and verification 등이 있는데, 이는 우리가 사용하는 애플리케이션의 필수적인 요소라 이에 대한 그 중요성 또한 커지고 있죠. 본 논문에서는 Video retrieval system 의 핵심인 ‘비디오 pairs 간의 Similarity estimation (유사성 추정)’ 문제를 다룹니다.
기존에 이 문제에 대한 간단한 접근 방식이 있습니다. 바로 frame-level features 를 aggregate / pool 해서 하나의 video-representation 으로 만든 다음에, 이걸 이용하여 similarity measure 를 계산하는 방식입니다. 대표적인 예로는 global vectors, hash code, Bag-of-Words (Bow) 등이 있습니다. (global vectors, Bow는 ViSiL을 읽기 직전에 공부했던 내용이라 반가웠습니다! 나중에 hash code 도 공부해봐야겠네요.) 그러나, 이러한 representations 는 visual similarity 의 spatial and temporal 구조를 무시한다고 합니다.
그 외에도 다른 접근 방식들이 있었다고 합니다. 이러한 방식들을 살펴 봤을때, 논문 저자는 video retrieval 분야의 유망한 방향이 유사도를 측정할 때 비디오의 spatial and temporal 구조를 더 잘 활용하는 거라는 결론을 내린 것 같습니다.
본 논문에서는 ViSiL (Video Similarity Learning architecture) 을 제안합니다. 이는 visual similarity 의 spatial (intra-frame) 구조와 temporal (inter-frame) 구조를 둘 다 고려하는 Video similarity learning network, 즉 비디오의 유사도를 학습하는 네트워크 입니다.
이 방법을 사용하면, relevant videos 의 frame-level similarity 의 temporal structure 을 학습하고, (Fig1의 빨간 대각선 구조) 발생할 수도 있는 가짜 pairwise frame similarities 도 억제할 수 있다고 합니다. (Fig1 의 아래쪽을 보면, irrelevant videos 가 visil을 통과 했을 때 similarity 가 높은 부분이 나오지 않기 때문에 이런 말을 한 것 같습니다.)
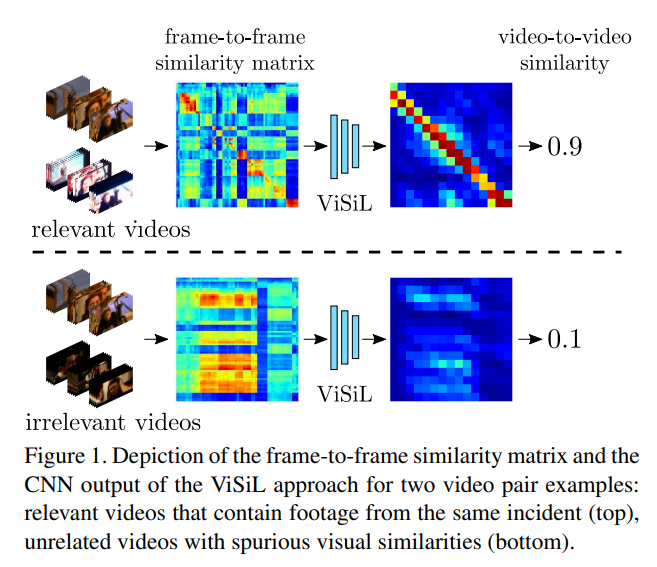
Video Retrieval 문제에는 아래와 같은 것들이 있습니다.
- NDVR (Near-Duplicate Video Retrieval)
- FIVR (Fine-grained Incident) EVR (Event-based Video Retrieval)
- AVR (Action Video Retrieval)
public benchmark datasets 를 사용해서 이러한 video retrieval 문제에 대해 ViSiL을 평가했는데, 모든 경우에서 ViSiL이 최신 방법을 큰 차이로 능가했다고 합니다.
Preliminaries
Tensor Dot (TD)
- \mathcal{A} \in \mathbb{R}^{N_1\times N_2 \times K}
- \mathcal{B} \in \mathbb{R}^{K\times M_1 \times M_2}
- 이 둘의 TD (tensor contraction) 은 특정 축에 대해 두 텐서를 합하는 것이다.
- 즉, 두 텐서의 TD 는 \mathcal{C} = \mathcal{A} \cdot _{(i,j)} \mathcal{B} 이다.
- 이때, \mathcal{C} \in \mathbb{R}^{N_1\times N_2\times M_1 \times M_2} 이 두 텐서의 TD 이다.
- i 와 j 는 텐서들이 합해진 축을 나타낸다. (축 사이즈가 같은 경우가 여러 세트인 경우도 있기 때문에 표현해줘야한다.)
Chamfer Similarity (CS)
CS(x, y) = {1 \over N}\displaystyle\sum_{i=1}^N \underset{j \in [1,M]}{\mathrm{max}} S(i,j)- set x에 원소가 N개가 있고, set y 에 원소가 M개가 있다고 하자.
- 그럼 이들끼리 유사도를 나타내는 매트릭스는 N*M 이다.
