저번주에 리뷰한 Facial Landmark Detection 서베이 논문의 경우 대개 2D 기반의 방법론들이 대부분이어서 서베이에서 소개한 방법론이 아닌, 이번에는 3D Landmark 를 추출하는 논문을 읽어보았습니다.
[논문 바로가기] Face Alignment Across Large Poses: A 3D Solution

Face Landmark Detection 은 얼굴의 상징점인 눈, 코, 턱 등의 위치를 찾는 방법으로 face recognition, expression recognition, inverse rendering 등과 같은 얼굴 관련 태스크의 필수적인 전처리 과정으로 매우 중요한 단계입니다. 기존에는 얼굴 영상을 정면으로 한정 짓고, 2D Landmark 를 추출하여 성능을 제한적으로 향상시켜왔지만, Large Pose로 인한 Occlusion/Lighting 등과 같은 Wild한 이미지에 대해 한계가 있었습니다. 본격적인 리뷰에 앞서, 논문의 제목과 상단 그림에서도 예측해볼 수 있듯, 해당 논문은 Large Pose 에서도 강인하게 랜드마크를 찾는 방법론을 제시합니다. 이때, Large Pose 란 상단 그림처럼 정면이 아닌 90도나 돌아간 옆모습과 같이 정면을 기준으로 돌아간 각도(정도) 로 이해하시면 좋을 것 같습니다.
논문에서 언급하는 90 도 안팎의 큰 pose 에 대한 Face Landmark Detection 의 3가지 Challenges 는 다음과 같습니다.
- Modeling 의 어려움. 45도 이하의 Pose 에서는 어느정도 눈,코,입이 다 보이기 때문에 모델링이 상대적으로 어렵지않고 탐지 성능역시 좋은 편입니다만, Large-Pose (90도 안팎)로 인한 Occlusion(예를 들어 옆면은 얼굴의 반쪽이 안보임)은 모델링을 어렵게하는 요소 중 하나입니다.
- Large-Pose 가 될 수록 얼굴의 외형적인 모습이 크게 변하는데, 기존 모델은 이런 복잡한 패턴을 일관된 방식으로 처리할 수 있을 정도로 정교하지 않다는 한계가 있습니다. 따라서 일정 View(Pose) 로 나누어 각 View 에 대한 랜드마크를 계산하고 처리해야하기 때문에 복잡하고 Cost 가 커집니다.
- Data Labelling 의 부족 및 신뢰도. 이 부분은 저번주 리뷰에도 언급된 3D Landmark 추출 연구의 치명적인 단점입니다. Large-Pose 의 경우, Occlusion 이 크게 발생하기 때문에 안보이는 부분은 추측하여 Labeling 을 해야하기 때문에 신뢰도 측면에서 한계가 존재합니다.
따라서 이 세 가지 Challenges 를 극복하고자 본 논문의 contribution은 다음과 같습니다.
Contribution
- fit the 3D dense face model rather than the sparse landmark shape model to the image
- Large-Pose 로 인한 Occlusion에 대비하여 3D Dense Face Model을 이미지에 맞춥니다.
- a cascaded convolutional neutral network (CNN) based regression method to resolve the fitting process
- 여러 뷰 별로 처리해야한다는 부담을 줄이기 위해 회귀기반 Cascaded CNN을 제안합니다.
- construct a face database containing pairs of 2D face images and 3D face models
- 2D facial images 와 3D Facial Model의 pair을 포함하는 얼굴 데이터베이스를 구축합니다.
- 또한 60k 이상의 traing sample을 Large-Pose에 걸쳐 합성하기 위한 얼굴 프로파일링 알고리즘을 제안합니다.
3D Dense Face Alignment (3DDFA)
(1) 3D Morphable Model (3D 변형 가능한 모델)
먼저 PCA와 함께 얼굴 Space를 표현할 수 있는 3D Morphable Model (3DMM) 을 사용합니다. (3DMM을 마스크라고 생각하면 이해가 좋을 것 같네요!)
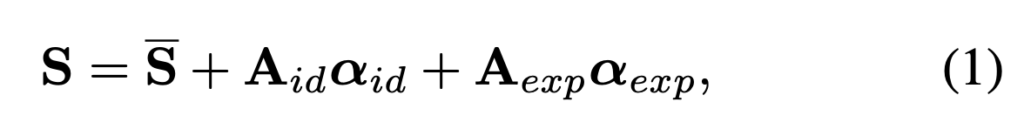
- S : a 3D face
- S : the mean shape
- A_{id} : the principle axes trained on the 3D face scans with neutral expression
- α_{id} : the shape parameter
- A_{exp} : the principle
axes trained on the offsets between expression scans and neutral scans - α_{exp} : the expression parameter.
