두번째 리뷰입니다. 원래는… 원복까지 진행해서 결과까지 올리는 것이 목표였지만, 이것저것 원복을 위해 준비해야하는 파일들이 많아서 이번주에는 리뷰만 올리는 것으로… 하였습니다.
이 논문은 비디오와 비디오의 시공간적 관계를 고려해서 비디오의 유사도를 평가해주는 내용을 담고있습니다. 논문의 제목에 있는 ViSiL이라는 이름은 저자들이 제안한 프레임워크 Video Similarity Learning architecture의 축약어입니다.
Introduction
본 논문에서는 비디오 쌍의 유사도 추정 문제를 다룹니다. 기존의 방법론들에 대한 설명도 논문에는 포함되어 있지만, 여기서는 패스하고 결론만 말씀드리면, 비디오 유사도 측정 부분에서 시공간적 정보를 활용하는 방향으로 꾸준히 발전이 이루어져 왔고, retrieval 이외의 분야에서는 이러한 부분을 활용해서 성능이 잘 나왔기 떄문에, retrieval 분야에서도 시공간적 정보를 활용하는 방향으로 발전이 필요하다는 점을 말하고 있습니다. 그래서 해당 논문에서는 시각적 유사성의 공간(intra-프레임)과 시간(inter-프레임) 구조를 모두 고려하는 비디오 유사성 학습 네트워크(ViSiL)을 제안합니다.
Preliminaries
이 논문에서 흔하게 등장하는 개념 두가지에 대한 설명을 미리 해줍니다.
Tensor Dot (TD)
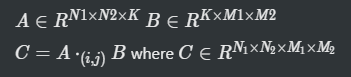
A와 B를 특정 축으로 더해주는 연산. Dot product라는 표현도 나오는데, 이는 스칼라 곱이라고 합니다. 어차피 이 값이 유클리드 공간의 내적이라 내적이라고도 부른다고 합니다.
Chamfer Similarity (CS)
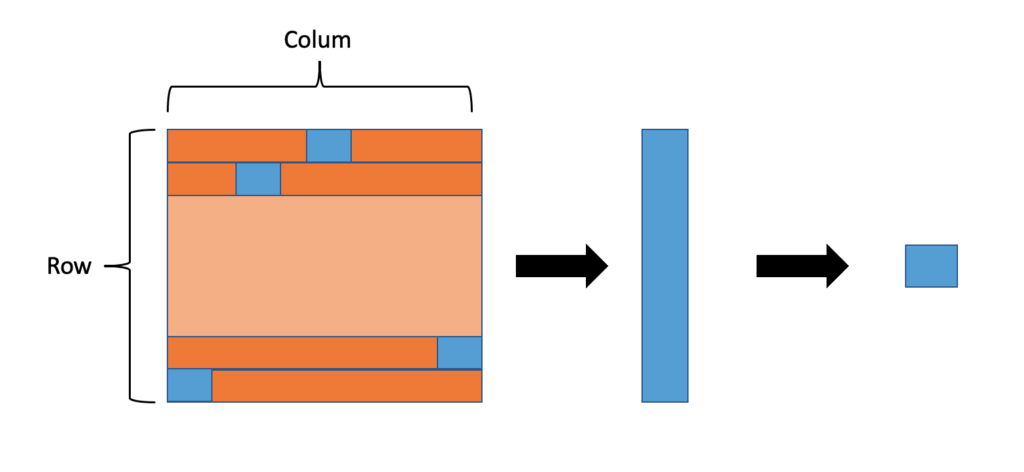
근택님의 x-review에 그려진 그림을 보니 수식이 딱 이해가 가서 그림을 발췌해왔습니다. Chamfer similarity는 similarity matix의 row&column의 row에서 최대값을 하나씩 뽑아 만든 1D vector의 평균값을 낸 값이라고 합니다. 논문에서는 이제 SCS라는 것도 만들어서 실험하는데, ablation study로 많이 하는 방식이라고 합니다. 이 논문에서 SCS는 딱히 좋은 성능이 나오지는 않았습니다.