- 이때 이 매트릭스에서 각 row 별로 최대 (즉, 유사도가 가장 높은 것)을 뽑아서 row 갯수로 나누어 평균을 낸게 CS 값이다.
- CS 는 symmetric 하지 않다.
- 즉, CS(x,y) \ne CS(y, x) 이다.
- 그러나, symmetric varinat SCS 는 SCS(x,y) = (CS(x,y) + CS(y, x) ) / 2 로 정의될 수 있다.
ViSiL description
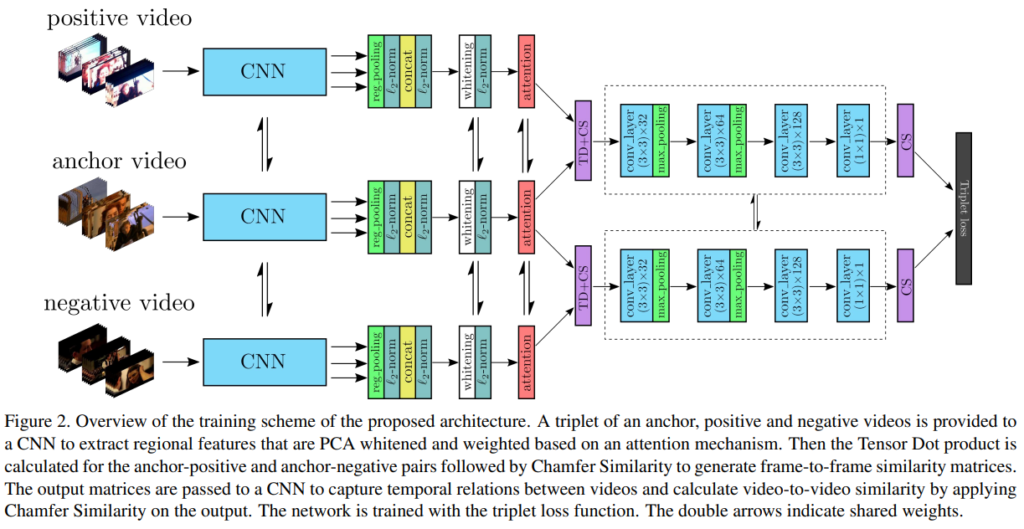
figure 2 가 우리가 제안하는 접근 방식인 ViSiL을 설명하는 그림입니다. 논문에서는 이걸 이후의 섹션에서 아래의 순서대로 설명을 했습니다.
- anchor, positive, negative videos 로 이루어진 triplet 이 input 으로 들어감
- feature maps 에 region pooling 적용시켜서 CNN 에서 region-level frame features 를 뽑아냄
- (2)은 PCA-whitened 되고, attention mechanism 에 의해 weighted 됨 (Section 4.1)
- TD (Tensor Dot) product 와 CS (Chamfer Similarity) 를 사용하여 frame-to-frame similarity matrics 를 생성함 (Section 4.2)
- (4)의 output matrics, 즉 모든 pairwise frame 으로 구성된 similarity matrix 가 video-level similarity model 을 학습시키기 위해 4-layer CNN에 실림. (Section 4.3)
- CNN의 마지막 layer 에서, CS (Chamfer Similarity)를 이용해 video-to-video similarity 를 계산함
이 때 이 과정은, training dataset 으로 부터 선택되거나 자동적으로 생성된 triplets 를 기반으로 하는 triplet loss scheme 를 이용하여 학습되는 것임. (Section 4.4, 4.5)
4.1. Feature extraction
input video frame 이 주어졌을 때, 우리는 특성 granularity level L_N (이때, N \in \{ 1,2,3,...\})인 intermediate convolutional layers 의 activations 에 R-MAC (Regional Maximum Activation of Convolution) 을 적용합니다.
(? 이 때 N이 어떤 의미인지 질문을 했는데, 이건 layer의 갯수라고 합니다. 일단 논문에서 N =3 이고, 코드 보면 N = 4 인데, CNN 의 중간의 layer 3개와 마지막 layer 1개로 총 4개에서 feature map 을 뽑는다고 합니다. 일찍 뽑을 수록 이미지의 edge 같은 특성이 살아있는 low level의 feature map 이 뽑아지고, 늦게 뽑을 수록 이미지의 semantic 한 부분 (육안으로는 구별 x) 이 살아있는 high level 의 feature map 을 뽑기 때문에 이 정도를 granularity level 이라 표현한 것이라고 설명해주셨습니다.)
R-MAC 은 feature map 에서 여러 개의 region 을 만들어서, 여러 개의 image representation 을 만드는 기법이라고 합니다.
주어진 CNN architecture 은 K 개의 convolutional layers 로 구성 되어 있고, 이 layers 들은 K 개의 feature maps 를 생성합니다.
- \mathcal{M}^k = \mathbb{R}^{N \times N \times C_k} (k = 1, ..., K)
이때 C_k 는 k^{th} convolutional layer 의 channel 수 입니다. 뽑힌 feature maps 들은 모두 resolution (N \times N) 을 갖고 있습니다.
이 k 개의 feature maps 들이 concatenated 돼서 \mathcal{M} = \mathbb{R}^{N \times N \times C} 라는 하나의 frame representation 이 만들어지는데, 이때 C = C_1 + ... + C_K 입니다.
