제가 이번에 정리한 리뷰는 data augmentation과 관련된 논문입니다. 본 논문은 농업에서 instance segmentation을 학습하기 위해 데이터 증강 방법이 필요함을 이야기 하고 자연스러운 data augmentation을 제안하였다고 합니다.
본 논문은 농업의 자동화를 위해 자동으로 잎의 수를 세고 영역을 분할하는 분석 과정이 필요하고 이를 위해 instance segmentation을 적용했습니다. 학습을 위해서는 많은 데이터가 필요하지만 식물의 다양성과 성장 시기, 온도 변화 및 표현형의 다양성 등에 의해 라벨링 된 데이터를 얻기 힘들고, 이 논문은 객체의 기하학적 구조를 유지하여 실제 상황의 식물과 유사하도록 하는 방식을 제안합니다.
Method
기본적으로 콜라주라는 합성 데이터 생성 방식을 이용합니다. 투명한 배경에 수동 혹은 자동으로 어노테이션 한 단일 잎을 붙여 랜덤한 값의 변화(transform)를 주고 다른 배경에 붙여넣습니다. 이때 나아간 방식으로 객체간의 논리-의미론적 관계를 계산합니다. 기본적인 방식을 naive collage, 발전된 방식을 structured collage라 하겠습니다. naive collage는 최소한의 데이터와 annotations을 모을 수 있고 일부 예측이 가능한 “야생 환경”을 위해 고안되었습니다. 그리고 structured collage는 측정 가능한 현상과 상관이 있다고 추측되거나 알려진 특정한 식물의 구조적 특성을 이용합니다.
1. Naive collage
naive collage 방식은 간단히 객체 인스턴스들을 이용하여 배경 이미지에 임의의 위치에 임의의 변환을 거쳐 붙여넣는 것을 의미합니다.
이 방식은 이전에 분할된 객체를 이용하여 투명한 배경에 붙이고 논리적-의미론적 관계를 고려하지 않고 선택된 배경에 위치를 정합니다. 우선 비교적 간단한 시나리오에서 진행하였습니다. 3000×4000 pixel의 해상도의 아보카도 이미지와 보이는 잎에 대한 annotation 정보를 가진 데이터에 대해 진행하였습니다.
원본 이미지에서 (1) 크기 (2) 다른 객체에 가려지졌는지 (3) 깨끗하고 초점이 맞았는지를 기준으로 하여 만족하는 적절한 이미지로부터 잎을 추출하여 약 200개의 잎으로 set을 구성하였습니다. 이때 생성된 이미지가 최대한 진짜같도록 하기 위해 가려진 이미지를 제외하고 선명한 윤곽을 가진 잎만을 검출하기 위해 작고 흐릿한 잎은 모두 제거합니다. 마스킹된 잎은 비율을 유지하여 수십개의 잎을 콜라주하여 1024×1024의 이미지를 만듭니다. 이때 배경은 아보카도 잎이 선명하지 않은 실제 농장 배경을 이용하고 잎은 10~40개를 랜덤으로 선택해 회전과 크기 조정을 한 뒤 객체의 중심이 배경 이미지 안에 존재하도록 하여 이미지를 생성합니다.
2. Structured Collage
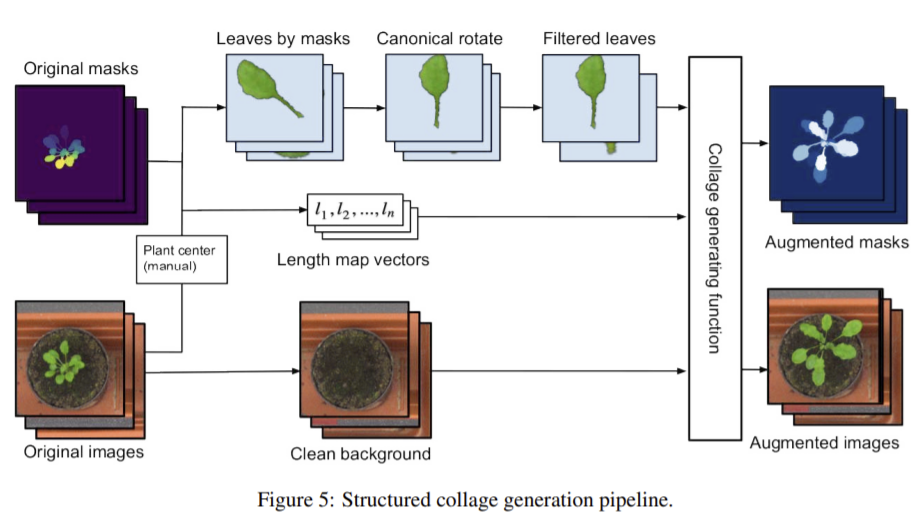
structured 방식은 잎이 전체 식물의 일부로서 위치, 크기, 형태에 대한 논리적 순서, 구조, 계층관계를 고려합니다. 즉 적절한 배경에 표준형태로 정렬된 잎을 만들고 잎을 이미지에 논리적으로 붙이는 것으로 Figure 5의 방식으로 이뤄집니다.