ViSil description
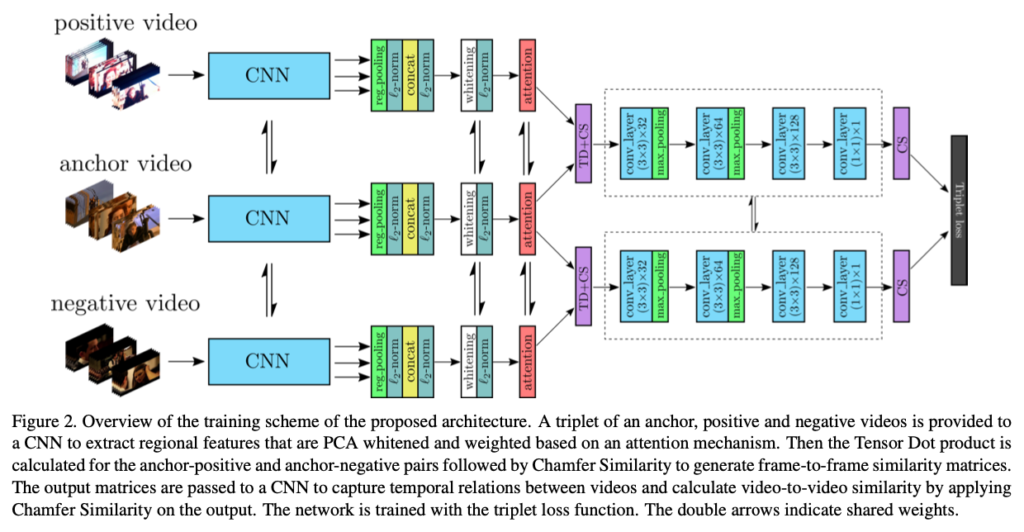
ViSiL은 위와 같은 구조로 학습을 합니다.
1. Feature extraction
그림에서 attention이라고 적힌 빨간 블럭까지의 부분인데, 코드를 보면 백본은 Resnet50을 사용하는 것을 알 수 있습니다. 주목할만한 부분은 R-MAC이라는 방법을 이용해서 feature map을 뽑는다는 것입니다. R-MAC과 같은 방법을 이용하면, 추출된 frame feature들이 프레임의 공간 정보를 서로 다른 세분도로 유지할 수 있기 때문이 이런 방법을 사용한다고 합니다.
그 다음으로는 whitening이라는 과정을 거치는데, 논문에서는 PCA를 사용했다고 합니다. 그리고 attention을 주는 부분이 있는데. 이건 whitening을 하고 L2 norm을 해줌으로서 생기는 문제를 해결하기 위해 거칩니다. 이렇게 정규화를 해주면 검은색 영역과 같이 의미가 없는 부분도 의미가 있는 부분과 같은 수치(영향력)을 가지는 문제가 발생하기 때문에 visual attention mechanism을 이용해서 돌출부에 weight를 주는 방식으로 이 문제를 해결했다고 합니다.
2. Frame-to-frame similarity
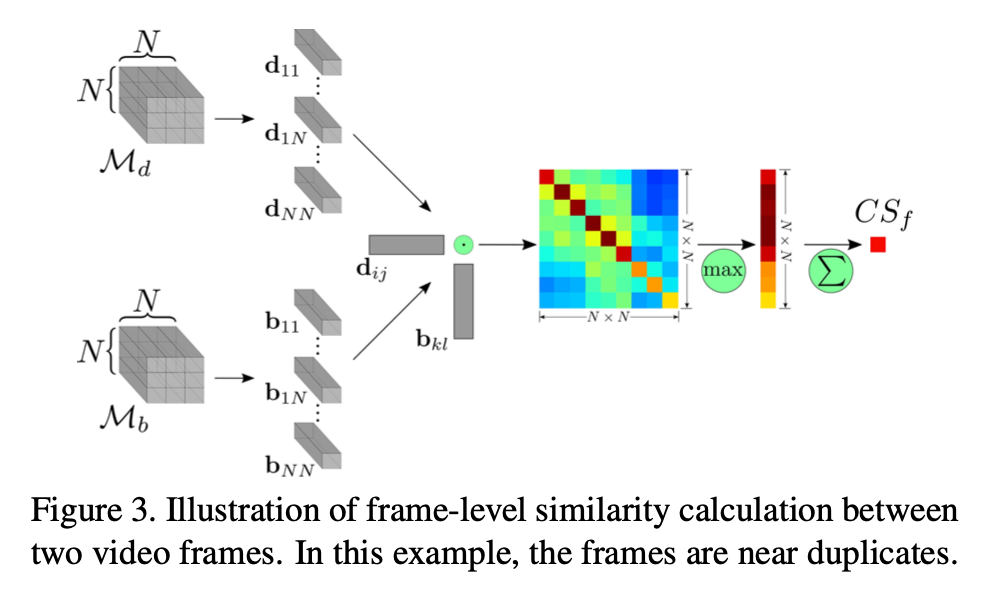
두 프레임이 주어지면 위의 그림과 같이 frame level의 similarity를 구할 수 있습니다. 이 부분이 Figure 2의 보라색 TD+CS가 해당 부분을 의미합니다. 프레임끼리 TD 연산을 수행해주고 CS 연산을 해서 frame-level similarity matrix를 취합해줍니다.