(?convolution layer 별로 channel 수를 달라서 이런 식으로 공식을 나타냈나 싶어서 질문 했는데, input 이 3 채널이기 때문에 feature map 의 채널 수도 동일하게 3이라고 합니다. 위에서 만든 feature map 들을 concat 하면 granularity level 이 다른 feature map 들을 concat 한 것이기 때문에, feature representation 을 할 수 있다고 합니다.)
concatenation 전과 후에 feature maps 의 channel axis 에 \mathcal{l}^2-normalization 을 적용해줍니다. 이런 feature extraction process 는 L_N-iMAC 이라고 합니다. 이 과정을 통해 뽑힌 frame features 는 다른 granularities 에 대한, frames 의 spatial information 을 유지합니다.
그 후에, extracted frame descriptors 에 PCA 를 적용 시킵니다. 이건 whitening and/or dimensionalirty reduction 을 수행하기 위함입니다.
모든 region vectors 에서의 extracted frame descriptors result 에 대한 \mathcal{l}^2-normalization 은 similarity calculation 에서 동일하게 고려된다고 합니다. 예를 들면, a completely dark region 과 a region depicting a subject of interest (관심 대상을 묘사하는 지역) 둘 다 similarity 에 동일한 영향을 미친다고 합니다. 이런 이슈를 피하기 위해서 region vectors 에 대한 visual attention mechanism 을 통해 frame regions 의 saliency 를 기반으로 해당 frame regions 에게 weight 를 주는 것입니다. (이건 다른 연구 분야 (i.e., document classification) 에서 가져온 메소드에게 영감을 받았다고 합니다.)
이걸 video retrieval 에 성공적으로 적용시키기 위해서, 만든 것이 attention mechanism 입니다.
- a frame representation \mathcal{M} with region vector r_{ij} : {\mathcal{M}(i,j,\cdot)} \in \mathbb{R}^C
- where i \in [1,N], j \in [1,N]
- a visual context unit vector u : 각 region vector 의 importance 를 측정하기 위해 사용함
이를 위해, (weight 를 주기 위해, 즉 관심대상을 묘사할 수록 큰 영향을 주기 위해) 우리는 weight score a_{ij} 를 도출해내기 위해 internal context vector u 를 사용하여 모든 r_{ij} region vector 간의 dot product 를 계산합니다. 이때 모든 벡터들이 unit norm 이기 때문에, a_{ij} 의 범위는 [-1, 1] 이 됩니다.
region vector 들의 direction 을 보존하고 그들의 norm 을 바꾸기 위해 weight scores a_{ij} 를 2로 나누고 0.5 를 더하는데, 이렇게 하면 범위가 [0,1] 이 됩니다. 공식은 아래와 같습니다.
- a_{ij} = u^T r_{ij}, s.t. ||u|| = 1
- r'_{ij} = (a_{ij}/2 + 0.5)*r_{ij}
Weighting process 의 모든 functions 들은 differentiable 하기에, u 는 training process 를 통해 학습 가능합니다.
일반적으로 볼 수 있는 관행과는 달리, calculated weights 에는 normalization function (e.g. soft-max or division by sum) 을 적용하지 않는다고 합니다. 그 이유는 각 vector 를 독립적으로 weight 하고 싶기 때문이라는데, 이게 이해가 가지 않아 질문을 했습니다. normalization 은 안 하면서, 범위는 바꾸는 이유가 궁금해서 질문했습니다. ?
- 먼저, self-attention weight 를 줬을 때의 장점에 대해 들었습니다. 이건 대략적인 예시를 들어 설명해보겠습니다. [10, 100, 40, 200, 50] 이런 벡터가 있다고 해봅시다. 자신의 벡터를 이용하여 어떤 방식으로 attention weight 를 구했을 때, [0.1, 10, 0.4, 20, 0.5] 라는 weight 를 구했다고 칩시다. 이 weight 를 곱하면, [1, 1000, 16, 4000, 25] 가 됩니다. 큰 값은 더 커지고, 작은 값은 더 작아졌습니다. 이런 식으로 특성을 살려준다는게 self-attention 의 장점입니다.
- 그런데 이런 상태에서, 정규화를 하면, [-201, -181, -198, 598, -196] 대강 이런 식으로 변하는데, 그러면 큰 값은 더 크고 작은 값이 더 작아지게 만들어 줬던게 헛수고가 됩니다. (예시가 적절하지 않을 수도 있는데 아무튼 그렇습니다…)
- 따라서, weight 를 준 다음에 normalization 을 적용하거나, 마찬가지로 normalization 을 한 다음에 weight 를 주면 오히려 안 좋기 때문에, normalization 은 안 하고, self attention 으로 만든 weight 를 벡터에 값마다 각각 independently 하게 주는 것 입니다.