배경
원본 이미지에 heal-selection filter를 이용하여 식물 부분을 제거한 배경 이미지를 생성합니다.

표준 형태의 잎
이미지에서 뽑아낸 객체들을 식물의 중심 부분이 아래로 오도록 회전시켜 정렬한 뒤 (1) 잎 마스크가 하나의 잎으로 이뤄졌는지 (2) 잎이 식물 중심에서 일정 수준 이상 떨어지지 않았는지 (3) 최소한의 겹침만 있어 거의 완전한 잎의 형태를 갖췄는지를 기준으로 걸러냅니다. 이때 겹친 부분이 있어 걸러진 잎들도 데이터 생성에서 사용됩니다.
합성 이미지 생성
(1) 식물이 화분 중심 근처 지점에서부터 뻗어나오고 (2) 모든 잎이 그 지점에서 자라고 (3) 잎의 크기와 중심부터의 거리가 관계가 있고 (4) 잎은 일정한 분포가 있다는 경험적 지식을 바탕으로 식물의 구조를 모방하여 이미지를 만듭니다.
잎의 길이를 내림차순으로 정렬하여 각 이미지에 대해 Length Mapping Vector를 정의합니다. 그리고 다음의 순서에 따라 이미지를 생성합니다.
- 배경 이미지 리스트에서 임의로 이미지 선택
- 영상 중심에서 최대값(식물이 존재할 수 있는) 까지 식물 중심 좌표를 무작위로 선택
- length mapping vector를 임의로 선택
- 첫번째 잎을 임의의 각도로 회전시켜 붙이고 비슷한 크기의(±3 픽셀) 잎을 선택함
- 각 추가 잎 마다
– 정렬된 식물에서 length mapping vector에 근접한 길이를 가진 잎을 선택
– 이전에 추가된 잎을 기준으로 각도를 선택해 붙임
rosette dataset에 의하면 연속된 잎 사이에는 120°정도의 각도가 있으므로 다음 식물을 α_{i}=α_{i-1}+125°±10°의 각도로 회전시킵니다.
Result
COCO 데이터셋으로 사전학습된 Mask R-CNN를 이용했습니다.
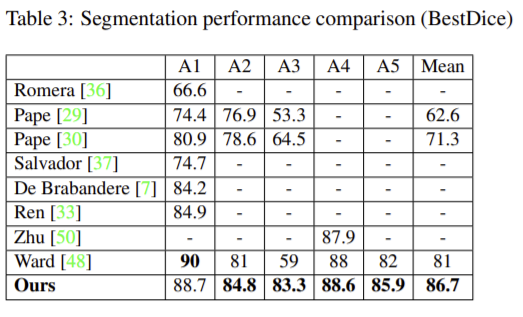
** 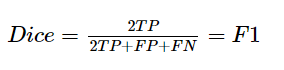 참고
참고

정량적 결과의 경우 대부분의 방식에 대한 비교는 A1에서 가능한데 최고 성능이 아니고 나머지 카테고리와 평균에 대한 성능 비교도 많이 비어있어 좋은 결과를 냈다고 할 수 있는지는 잘 모르겠습니다…
굉장히 세부적인 상황에서의 augmentation방식이라 이를 다른 task에 적용하기 위해서는 참고하기 좋은 내용이라 보기는 어렵다고 생각됩니다. 원하는 instance segmentation 학습을 위한 데이터 증강 방식은 식물 전체를 이용하는 것이라 각각의 잎을 하나의 중심에 모이도록 데이터를 생성하는 방식은 저희의 data augmentation 방식에 적용하기는 어려울 것 같습니다.