위의 수식을 이용하여 3D Face 를 구하고나서, 이제 Weak Perspective Projection 을 사용하여 Image Plane 으로 Projection 시킵니다.
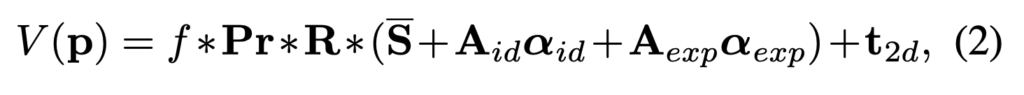
- V(p) : the model construction and projection function, leading to the 2D positions of model vertexes
- f : the scale factor
- Pr : the orthographic projection matrix \begin{pmatrix}1 & 0& 0\\0 & 0 & 1\end{pmatrix}
- R : the rotation matrix constructed from rotation angles pitch, yaw, roll
- t_{2d} : the translation
vector. - The collection of all the model parameters : p = [f, pitch, yaw, roll, t_{2d}, α_{id}, α_{exp}]^T
(2) Network Structure (네트워크 구조)
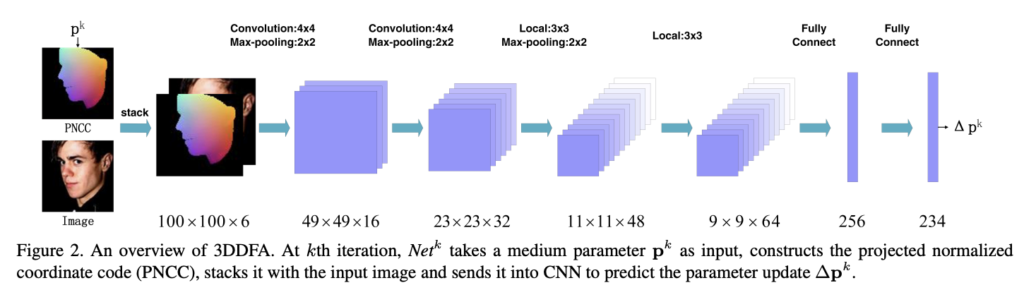
Face Landmark Detection의 목적은 단일 얼굴 영상 I에서 p를 추정하는 것입니다. 따라서 3DDFA에서는 여러 뷰를 통합할 수 있도록 cascaded-CNN을 네트워크로 사용합니다. 매 iteration 마다 초기 파라미터 p_k가 주어졌을 때,p_k로 설계된 특징 projected normalized coordinate code (PNCC) 를 구성하고 파라미터 업데이트(∆p_k)를 예측하기 위해 convolutional neutral network인 Net_k를 학습시킵니다.
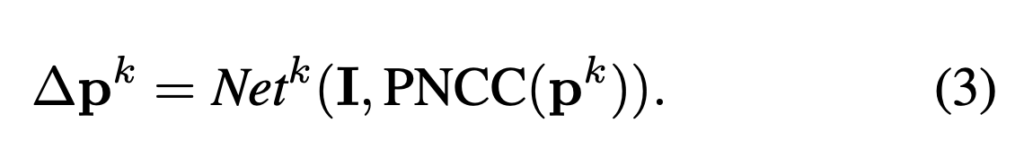
이후, 다음 파라미터 p^{k+1} = p^k + ∆p^k는 Net^k와 동일한 구조를 가진 다음 네트워크 Net^{k+1}의 입력이 됩니다.
지금까지 내용을 하단에 첨부한 그림을 통해 정리하도록 하겠습니다. 입력은 PNCC에 의해 쌓인 100 × 100 × 3 RGB 이미지입니다. 네트워크에는 4개의 Convolution Layer, 3개의 Pooling Layer 및 2개의 FC Layer이 있습니다. 처음 두 개의 컨볼루션 레이어는 가중치를 공유하여 low-level feature를 추출합니다. 마지막 두 컨볼루션 레이어는 location sensitive features를 추출하기 위해 가중치를 공유하지 않으며, 이는 256차원 형상 벡터로 regressed 됩니다. 출력은 6차원 Pose parameter 인 [f, pitch, yaw, roll, t_{2dx}, t_{2dy}], 199차원 shape parameter인 α_{id}, 그리고 29차원 expression parameter α_{exp}를 포함한 234차원 parameter update 입니다.