또한, 실험적으로 찾아냈다는데, 다른 works 들과는 다르게, atttention module 에서 hidden layer 를 사용하는 것은 시스템의 성능에 악영향을 미친다고 합니다. (? 이 부분도 궁금해서 질문을 했는데, hidden layer 가 늘어날 수록 parameter 또한 늘어나는데, over parameter 라고, parameter 가 너무 늘어나면 학습할 게 많아져서 오히려 성능이 안 좋아지는 영향이 있다고 합니다.)
4.2. Frame-to-frame similarity
두 개의 video frame d, b 가 주어졌을 때, 우리는 이 둘의 similarity 를 계산하기 위해 그들의 feature maps 에 CS 를 적용합니다.
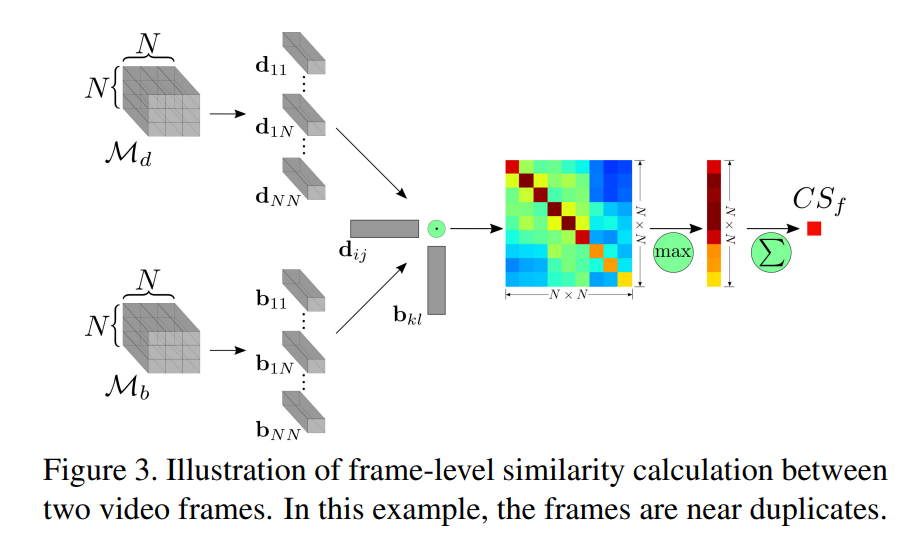
- region feature map 2개 : \mathcal{M_d}, \mathcal{M_b} = \mathbb{R}^{N \times N \times C} 는 region vectors d_{ij}, b_{kl} \in \mathbb{R}^C 으로 decomposed 된다.
- 모든 region vectors의 쌍들 간의 dot product 가 계산되어, 두 video frame d, b 간의 similarity matrix 를 만든다.
- similarity matrix 에 CS 가 적용돼서, frame-to-frame similarity 가 계산된다.
이 과정은 region vectors 로 캡쳐한 geometric 정보를 활용하고, 어느 정도의 spatial invariance 를 제공한다고 합니다.
더 자세하게 말하면, CNN 은 (objet parts 처럼) mid-level visual 구조에 해당하는 features 를 뽑고, CS 와 합쳐집니다. 이건 region-to-region matrix 의 global structure 를 무시하도록 디자인 된 것이고, spatial transformations (e.g. spatial shift) 에 대한 robust 한 similarity calculation proces 를 구성하게 됩니다.
(이렇게 하면 CNN 의 mid- level에서 feature 뽑고 CS로 합쳐지는거라 global structure 무시하는데, 이게 spatial transformation 에 대해 robust 하니까 오히려 좋다는 뜻으로 이해했습니다.)
4.3. Video-to-video similarity
두 개의 비디오 q, p (각각 X frames 와 Y frames 를 가진) 에 대해 frame-to-frame similarity 를 적용하기 위해서, 우리는 TD combined with CS 를 해당 video tensors \mathcal{Q} 와 \mathcal{P} 에 적용하여, frame-to-frame similarity matrix 인 \mathcal{S_f^{qp}} \in \mathbb{R}^{X \times Y} 를 만듭니다.
- S_f^{qp} = {1 \over {N^2} }\displaystyle\sum_{i=1}^{N^2} \underset{j \in [1,N^2]}{\mathrm{max}} \mathcal{Q} \cdot _{(3,1)} \mathcal{P}^T (\cdot, i, j, \cdot)
- TD 축은 해당 video tensors 의 channel dimension 을 나타냄
이렇게 하면, CS_f(d,b) = {1 \over {N^2} }\displaystyle\sum_{i,j=1}^N \underset{k,l \in [1,N]}{\mathrm{max}} d_{ij}^T b_{kl} 이거, 즉 frame-to-frame similarity 를 모든 frame pair 에 적용하는 것입니다.
두 비디오 간의 similarity 를 계산하기 위해서, 이전의 process 에서 만들어진 similarity matrix \mathcal{S}_f^{qp} 가 CNN network 로 공급됩니다.