3. Video-to-video similarity
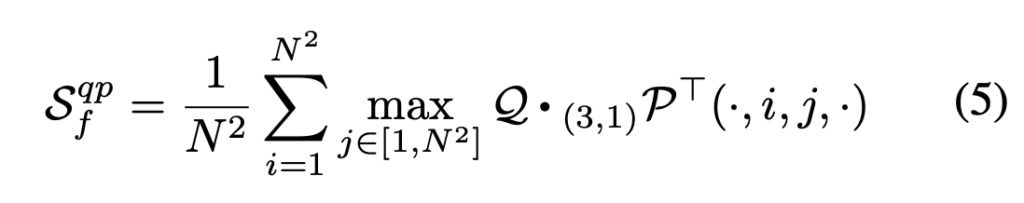
논문의 2번(CS)과 1번 수식(TD)을 결합하면 위의 수식이 나옵니다. video tensor Q와 P를 통해 비디오와 비디오의 유사도를 계산할 수 있습니다. 비디오는 프레임들의 집합이라, Frame-to-frame similarity에서 알아본 과정을 모든 프레임마다 적용해주면 similarity matrix를 알 수 있습니다. 이 값을 Figure 2의 점선 박스 부분에 던져줍니다.
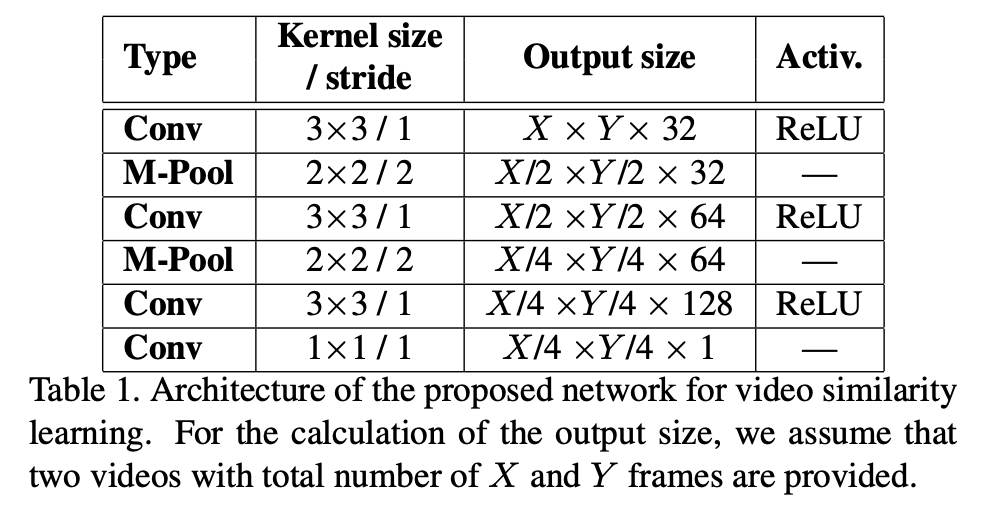
던져진 값은 위와 같은 학습과정을 거칩니다. 이러면 segment level에서 비디오 유사성 패턴을 학습할 수 있게됩니다.
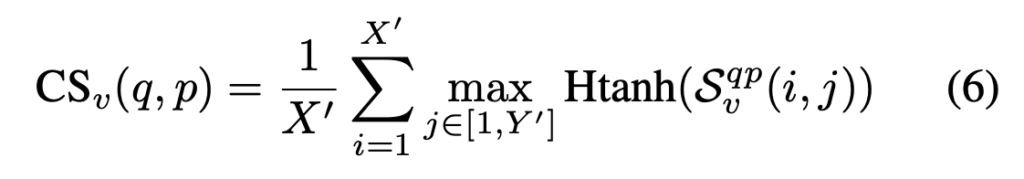
최종적인 비디오 유사도는 네트워크의 결과값 hard tanh activation을 취해주면 됩니다.