Experiments
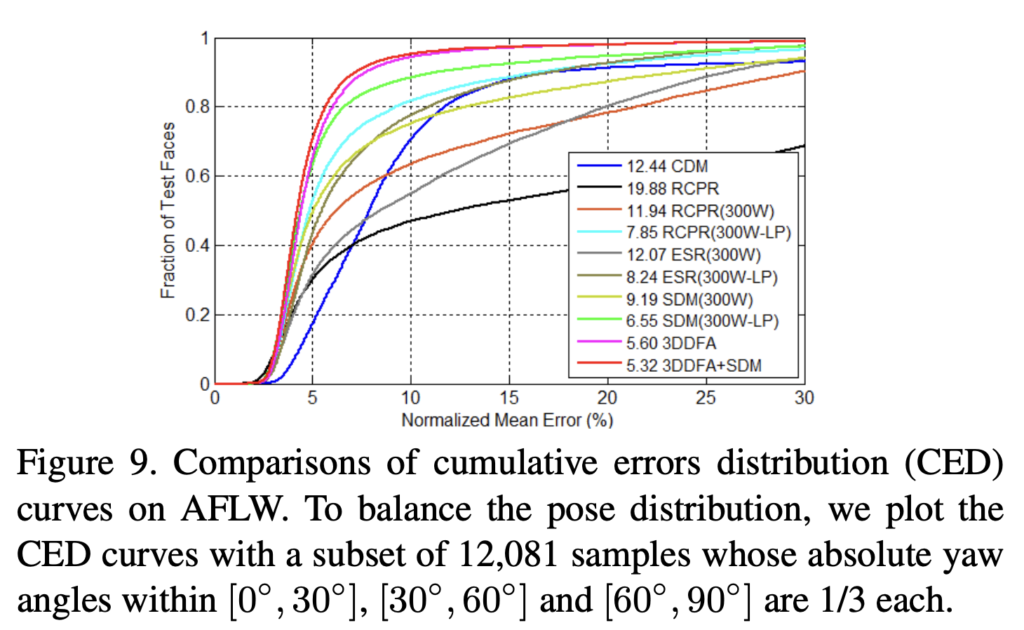
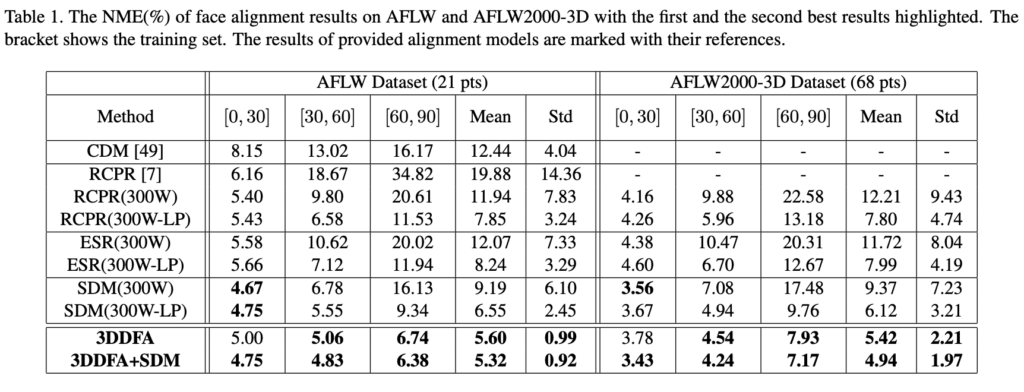
아래 실험을 통해 3DDFA는 특히 중간 포즈를 넘어 모든 2D 방법보다 SOTA임을 보입니다. 또한 3DDFA의 최소 표준 편차는 변화를 일으킬 수 있는 견고성을 확인할 수 있엇습니다. 특히 AFLW, AFLW2000-3D 및 300W에서 SOTA를 달성하였습니다.

리뷰 잘 읽었습니다!
궁금한 점이 있어 댓글 남깁니다. 해당 모델에서 처음 두개 레이어는 가중치를 공유하고, 마지막 레이어에서는 가중치를 공유하지 않아서 location sensitive 한 feature를 얻을 수 있다는데, 반대로 하면 (처음 공유 안하고 마지막 공유하기) 그러한 feature 를 못 얻는건가요? 그렇다면 왜 그렇게 되는지도 질문합니다…!