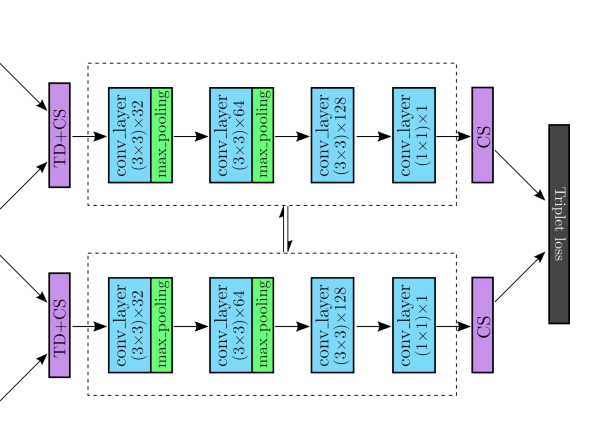
이 network 는 segment level 에서의 video 간의 similarities 의 robust 패턴을 학습할 수 있습니다.
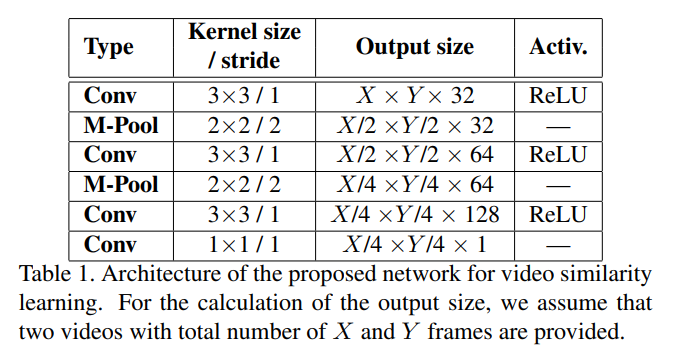
Table 1 은 제안된 ViSiL framework 의 CNN 구조를 보여줍니다.
final video similarity 를 구하기 위해서, 우리는 hard tanh activation function 을 netowrk ouput 인 values 에다가 적용시켰습니다.
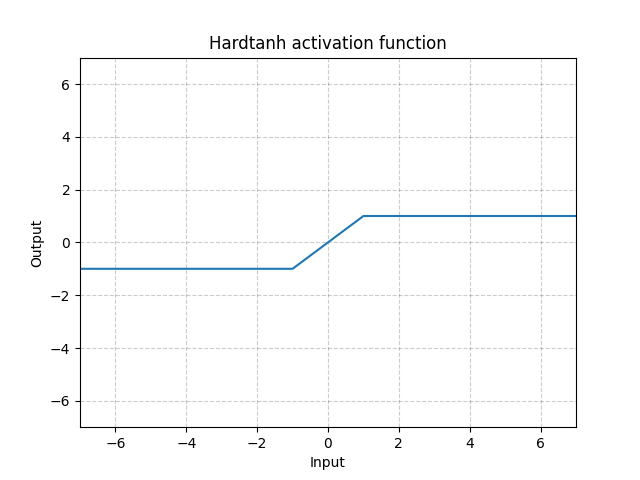
이미지를 보면 알 수 있듯이, values 를 [-1,1] 의 범위로 clip 해주는 함수입니다.
그리고 나서, a single value 를 얻기 위해 CS 를 적용해줍니다.
- CS_v(q,p) = {1 \over {X'} }\displaystyle\sum_{i=1}^{X'} \underset{j \in [1,Y']}{\mathrm{max}} Htanh(S_{v}^{qp}(i,j))
이때, \mathcal{S}_v^{qp} \in \mathbb{R}^{X' \times Y'} 은 CNN network 의 output 입니다.
결과적으로, frame-to-frame similarity matrix 에서 strong diagnosals or diagonal parts 같은 (i.e. contained sequences) 다른 temporal similarity 구조들이 포착될 수 있다고 합니다.
잠깐 짚고 넘어가자면, CS_f 는 frame-to-frame Chamfer Similarity 이고 CS_v 는 video-to-video Chamfer Similarity 입니다!
4.4 Loss function
target video similarity score CS_v(q,p) 는 서로 연관이 있는 videos 에 대해서는 높고, 연관이 없는 videos 에 대해서는 낮아야 합니다. 우리의 network 를 학습시키기 위해서, video collection 을 video triplets 으로 준비했습니다. (이 때 tirplet 은 vcdm 에 의해 만들어집니다.)
이때 v, v^+, v^- 는 각각 an anchor, a positive (i.e. relevant), a negative (i.e. irrelevant) video 입니다.
positive video pairs 에 높은 similarity scores 를 주고, negative video pairs 에 낮은 similarity scores 를 주기 위해, 우리는 ‘triplet loss‘를 사용합니다.
- \mathcal{L_{tr}} = max\{0, CS_v(v, v^-) - CS_v(v, v^+) + \gamma\}
이때, \gamma 는 margin parameter
또한, saturated outputs (포화 출력) 을 초래할 수 있는, hard tanh 의 input 의 높은 값에 불이익을 주는 similarity regularization function 을 정의합니다.
이건 hard tanh 의 clipping range 인, [-1, 1] 범위의 output matrics \mathcal{S}_v 를 생성하도록 network 를 이끌어주는 효과적인 mechanism 이라고 합니다.
regularization loss 를 계산하기 위해서, 우리는 단순하게 clipping range 를 벗어나는 ouput similarity matrices 에 있는 모든 값들을 더해주면 됩니다.