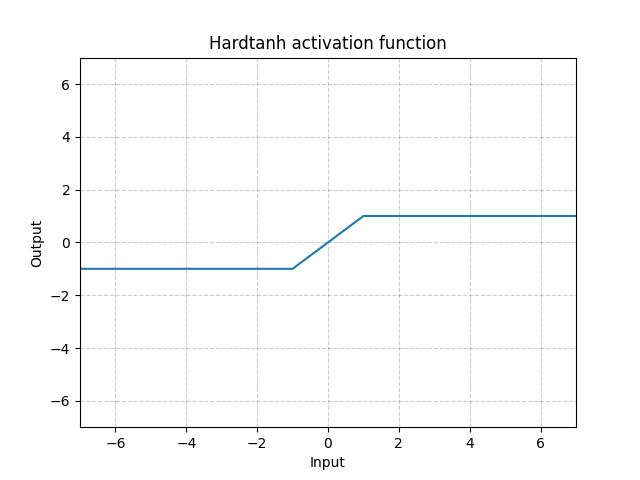
참고로 hard tanh activation은 위와 같습니다.
Loss function
Loss는 두가지 Loss를 합쳐 total Loss로 사용합니다.
triplet loss
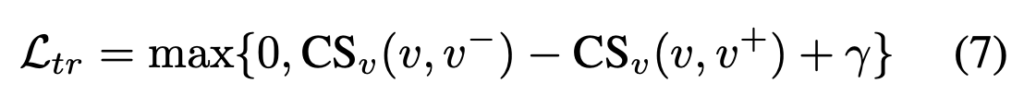
일반적인 tripet loss랑 똑같은 구조로 사용합니다.
regularization loss
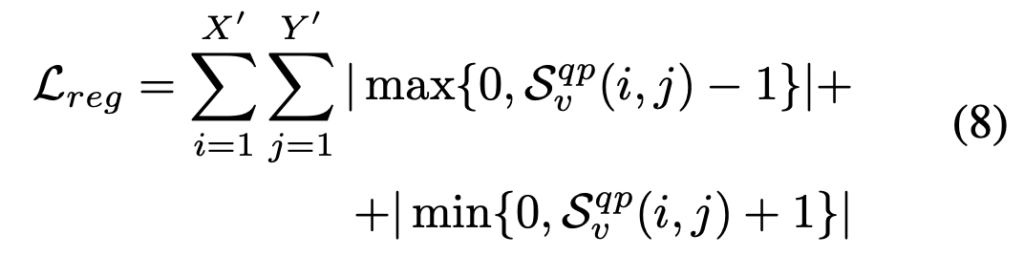
regularization loss는 Sv(frame to frame simillarity matrix 위에서 도출한 수식)가 hard tanh를 통해 [-1, 1] 사이의 값이 나오도록 정규화합니다.
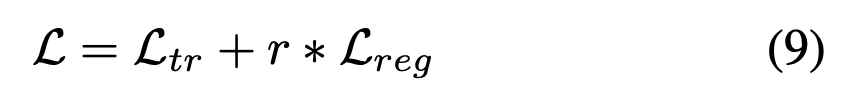
r은 regularization hyperparameter로 사용합니다.
Training ViSiL
ViSiL을 학습하기 위해서는 segment level의 GT annotation이 필요합니다. 그리고 Triplet Loss에서 Anchor-Positive pairs 를 학습에서 사용합니다. 이 학습에 사용하는 positive set에는 3가지 변형(color, geometric, temporal)을 랜덤으로 적용해서 만듭니다.
그리고 Negative set을 위한 hard triplets을 만드는데, BoW를 이용해서 만들고 2가지 풀을 만듭니다.
- Pool1
- positive 비디오와 5초 이상 ovelap 되는 비디오를 골라야함.
- positive 비디오 셋의 세그먼트 중 하나가 유사도가 높아야함.