(그니까, [-1, 1] 범위의 \mathcal{S_v} 만들었는데, 그럼에도 불구하고 그 범위 바깥의 값이 매트릭스 안에 있을 수도 있다는 거. 그래서 그거 다 더한 값으로 loss 만드는 것입니다. 높을 수록 안 좋습니다.)
\mathcal{L_{reg}} = \displaystyle\sum_{i=1}^{X'} \displaystyle\sum_{j=1}^{Y'}|max \{0, \mathcal(S_v^{qp}(i,j) - 1 \}| + |min \{0, \mathcal(S_v^{qp}(i,j) + 1\}|total loss function 은 아래와 같습니다. (triplet loss + regularization loss)
\mathcal{L} = \mathcal{L_{tr}} + \mathcal{r}* \mathcal{L_{reg}}\mathcal{r} 은 regularization hyperparameter 인데, 이는 total loss 에 대한 similarity regularization 의 contribution 을 조정하는 값입니다.
4.5 Training ViSiL
ViSiL architecture 를 학습시키는 것은, segment level 의 ground truth annotations 이 있는 training dataset 이 필요합니다. 이러한 annotations 를 사용해서, 우리는 학습 중에 anchor-positive pairs 역할을 하기 위해, 관련 visual content 가 있는 video pairs 를 추출해야합니다.
추가로, 우리는 임의의 videos 에 여러가지 transformations 를 적용시킴으로써 인공적으로 positive videos 를 만들어냈다.
우리가 고려한 3가지 transformations 카테고리
- color
- conversion to grayscale
- brightness
- contrast
- hue
- saturation adjustment
- geometric
- horizontal / vertical flip
- crop
- rotation
- resize
- rescale
- temporal
- slow motion
- fast forward
- frame insertion
- video pause or reversion
학습하는 동안, 각 카테고리에서 하나의 transformation 이 랜덤하게 골라져서 선택된 비디오에 적용됩니다. positive pairs 로 구성된 2개의 video pools 를 construct 한 후, 각 positive pair 에 대해 hard triplets 를 생성합니다.
즉, anchor video 와 positive video 사이의 similarity 보다 큰, anchor 보다 큰 anchor 와 유사한 negative videos (hard negative) 를 construct 한다는 뜻입니다.
- Triplet loss 일종의 loss function \mathcal{L}(A,P,N) = max(||f(A) - f(P)||^2 - ||f(A) - f(N)||^2 + \alpha, 0)
그 다음은, BoW 접근 방식을 사용해서 videos 사이의 similarity 를 계산하면 되는 것입니다.
pool 은 총 2개로 만들었습니다.
첫 번째 pool 은 training dataset 의 annotated videos 에서 파생된 것입니다. 최소 5초 이상의 overlap 이 있는 2개의 videos 가 하나의 positive pair 를 이루게 됩니다. s 를 해당 video segments 의 similarity 라고 해봅시다. positive pair 에 있는 두 segment 와, s 보다 similarity (BoW-based [20])가 큰 videos 는 hard negatives 를 구성하게 됩니다.
두 번째 pool 은 인공적으로 positive pairs 를 만드는데 쓰였던 training dataset 의 임의의 videos 로부터 파생되었습니다. initial videos 와 비슷한 (similarity > 0.1) videos 는 hard negatives 로 고려됩니다. 잠재적인 near-duplicates 를 피하기 위해, 우리는 hard negative sets 로부터 similarity > 0.5 인 videos 를 제거합니다. 각 training epoch 에서, 우리는 각 video pool 에서 T triplets 를 sample 한다. GPU memory limitations 때문에, network 에게 전체 videos 를 주지는 않는다고 합니다. 대신에, triplet 에 있는 each video 로부터 total size of W frames 의 랜덤한 video snippet 를 선택합니다. 이때, anchor videos 와 positives videos 사이에는 최소 5초의 overlap 이 있다는 것이 보장된다고 합니다.
Evaluation setup
제안된 approach 는 4가지 retrieval tasks 에 의해 평가됩니다.
- NDVR (Near-Duplicate Video Retrieval)
- FIVR (Fine-grained Incident Video Retrieval)
- EVR (Event Video Retrieval)
- AVR (Action Video Retrieval)
모든 tasks 에서 mAP (mean Average Precision) 을 report 하는 것이고, 이 tasks 들을 위한 데이터셋은 따로 있습니다.
Datasets
ViSiL 을 원복하려는데 FIVR 와 VCDB 가 언제 쓰이는지 많이 헷갈렸기에… dataset 도 살짝 정리해보겠습니다.
VCDB [16]
- triplets 을 만드는 training dataset 으로 쓰였다.

- It consists of 528 videos with 9,000 pairs of copied segments in the core dataset, and also a subset of 100,000 distractor videos.
CC_WEB_VIDEO [35]
- NDVR (Near-Duplicate Video Retrieval) 에 사용되는 데이터셋
- It consists of 24 query sets and 13,129 videos.
- 우리는 이 annotations 에 대해 여러가지 quality issues 를 찾았기 때문에, ( e.g. numerous positives mislabeled as negatives)이 annotations 에 대한 ‘cleaned’ version 에 대한 결과를 제공한다.
- 또한, 2 가지 evaluation settings 를 사용헀다.
- query sets 에 대한 performance 만 측정하는 것
- entire dataset 에 대한 performance 를 측정하는 것
FIVR-200K
- FIVR (Fine-grained Incident Video Retrieval) 문제를 위한 데이터셋

- It consists of 225,960 videos and 100 queries. It includes three different retrieval tasks:
- a) the Duplicate Scene Video Retrieval (DSVR)
- b) the Complementary Scene Video Retrieval (CSVR)
- c) the Incident Scene Video Retrieval (ISVR)
- 빠른 비교를 위해, 우리는 FIVR-200K 대신, 이의 일부인 FIVR-5K를 사용했다.
FIVR-5K인 경우
DSVR task 에서 50개의 가장 어려운 query 들을 선택한 것
- Query : 50 videos
- Dabtabase
- DSVR : 1074 videos, index
EVVE
- EVR (Event Video Retrieval) 를 위한 데이터셋
- It consists of 2,375 videos, and 620 queries.
ActivityNet
- AVR (Action Video Retrieval) task 를 위한 데이터셋.
- It consists of 3,791 training, 444 validation and 494 test videos.
Experiments
- frame-to-frame similarity 비교
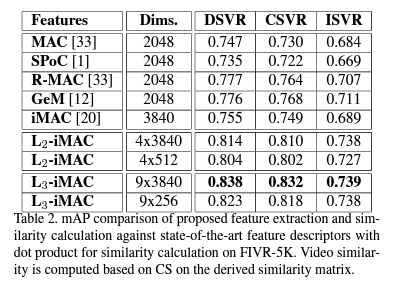
FIVR-5K dataset 에 대한 결과를 보면, L3-iMAC 이 가장 좋은 mAP를 달성했습니다. (concat 전과 후에, 3번째 feature map 의 channel axis에 \mathcal{l}^2-normalization 을 적용해준 겁니다)
2. Ablation study
ViSiL의 Video retrieval 에 대한 성능을 각 모듈 별로 평가해봤습니다.
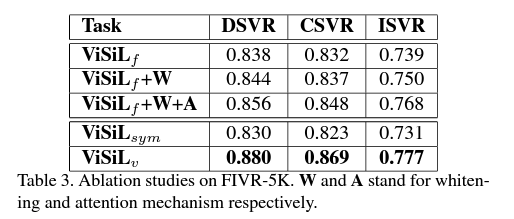
FIVR-5K dataset 에 대해 평가했고, ViSiL 에게 4가지의 configuration settings 를 적용한 결과 입니다. 위에 있는 3개를 보면, 각 component 를 추가할 때 마다 성능이 올랐음을 알 수 있습니다.
아래 2개를 비교했을 때, 이 문제에서는 CS의 non symetric 한 버전이 더 나은 것을 알 수 있었습니다.
Similarity regularization loss 의 impact 에 대해서도 평가해봤습니다.
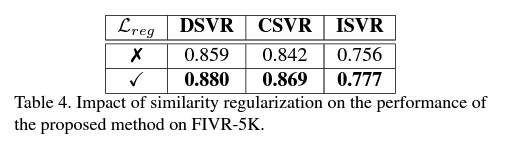
retrieval 의 performance 에 영향을 미친다는 것을 알 수 있었는데요. 사용할 때 모든 tasks 에서 성능향상이 있음을 알 수 있었습니다.
3. state-of-the-art 와의 비교
- CC_WEB_VIDEO 데이터셋을 사용한 NVDR 문제에서 성능을 비교해봤습니다.
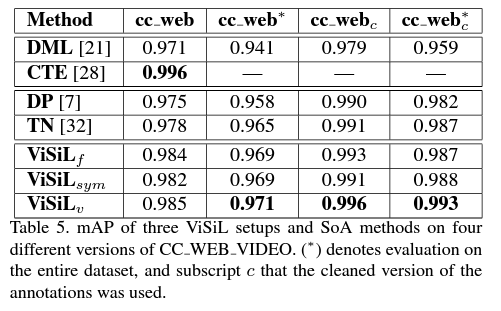
original annotations 이 사용된 CTE 를 제외하고는, 다른 경쟁 시스템들과 비교했을 때 가장 좋은 성능을 냈습니다. 아 위에서도 말했듯이 annotations 에 에러가 많아서 그렇다고 하는데요, 이 논문에서 제시한 ‘cleaned version’ 의 annotations 을 사용하여 테스트 했을 때 (*) 0.993으로, CTE와 0.003 밖에 차이나지 않음을 알 수 있었습니다.
- FIVR 데이터셋을 사용한 DSVR 문제에서 성능을 비교해봤습니다.
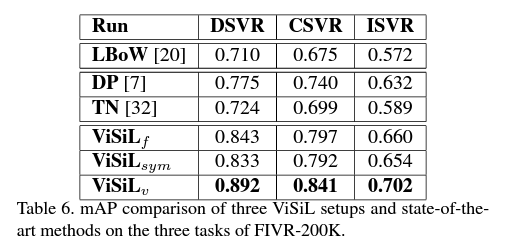
Table 6. 을 보면 알 수 있듯이. ViSiL_v 가 가장 좋은 성능을 냈습니다.