- Pool2
- 초기 비디오와 유사한 비디오(similarity > 0.1)는 hard negative
- near-duplicate를 피하기 위해 similarity가 0.5 이상인 비디오를 hard negative에서 제외
이런식으로 랜덤으로 선택하는 것이 아니라 위의 규칙에 맞는 학습 셋을 통해 학습을 했다고 합니다. 이 부분은 저자가 triplet.pk라는 파일에 annotation을 계산해서 넣어두었습니다.
Evaluation setup
학습은 VCDB 데이터셋을 사용하였고, CC WEB VIDEO, FIVR-200K, FIVR-5K, EVVE, ActivityNet 등의 데이터셋을 NDVR, FIVR, EVR, AVR 등의 문제를 해결하는데 사용하였습니다.
Experiments
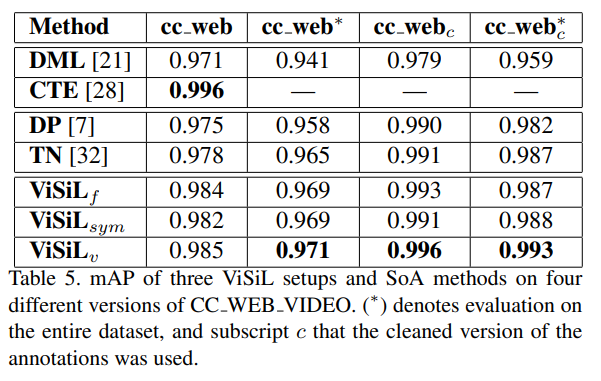

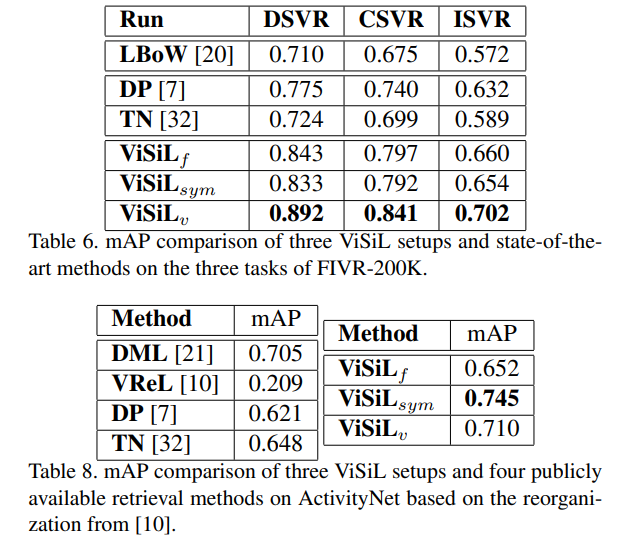
다양한 데이터셋과 다양한 task에서 성능이 다 좋은 것을 확인할 수 있었습니다.
리뷰 잘 읽었습니다.
질문은 feature extraction 부분에서 attention을 진행하는 이유와 어떻게 처리가 되는 지 물어보고 싶네요. 저는 사실 이 부분이 논문에서 읽을 때 이해가 안가서 코드 부분도 살펴봤던 기억이 납니다.
논문만 보면 구체적인 내용들이 잘 들어오지 않을 수 있습니다. Code도 자세히 살펴보고 있는것으로 알고 있는데 , 디버깅을 통해서 내용 이해에 부족했던 부분을 채워나가고 원복에 성공하셨으면 좋겠습니다!
맞습니다. 논문에서 이렇게 했다는 부분을 코드에서 맞춰보려니 tensorflow를 처음 봐서 그런지 몰라도 잘 이해가 안되더라고요. VCDB 데이터셋을 다운받고 있으니 디버깅 하면서 이해해보려고 합니다!
attention을 주는 이유는 정규화를 수행하고 나면, 의미 있는 영역과 의미 없는 영역이 유사도에서 같은 영향력을 가지게 되기 때문에 준다고 합니다. 이를 위해 visual context unit vector “u”라는 값을 이용하는데, 댓글에는 이미지를 어떻게 다는지 모르겠어서… 수식을 달지는 못하지만 수식을 보면, u를 이용해 새로운 weight를 만들고 이 weight를 이용해 새로운 region vector를 만드는 식으로 사용합니다.
이 u값이 학습된다고 해서 근택님처럼 코드상에서 찾아보려고 했는데, 아직은 어딘지 못찾았습니다. 디버깅 하면서 이것도 찾아보도록 하겠습니다!