잘못된 경우를 수동으로 검사해봤더니, 실제로 positive 여야 하는데 라벨이 제대로 붙지 않은 경우가 있었다고 합니다.

원래대로였으면 positive 라고 label 되어야했기 때문에, Table 의 성능이 실제와 조금 다를 수 있다는 의미로 보여준 것 같습니다.
- EVVE 데이터셋을 사용한 EVR 문제에서 성능을 비교해봤습니다.
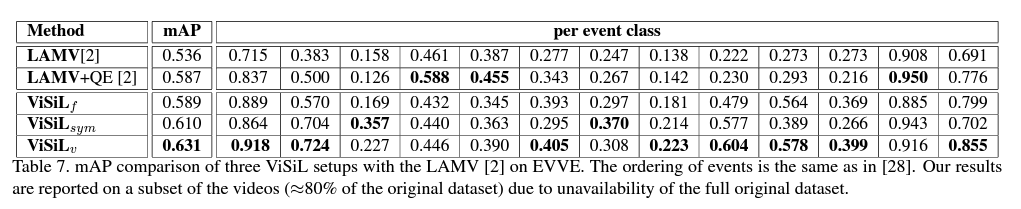
ViSiL_v 가 대다수의 이벤트에서 가장 좋은 결과를 냈음을 알 수 있습니다. 참고로, original EVVE dataset 중에 더 이상 사용할 수 없는 비디오들도 있었기에, 이 결과는 데이터셋의 80%를 사용한 결과입니다.
- ActivityNet 데이터셋을 사용한 AVR 문제에서 성능을 비교해봤습니다.

ViSiL_sym 이 다른 접근방식들과 비교했을 때 큰 차이로 성능이 좋은 것을 알 수 있습니다.
Conclusion
본 논문에서는, 비디오 간의 similarity 를 계산하는 방법을 학습하는 네트워크인 ViSiL을 제안했습니다.
ViSiL의 key contribution 은 아래와 같습니다.
- regional level 의 유사성을 capture 하는 frame-to-frame 유사도 계산 방법 제안
- video segments 사이의 frame-to-frame 유사도 matrix 를 분석하는 supervised video-to-video similarity 계산 전략 제안
이 두 개를 합쳐서, video similarity 의 fine-grained 시공간적 유사성을 고려하는 video similarity 계산 방식을 이끌어 낼 수 있었습니다. 이를 이용한 ViSiL을 컨텐츠 기반 retrieval 문제들에 적용해 보았더니 SOTA를 갱신했습니다. 논문 저자가 말하길, 추후에는 계산 복잡도도 줄이고, 제안한 방법을 video retrieval 뿐만 아닌 다른 분야에도 적용시키고 싶다고 합니다.
+ 처음에 딱 봤을 때 모르는 말들이 너무 많았는데, 이 논문을 읽으면서 Video retrieval 라는 것에 대한 기반지식을 어느 정도 쌓을 수 있었습니다. 어떤 tasks이 있고, 각 taks에 대해 어떤 데이터셋을 사용하는지도 알게 됐습니다. 그리고 자세히 알아보지는 못했지만 related works 부분을 읽으면서 이런 흐름이 있었구나~도 조금이나마 파악할 수 있었습니다.
논문 링크
ViSiL: Fine-Grained Spatio-Temporal Video Similarity Learning
CS로 계산된 frame-level의 similarity map에서 max -> mean 연산을 하는 과정은 어떤 의미를 지니는가요? max->max, mean->max, mean->mean을 사용하지 않은 다른 이유가 있을까요?
그리고 html tag는 먹히지 않으니 빼면 좋을 듯합니다..! 중간에 글 읽기가 조금 힘드네요..ㅎ
max->mean은 두 프레임의 region vecor 간의 dot product 가 주어졌을 때, max를 통해 두 프레임이 가장 일치하는 곳의 유사도들을 알아낼 수 있고, 이를 mean 해서 두 프레임 간의 평균적인 유사도를 알 수 있습니다. region vector product 를 사용했으므로, 두 프레임의 공간적인 관계를 잘 나타내는 유사도를 알아낼 수 있다는 의미를 갖고 있습니다.
다른 방식을 사용한다면 mean -> max 에 비해 두 프레임의 관계를 충분히 나타내지 못하게 됩니다.
max->max 는 두 프레임의 한 곳에서만 비슷하고 나머지는 아예 다르더라도 유사도를 높게 측정하게 됩니다.
mean->max 는 두 프레임의 실제 유사도가 높더라도, 프레임이 전체적으로 비슷하지 않으면 유사도를 작게 측정하게 됩니다. 비슷하지 않은 부분의 유사도까지 고려해야 되기 때문입니다. 이는 mean->mean 도 마찬가지 입니다.
답변이 많이 늦었네요…! ? 태그는 알려주신 방법으로 수정했습니다. 감사합니다!